Последната
актуализация
на този
раздел е от 2019
година.
4.2.2.
Полупроводникови
динамични
памети. Продължение.
DRAM, SDRAM,
SDR, DDR, DDR2, DDR3, DDR4,
DDR5
Технология
Xn-Prefetch. Използване
на парафазен
(диференциален)
тактов
сигнал.
Умножаване
на
честотата.
Особености
в структурата
на
входно-изходния
буфер на SDRAM
Уважаеми
читатели,
включваме
този раздел в
цялостното
съдържание
на тази
глава, тъй като
представеното
в него има
съществено значение
за
задълбоченото
изучаване на
логическата
структура на
динамичните
памети, както
и на тяхното
функциониране.
Неговото
място е точно
тук, тъй като
изложението
навлиза в представянето
на новите и
на бъдещите SDRAM, за които
този въпрос е
много важен.
Причините
той да бъде
разгледан и
вмъкнат тук, се
коренят
най-вече в
отсъствието
в публичното
пространство
на
необходимите
пояснения
относно
проблемите,
свързани с
реализацията
на темата,
обявена в
горното
заглавие.
Същността
на темата
касае
входно-изходния
буфер на
съвременните
динамични
памети. По-долу
ще бъдат
представени
решения,
необходими
за нейното
по-пълно
изясняване.
Най-напред ще
се спрем на
изказването “превключване
по двата
фронта –
преден и заден"
на тактовата
последователност.
Това натрапчиво
изказване в
много
публикации е
свързано с
пояснения,
относно
методите за
повишаване
на пропускателната
способност
на динамичната
памет и цели
да поясни
функционирането
на
входно-изходния
буфер. Ние
също го употребихме
когато
представяхме
паметите от тип
DDR.
Литературните
обяснения за
двойния трансфер
в рамките на
един такт,
както и
изказването
"превключване
по два фронта",
не са съвсем
коректни,
което и
налага нашите
обяснения.
Стремежът
към по-висока
производителност
е довел
дизайнерите
до идеята да
предават 2
пъти повече
порции данни
през
данновата шина
в рамките на
един период
на тактовата последователност
или кратко: “в
един такт". За
да обяснят
как на
практика
става това,
пак същите
дизайнери
въведоха
споменатото вече
изказване.
Тук е добре
читателят да
си спомни
фигура 4.2.2.15. Двойният
трансфер в
рамките на
един такт е
наречен "2n-Prefetch".
Същността на
този
механизъм
обаче на практика
не е добре
изяснен, ето
защо това ще
бъде нашата
задача тук.
Нека
разполагаме
с тактов
сигнал CLK
с определена
честота f, който има
коефициент
на запълване
(КЗ) 50%.
Последното
означава, че
в един период
на тактовата
последователност
двете логически
нива на
сигнала (0 и 1)
имат една и
съща продължителност.
При това
условие
всеки полутакт
дефинира
едно и също
време, за да
бъдат извършени
идентични
действия,
свързани с
последователния
трансфер на
двете порции
данни, т.е.
това условие
е гаранция,
че предаването
на нито една
от тях няма
да бъде ощетено
във времето.
И нека заедно
със сигнала CLK
разгледаме
сигнала на
неговата
инверсия not(CLK).
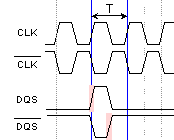
Фиг. 4.2.2.21.
Парафазна
тактова
последователност
(2 предни/задни
фронта в
период)
Горната
времедиаграма
изразява
графично
казаното
по-горе.
Контролерът
на паметта има
за задача,
използвайки
двете фази на
тактовата
последователност
CLK, да
формира
управляващите
строб-импулси
DQS и not(DQS) (Data Queue Strobe) така,
щото
управлението
да разполага
с два
положителни
фронта на
едно и също
разстояние
един от друг
в рамките на
един такт.
Обърнете
внимание на
факта, че
тези
фронтове не са
последователни
в рамките на
един и същи
сигнал, а са
фронтове на
два различни
сигнала.
Последното е
от
изключително
значение, тъй
като
позволява
тези два
фронта да се
подават по
две различни
линии, които
достигат две
различни
входно-изходни
шини, като ги
мултиплексират
(фигура 4.2.2.16).
Освен
мултиплексирането
на данновите
шини, тези
два фронта
управляват
фиксирането
на данни в
два различни
регистъра, с
обща входна
даннова шина.
Данните
пристигат по
общата
даннова шина
последователно
във времето,
т.е. в
различни
моменти (вижте
фигура 4.2.2.17).
Това може да
се види в
логическата
структура на DDR-паметта
от фигура 4.2.2.19.
Външният
ефект от описаната
организация
е като за
предаване на данни
с двойно
по-висока
честота.
Въпреки
че става дума
за трансфер с
удвоена
честота, в
казаното до
момента не
съществува
проблемът с
умножение на
честоти. Що
се отнася до формирането
на
споменатия
по-горе
единичен DQS импулс и
как той може
да бъде
постигнат с логически
средства,
читателят
може да намери
подробни
пояснения в раздел
8.1 на книга [3] или в
раздел
5.1.6 на книга [5].
Както ще видим по-нататък в този раздел, технологията хn-Prefetch се развива и се прилага във всички следващи поколения динамични памети, като 4n-Prefetch, или като 8n-Prefetch, или дори като 16n-Prefetch (при най-новите DDR5). Последните наименования означават, че в рамките на един период от тактовата честота на ядрото на паметта, върху изходната шина се изпълнява последователен трансфер на 4 или на 8 порции данни. Тези варианти на технологията хn-Prefetch обаче вече се прилагат в комбинация с технологията на умножените тактови честоти. Става дума за различно тактуване между ядрото на паметта и част от структурата на входно-изходния буфер. Например, ядрото на DDR2 се тактува с честота f, а буферът – с честота 2.f, което е пояснено на фигура 4.2.2.30 по-долу, или с честота 4.f, което е пояснено на фигура 4.2.2.36 по-нататък.
Ще обърнем внимание на още нещо, което отличава споменатите две технологии. Става дума за разбирането на това как съществуват формираните импулси топологично и във времето. Ще направим пояснението графично.
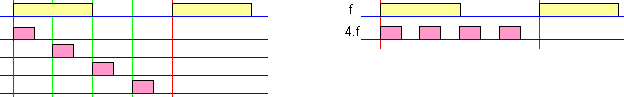
Фиг. 4.2.2.22.
Илюстрация
на смисъла на
технологиите
На
лявата
рисунка
по-горе се
виждат 4
импулса в
рамките на
един период,
но
разпространяващи
се по 4 различни
линии, което
съответства
на технологията
Prefetch.
Тук, както
родителският
сигнал, така
и четирите
производни
сигнала, са с
една и съща честота.
Изобразеното
на дясната
рисунка е съвсем
различно –
вижда се
тактова
последователност
с честота 4.f, разпространяваща
се по една
единствена
линия.
Ще поясним възможността за реализация на технологията Prefetch. Използвайки конюнкцията от сигнала In и неговата задържана във времето инверсия, в показаната по-долу логическа схема, получаваме сигнал Out, с всички желани от тази обработка ефекти.

Фиг. 4.2.2.23.
Детектор
на преден
фронт (пулс
генератор)
Ясно е, че чрез параметъра N (брой на последователно включените логически инвертори) може да се регулира ширината на единичния импулс Tout на изхода на логическата схема.
За да реализираме показания на фигура 4.2.2.22 ефект 4n-Prefetch, следва да имаме, освен основната тактова последователност CLK, още три нейни дефазирани (задържани) копия относно родителската последователност, съответно на ¼Т, на ½Т и на ¾Т. Така, прилагайки 4 схеми от вида, показан на фигура 4.2.2.23, ще имаме желаната последователност 4n-Prefetch.
Технологията с умножението на честота е свързана със значително по-специален проблем. Приложението на умножените честоти в контекста на динамичните памети е такова, че върху него ние налагаме допълнително изискването за 50% коефициент на запълване за всички честоти. Ще поясним как това може да се направи на практика.
Нека
имаме
правоъгълен
сигнал S с
честота f и
коефициент
на запълване
КЗ=50%, както и
негово
закъсняло (задържано
във времето)
копие S1.
Съвместното
положение на
тези два
сигнала е
показано на
следната
рисунка.

Фиг. 4.2.2.24.
Тактова
последователност
S с КЗ=50% и
нейното
задържано
копие S1
Закъснението
d
на сигнала S1
може да бъде
причинено
умишлено, при
това достатъчно
лесно с
подходящи
логически схеми.
Ако двата
сигнала са
аргументи на
логическата
функция
неравнозначност
(mod2, XOR),
то
резултатът
би бил
следният:
![]()

Фиг. 4.2.2.25.
Тактова
последователност
с честота 2.f
Както
лесно може да
се види,
честотата на
получения
сигнал S2 е 2
пъти
по-висока (fS2=2.f).
Коефициентът
му на
запълване
обаче не е 50%. За
да бъде
постигнато
това
допълнително
условие е
необходимо
закъснението
d на сигнал S1
спрямо
сигнал S, да
бъде 25% от
периода му (¼T).
Една
от
възможностите
за такова контролирано
закъснение
се състои в
използването
на така
наречените симетрични
фронт-детектори,
чиято реализация
е показан
по-долу.

Фиг. 4.2.2.26.
Delay-верига
като схема за
умножаване
на честотата
на
правоъгълен
сигнал
Както
се вижда от
логическата
схема, чрез параметъра
K
(брой на
последователно
включените
логически
инвертори)
може да се
регулира
закъснението,
или с други
думи,
продължителността
Tout
на
единичните
импулси.
Описаната
идея може да
се приложи
повторно
върху
допълнителното
закъснение
на сигнал S1,
което ще
означим S3 и
съответно
неговото
закъснение S4,
което се
постига с
аналогични
средства.
Използвайки
същата
логическа
функция ще
получим сигнал
S5.
Логическата
сума от
сигнал S2 и
сигнал S5 дава
сигнал S6.
![]()
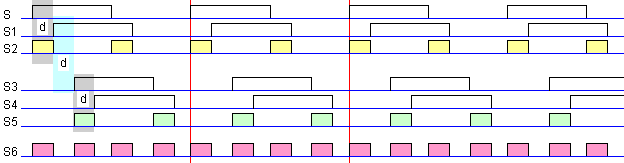
Фиг. 4.2.2.27.
Тактова
последователност
с честота 4.f
Казаното
до тук
осветлява
основната
идея за
получаване
на тактови
последователности
с по-високи
честоти.
Единственото
затруднение
и условие,
което тази
реализация среща,
е
равномерното
дефазиране
на основния
сигнал
(например на
¼Т, на ½Т, на ¾Т и
пр.). Този
проблем се
решава с
различни
средства –
логически и
електронни,
като се
достига до
цялостни
схемни
решения в
лицето на логически
схеми, които
са наречени DLL (Delay-Locked
Loop). Тези
схеми са
включени в
структурата
на динамичната
памет като
имат и допълнителни
функции,
свързани с
управлението
на
различните
режими за
трансфер на данни
(вижте
по-долу
фигура 4.2.2.37 и
фигура 4.2.2.40),
които бяха
пояснени в
предходния
раздел.
В научните публикации и в патентите читателят може да срещне и други технически решения, но тяхното подробно разглеждане тук излиза извън нашите интереси.
Ще
завършим с
това, че
технологията
хn-Prefetch
е свързана с
мултиплексирането
на данновите
шини, а
технологията
за
умножаване
на честотата
с
управлението
на FIFO-буферите.
Последните
представляват
своеобразни
конвейери за
трансфер на
блокове от
данни. Логическата
структура на
входно-изходните
буфери на
динамичните
памети са
достатъчно сложни
(вижте
примерите от
фигура 4.2.2.37 и
фигура 4.2.2.40). Те
съдържат
тези
логически
възли, тъй
като освен
високата
пропускателна
способност,
трябва да
осигуряват и
множеството
различни
режими за
работа, за
които вече
беше писано.
Памет от
тип DDR2
Ако се
следва
използваната
вече
терминология
- SDR, DDR, то паметта
от тип DDR2 би
било логично
да бъде
наречена QDR (Quadra Data Rate),
тъй като при
този
стандарт е
предвидена 4
пъти
по-висока
скорост за
предаване на
данни спрямо
базовата SDR. С
други думи, в
стандарт DDR2, в
пакетен
режим, се
предават
данни 4 пъти в
един такт. За
да се
организира
този начин на
работа на
паметта е
необходимо
входно-изходният
буфер да
работи на 4
пъти
по-висока
тактова
честота, в
сравнение с честотата,
на която
работи
ядрото на
паметта. Това
се постига по
следния
начин, ядрото
продължава
да се
синхронизира
с основната
тактова
последователност,
но входно-изходния
буфер се
тактува с
честота,
която е 4 пъти
по-висока. По
предния
фронт на
всеки един от
тези 4
импулса по 4
независими
линии на буфера
се предават 4
отделни
порции данни
с формат n бита. Това
се нарича
технология 4n-Prefetch. Самият
буфер се
тактува с
удвоената
основна
честота на
ядрото, а за
синхронизация
на предаването
на даннтите
се използват
и двата
фронта на
тази честота,
по начина
показан на
фигура 4.2.2.15. С
други думи,
ядрото може
да предава
към изходната
даннова шина
4 порции, с
което
пропускаталната
възможност
се повишава 4
пъти. Следващите
фигури
илюстрират
съответните
логически
структури.
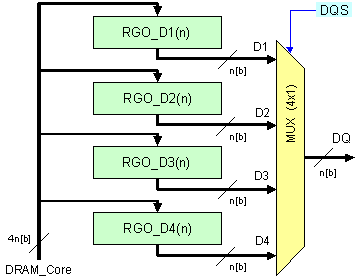
Фиг. 4.2.2.28.
Технология
4n-Prefetch при
операция
четене
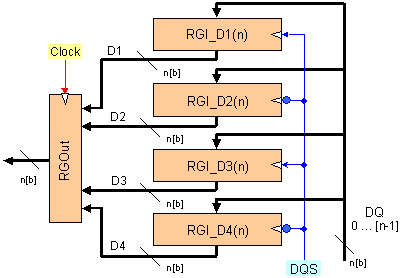
Фиг. 4.2.2.29.
Технология
4n-Prefetch при
операция
запис
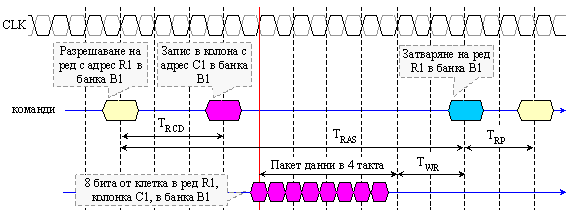
Данновият масив в паметта от тип DDR2 е разделен на 4 логически банки, което позволява да се реализират модули с обем от 1 и 2[GiB], организирани в 8 логически банки. Извършват трансфер по двата фронта на тактовия сигнал, който обаче е вътрешно с удвоена честота. Трансферът се извършва върху 64 битова даннова шина (отнася се до типичния РС-вариант). Това осигурява четворно по-голяма честота на трансфера по сравнение със честотата тактуване. Тези положения са пояснени графично със следващата фигура.
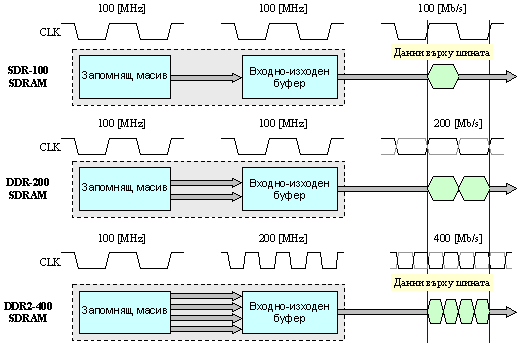
Фиг. 4.2.2.30. Принцип на
удвояване на
честотата при
памети тип DDR2
В
сравнение с
паметта от
тип DDR, паметта
DDR2
осигурява
същата
пропускателна
способност,
но при 2 пъти
по-ниска
тактова
честота на
ядрото. Например,
ядрото на
паметта от
тип DDR работи
на честота 200[MHz], а ядрото
на памет DDR2-400 работи
на честота 100[MHz]. Така
памет DDR2
има
значително
по-големи
потенциални
възможности
за
повишаване
на пропускателната
способност.
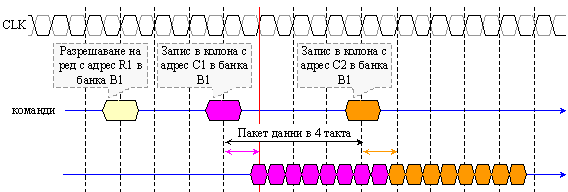
Двойният
трансфер в
рамките на
един такт беше
наречен "2n-Prefetch".
От това
следва, че
вътрешната
даннова шина
(шината на
ядрото на
паметта) е с
двойна ширина
спрямо
външната
шина. Това
изисква предаването
на данните да
става чрез
вътрешно
мултиплексиране.
Мултиплексирането
се извършва
по предния
фронт на
парафазната
тактова
двойка (CLK, not(CLK)).
Архитектурата
на DDR2 паметите
е основана на
същия
принцип, но
при нея
вътрешната
даннова шина
е 4 пъти
по-широка
спрямо
външната. Това
означава, че
броят на
банките в
запомнящия
масив, от 4 е
станал 8. За
предаване на
8 бита са необходими
4 такта, във
всеки от
който се
предават по 2
бита. Така за
предаването
на прочетените
в рамките на
един такт
данни се
налага мултиплексиране
4 към 1, което се
нарича "4n-Prefetch"
правило. За
да се
постигне
всичко това
се налага
вътрешното
удвояване на
честотата на
тактовата
последователност,
след което за
управление
на
мултиплексирането
отново се
използва
парафазната
двойка (CLK, not(CLK)).
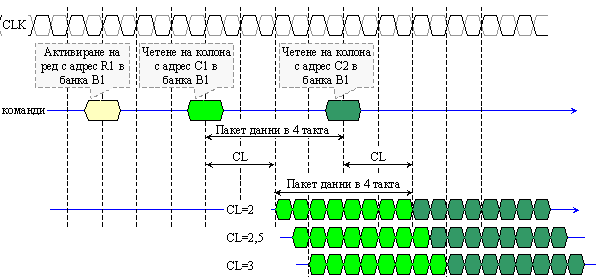
На
фигура 4.2.2.31 е
представена
времедиаграмата
на операция
четене от
памет тип DDR2. В този
пример се
предполага
наличие на 2
банки (Bank0,
Bank1), дължина
на пакета BL=4 и
тайминги tCAS=2, tRCD=3, tRRD=2. В
началото, с
микрокоманда
АСТ, се
активират и
двете банки,
за да се
получи
достъп до
съответния
ред. След това,
на всеки 2
такта се
подава
микрокоманда
за четене READ от стълб
на активната
банка.
Данните от
активната
банка
излизат със
закъснение
от 4 такта.
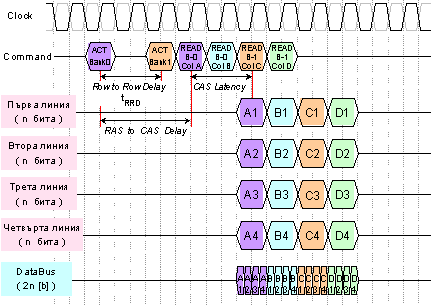
Фиг. 4.2.2.31. Обобщена
времедиаграма
за работа на
памет DDR2
Тъй
като
закъснението
CAS Delay е 2
такта, то 2
такта след
микрокоманда
READ,
данните
излизат на
изходната
даннова шина.
Напомняме, че
за
представения
пример банките
са 4, така че по
четирите
шини
паралелно
към
входно-изходния
буфер се
предават 4
порции данни
от банка А, а
след това и
от
останалите
банки – B, C, и D.
По-нататък
4-те порции
данни се
извеждат последователно
една по една
през
изходния мултиплексор,
според
същността на
технологията
4n-Prefetch, на
изходната даннова
шина. Така в
рамките на
един такт от
честотата на
ядрото, на
изхода се
предават, макар
и
последователно,
4 n-битови
порции данни.
По този начин
следва, че
минималната
дължина на
пакета за DDR2 памети
не може да е
по-малка от 4,
т.е. BL≥4.
По-долу са
представени
още
времедиаграми,
илюстриращи
основните
операции в
памети DDR2.
Фиг. 4.2.2.32. Времедиаграма
на операция
единично
четене
Фиг. 4.2.2.33. Времедиаграма
на операция
последователно
четене
Както
се вижда от
фигурата, при
последователно
четене
следващата
команда се
подава преди
да са
предадени
данните на
предидущата.
Това по
същество е
конвейеризацията
на трансфера.
При това
закъснението
CL не влияе на
трансфера.
Ако
предварителното
извличане на
данни от
паметта е
организирано
добре от
устройството
за
управление
на паметта,
то влиянието
на това
закъснение
върху производителността
ще бъде
незначително.
Времедиаграмите при операция запис имат вида, представена на следващите фигури. Обърнете внимание на центрирането на предния фронт на тактовите импулси.
Фиг. 4.2.2.34. Времедиаграма
на операция
единичен
запис
Фиг. 4.2.2.35. Времедиаграма
на операция
последователен
запис
Модулите
с памети тип DDR2
ще се
произвеждат
в нови 240-контактни
DIMM платки. В
следващата
таблица са
представени
спецификациите
на
утвърдените
към
настоящия
момент 3 JEDEC (Joint Electronic Device
Engineering Council)
стандарта DDR2
модули, които
ще се
произвеждат с
обем 256[MB], 512[MB] и 1[GB].
Таблица
4.2.2.2
Производителност
и означения
|
Честота
на шината [MHz] |
Скорост
на
предаване [MT/s]* |
Означение
на
компонента |
Означение
на модула |
Пропускна
способност
на модула [GB/s] |
Производителност
в
двуканален
режим [GB/s] |
|
200 |
400 |
DDR2-400 |
PC2-3200 |
3,2 |
6,4 |
|
266 |
533 |
DDR2-533 |
PC2-4300 |
4,3 |
8,6 |
|
333 |
667 |
DDR2-667 |
PC2-5300 |
5,3 |
10,6 |
|
400 |
800 |
DDR2-800 |
PC2-6400 |
6,4 |
12,8 |
|
500 |
1000 |
DDR2-1000 |
PC2-8000 |
8,0 |
16 |
|
533 |
1066 |
DDR2-1066 |
PC2-8500 |
8,5 |
17 |
[MT/s] -
означава
брой
мегатрансфери
за секунда.
Интегралните
схеми за DDR2
паметите ще
се произвеждат
с корпуси тип
FBGA (Fine Ball Grid Array), със
захранване
на 1,8 [v].
В
технологията
на паметта от
тип DDR2
съществуват
още
особености
със синхронизацията,
които ние ще
пропуснем
тук.
Памет от
тип DDR3
Стандарт
DDR3 се
разглежда
като
логическо
развитие на стандарта
DDR2. Серийното
производство
на памети от
тип DDR3
започва след
2005 година.
Ефективните
работни
честоти са от
800 до 1600[MHz].
Захранващото
напрежение е
понижено до 1,5[v]. Производствената
технология е
90[nm]. Значително
е намален
енергийният
разход, което
е постигнато
чрез
използване
на транзистори
с двоен
затвор (Dual-gate),
благодарение
на които е
намален
токът на разсейването.
Обемът на
тези памети е
от 1 до 4[GiB]. Логическата
структура е
организирана
в 8 банки, размерът
на
страницата е
1024 за чипове с
ширина на
шината 4 и 8, а за
чипове със
ширина на
шината 16,
обемът на
страницата е
2048.
Най-съществената
разлика на DDR3 от DDR2,
е новата технология
8n-Prefetch.
Така основният принцип за организация на ядрото на паметта е бъде запазен. В този смисъл DDR3 паметта е все още онази DDR SDRAM, в която предаването на данните се осъществява по двата фронта на тактовия сигнал. В структурно отношение организацията може да се илюстрира така.
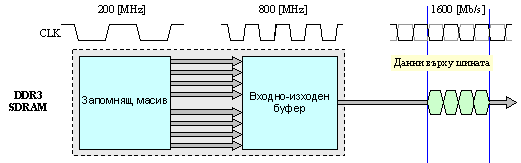
Фиг. 4.2.2.36. Принцип на
удвояване
при памети тип
DDR3
Предимствата
на паметите DDR3 са
същите като
при DDR2:
от една
страна се
снижава
енергийният
разход в
условия на
равна
пропускателност;
от друга
страна това е
възможността
за
по-нататъшно
увеличаване
на тактовата
честота до DDR3-1600.
Същите са и недостатъците
– силното
различие
между вътрешната
и външната
честота води
до още по-големи
стойности на
задръжките. В
подкрепа на
казаното
представяме
на
следващата
фигура
логическата
структура на
DDR3 SDRAM на фирмата Micron,
с обем 1[G]=230x1.
Всяка банка
от
запомнящия
масив е с
размери (16384х128х64),
т.е. 64-битовите
клетки са
подредени по
128 в един ред,
последователно
в 16384 реда.
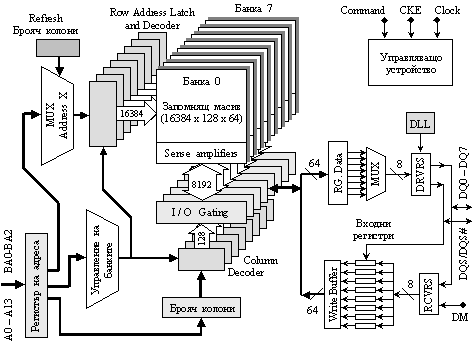
Фиг. 4.2.2.37. Общ вид
на
логическата
структура на
1[G]x1 DDR3 SDRAM (Micron)
В
този тип
памет ядрото
се
синхронизира
по предния
фронт на
основната
тактова
последователност,
а с
появяването
на всеки импулс
към
входно-изходния
буфер (вижте
фигура 4.2.2.38), по 8
паралелни
линии, се
предават 8 n-битови
порции
прочетени
данни. Това
предаване
става с
учетворена
тактова
честота спрямо
тази на
ядрото.
Самият буфер
предава на
външната
даннова шина
данни и по
предния и по
задния фронт,
така че
еквивалентната
честота се
покачва още 2
пъти. Така, при
реализация
на
технологията
8n-Prefetch, дължината
на пакета е 8,
т.е. BL=8.
На
следващата
времедиаграма
в най-общ вид
е
илюстрирана
работата на
памет DDR3, при
следните
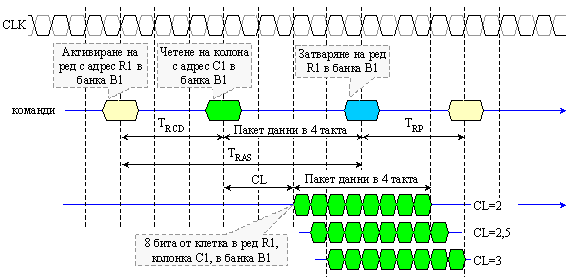
тайминги: tRRD=2, tRCD=3 и tCL=2.
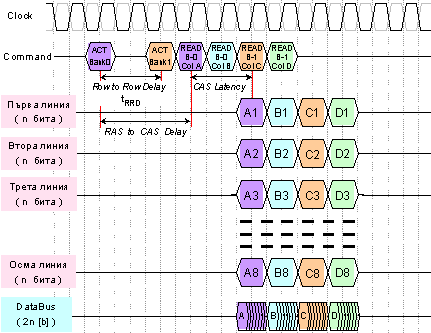
Фиг. 4.2.2.38. Обобщена
времедиаграма
за работа на
памет DDR3
Реализацията
на
технологията 8n-Prefetch не е
единственото
отличие на
паметите DDR3 от
по-старата
технология,
но тук ние не
можем да си
позволим
по-нататъшно
разширение на
темата.
Памет
от тип DDR4
Първоначално
публикуван
през
септември 2012 г.
и последно
актуализиран
през юни 2017 г.,
стандартът JEDEC
DDR4 е определен
за
осигуряване
на по-висока
производителност,
с подобрена
надеждност и
намалена
мощност, като
по този начин
представлява
значително
постижение по
отношение на
предишните
технологии
за памет на DRAM.
DDR4
(JESD79-4B) е достъпен
за изтегляне
от уебсайта
на JEDEC. DDR4
предлага
широка гама
от
иновативни
функции,
предназначени
да осигурят
висока скорост
на работа и
широка
приложимост
в различни
приложения,
включително
сървъри,
лаптопи,
настолни
компютри и
потребителски
продукти. Освен
това, новата
технология е
дефинирана с
цел
опростяване
на
миграцията и
позволяване
на
възприемането
на
общонационален
стандарт. Дефинициите
са следните:
DDR4-1600 (PC4-12800) ;
DDR4-1866 (PC4-14900) ;
DDR4-2133 (PC4-17000) ;
DDR4-2400 (PC4-19200) ;
DDR4-2666 (PC4-21333) ;
DDR4-2933 (PC4-23466) ;
DDR4-3200 (PC4-25600) .
Този
вид памет е
своеобразен
аналог на паметта
DDR3 дотолкова,
доколкото тя
също
използва технологията
8n-Prefetch.
Произвежда
се с
използване
на 32
нанометрова
технология.
Може би тук
е момента, в
който следва
да обърнем
внимание на
този
параметър.
Обикновено
потребителят
очаква
степента на
дискретизация
да расте, а в
паметите
това да се
изрази в увеличаване
на обема.
Нека да се
спрем на следните
данни,
представени
в следващата
таблица.
Таблица 4.2.2.3.
Производствени
технологии в
нанометри по
години
|
|
2014 |
2015 |
2016 |
2017 |
2018 |
2019 |
2020 |
2021 |
2022 |
|
Логически
схеми |
20 |
16 |
14 |
10 |
7 |
7 |
5 |
5 |
3 |
|
памети DRAM |
28 - 40 |
32 |
30 |
22 - 20 |
|
|
|
|
|
Забележка:
зоните в
червено са
прогнозни ███ .
У читателя вероятно възниква въпросът: защо степента на дискретизация у паметите не е така значителна, както в останалите схеми? Отговорът е елементарен – заради кондензаторът, който изгражда запомнящите елементи.
Обемът
на чиповете е
в границите
от 2[Gib] до 16[Gib].
Скоростта
на предаване
на данни за DDR4
се определя в
границите на
1,6[GiB/s] до 3,2[GiB/s]. Структурата
на ядрото е с 2
или 4
избираеми
банкови
групи.
Ширината на
вътрешните
даннови
линии може да
бъде 4, 8 или 16
бита. Този
дизайн
позволява на
устройствата
с памет DDR4 да
имат отделни
микрооперации
по
активиране,
четене, запис
или опресняване
във всяка
уникална
банкова група.
Тази
концепция
също така
подобрява общата
ефективност
на паметта и
честотната
лента. За
паметта са
дефинирани
множество
допълнителни
функции,
които няма да
разглеждаме
тук.
Като
пример DDR4 на Micron поддържа
банково
групиране: x4/x8. Ядрото
съдържа
четири
банкови
групи (BG[3:0]) и всяка
банкова
група се
състои от
четири подбанки (BA[3:0]).
Паметите DDR4 x16
имат две
банкови
групи (BG[1:0]), а всяка
банкова
група съдържа
четири
подбанки. Ядрото може
да бъде
структурирано
така: 1Gx1, 512Mx4, 256Mx8. И още 8[Gib] DDR4-чип е с
4-битова
даннова шина.
Ядрото
съдържа 4 отделни
групи от
банки, като
всяка група
съдържа 4
банки. Всяка
банка има
размери 131072=217 х
512 х 8. Малката
дължина на
редовете (512)
подпомага
по-бързото
“претърсване"
на банката. Общият
вид на
логическата
структура
илюстрират
следващите
фигури.
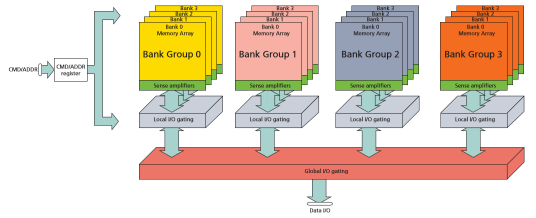
Фиг.
4.2.2.39. 4[G]x1: x4/x8/x16 DDR4 SDRAM на Mikron.
Обща
структура на
групите от
банки и банките
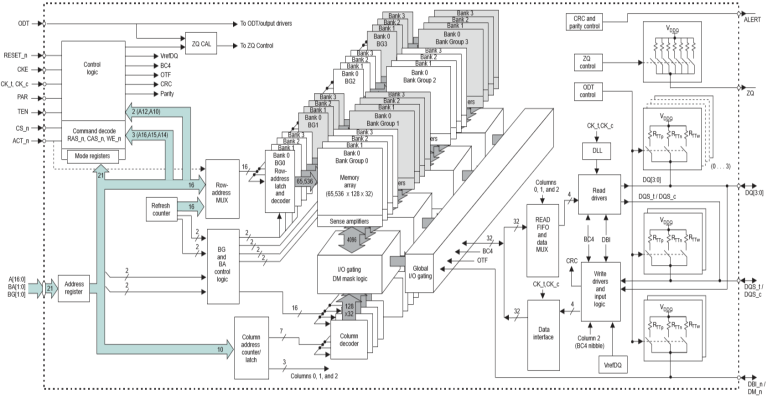
Фиг.
4.2.2.40. Общ вид на
логическата
структура на
1[G]x1 DDR4 SDRAM
(Micron)
Добре
е читателят
да обърне
внимание на
факта, че
отделните
банки имат
силно
изразена пространствена
форма –
техните
клетки са
разположени
матрично, но
имат 4
байтова
дължина.
Функцията
на банковите
групи,
използвана в
DDR4 SDRAM, е
заимствана
от
графичните памети
на GDDR5. За да се
разбере
необходимостта
от банкови
групи, трябва
да се разбере
концепцията
за DDR SDRAM prefetch. Prefetch е
термин,
описващ
колко порции
от данните се
извличат на
всеки такт,
когато
командата достъпне
колона в DDR
памет.
По-горе беше
посочено, че
паметите DDR4
използват
мултиплексиране
8n-Prefetch,
което
означава, че
на изходната
шина в рамките
на един
период на
основната
тактова последователност
се предават 8
порции данни
(вижте фигура
4.2.2.38). Тъй като
ядрото на
паметта е
много по-бавно
от
входно-изходния
буфер,
разликата се
преодолява
чрез
паралелен
достъп до информацията,
която след
това се
извежда чрез
интерфейса.
Например, DDR3
предварително
извлича осем
порции от
данни, което
означава, че
всеки път,
когато се
изпълнява
операция за
четене или
запис, се
предават
осем порции
от данни,
което се
синхронизира
в интерфейсния
буфер по
двата фронта
на учетворената
тактова
честота.
Така, може да
се каже, че,
интерфейсът
е осем пъти
по-бърз от
ядрото на DRAM.
Недостатъкът
на
предварителното
извличане от
ядрото е, че
то определя минималната
дължина на
пакета (BL=8, Burst
Length). Например,
много е
трудно да
имаме
ефективна
дължина на
поредицата
от четири
порции, при
предварително
извличане на
осем такива.
Новото в DDR4 е
съчетанието
на технологията
8n-Prefetch с
банковото
групиране.
Функцията на
банковата
група
позволява на
дизайнерите
да поддържат
по-малка
предварителна
извадка, като
същевременно
увеличават
производителността,
както ако
предварителната
извадка е
по-голяма.
Тъй
като скоростта
на ядрото не
се променя
значително от
поколение на
поколение,
предварителното
извличане се
е увеличило с
всяко
поколение DDR,
за да
предложи
по-голяма
скорост на SDRAM
интерфейса.
Продължаването
на тази
тенденция в DDR4
би наложило
да се приеме
технология 16n-Prefetch.
Такава
промяна би
направила DRAM
много по-голяма
поради
всички
кабели, които
трябва да бъдат
изградени. DRAM
ще са
прекалено
скъпи, така
че
дизайнерите
се отказват
от тези разходи.
По-важното е,
че
предварителната
извадка от
шестнадесет
порции няма
да
съответства
на размера на
линията на
кеша от 64
байта,
обичайна за
днешните
компютри. С
64-битовия или
72-битовия
интерфейс в
типична
изчислителна
среда, която
използва
64-байтова кеш
линия,
предварително
извличане на
осем, заедно
с дължина на
пакета от
осем, е
по-добро
съвпадение.
Всяко такова
несъответствие
на размера на
линията на
кеша и
дължината на
пакета може да
има
отрицателно
въздействие
върху работата
на
вградените
системи.
Ядрото
на паметта е
доста бавно и
това се променя
незначително
във времето,
докато
скоростта на
входно-изходния
интерфейс се
е увеличила
значително с
течение на
времето. Ако
основната честота
варира в
интервала 100, 200[MHz],
трансферът
на данни се е
увеличил от
около 1300[Mb/s] през
2010 година, до
около 3000[Mb/s]
през 2017 година.
Ядрото на SDRAM не
е станало
по-бързо във
времето до
голяма
степен
поради това,
че всички
ползи,
получени от
процес с по-малка
дискретизация,
са
компенсирани
от много
по-големия му
капацитет.
Дизайнерите
в крайна
сметка се
борят за увеличаване
на
капацитета,
което се
постига с
миниатюризация
на процеса.
Въпреки това,
входно-изходния
интерфейс е
последователно
по-бързо с
всяко ново
поколение.
На
следващата
фигура е
показано как
предварителното
извличане се
е развило
през четири
поколения SDRAM,
от SDR до DDR3. За
всяка
основна
операция с
една колона
(четене или
запис) броят
на думите, до
които се
осъществява
достъп
веднага, е представен
от броя на
масивите на
паметта, заедно
с
приблизителното
време на
цикъл (MHz), което
е необходимо,
за да се
извлекат
тези думи от
или в ядро на
паметта.
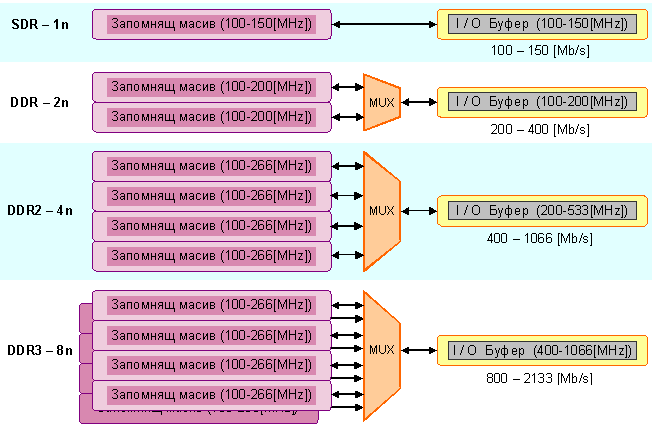
Фиг. 4.2.2.41.
Еволюция
на DRAM-Prefetch
DDR4
избягва
проблема
с
въвеждането
на по-висок Prefetch,
като въвежда
концепцията
за банкови
групи. При
банкови
групи се
извършва предварителна
извадка от
осем порции
данни от/в
една банкова
група, а друга
предварителна
извадка от
осем порции
може да се
извърши в
друга
независима
банкова
група.
Банковите
групи са
отделни
единици, така
че
позволяват
цикъл на
колони да се завърши
в рамките на
банкова
група, но
този колонен
цикъл не
влияе на
това, което
се случва в
друга банкова
група.
Всъщност, DDR4
може да
мултиплексира
своите
вътрешни
банкови
групи с времево
разделяне, за
да скрие
факта, че
вътрешното
време на
основния
цикъл на
ядрото
отнема
повече време
от интервала
за осем порции.
Следващата
фигура
показва как
този процес
търси x16 DDR4 с две
банкови
групи, които
често се
използват
във вградени
приложения.
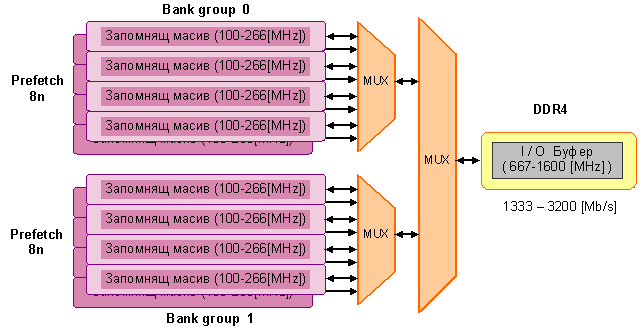
Фиг. 4.2.2.42. DRAM4-Prefetch
Решение за
извличане на
осем
Въвеждането
на банкови
групи идва с
нови спецификации
за DDR4. Две
ключови
спецификации
са tCCD_S и
tCCD_L.
Таймингът CCD (Column to Column Delay)
означава “закъснение
от колона до
колона” или “команда
за
закъснение
на командата”
от страната
на колоната.
Символът “_S“
означава
“кратко“ (Short), а "_L“
означава
“дълъг“ (Long).
Когато
една команда
се стартира в
една банкова
група с 8n
предварително
извличане,
предварителната
извадка
трябва да
бъде разрешена,
за да завърши
цялото време
на цикъла на
групата.
Преминаването
от една банкова
група към
друга
банкова
група няма зависимост
от тези
спецификации.
Такъв е случаят
с
използването
на
спецификацията
tCCD_S, която при
четири
тактов цикъл,
е не ограничаваща
по начин,
подобен на DDR3.
Но
ето и още
особености.
Преминаване
от една банка
към друга
банка
изисква
закъснение tCCD=4Т.
Преминаването
от команда
към команда,
докато сте в
рамките на
една и съща
банкова група,
изисква
закъснение tCCD_L ,
което не е
постоянно за
различните
памети и
обикновено е
по-голяма от
4Т, като при
най-бързите памети
достига до 8Т.
Памет от
тип DDR5
Както
беше
отбелязано
още през май 2018
г., основната
новост на DDR5 ще
бъде както
завишения капацитет
на чиповете,
така и
по-високата
производителност
и по-ниската
консумация
на енергия. DDR5
се очаква да
реализира пропускателна
способност в
интервала от
4266 до 6400[MT/s]. Захранващото
напрежение
бележи спад
до 1,1 – 1,05[v].
Очакват се
модули с два
независими
32/40-битови
канала. Освен
това, DDR5 ще има
подобрена
ефективност
на
командната
шина,
по-добри
схеми за
опресняване
и увеличена
банкова
група. Една
от
най-важните
характеристики
на DDR5 ще бъде
монолитна
плътност на
чиповете над
16[Gib]. Водещите
производители
на DRAM вече имат
монолитни DDR4
чипове с
капацитет 16[Gib], но тези
устройства
не могат да
използват екстремни
тактови
честоти,
поради
законите на
физиката. С
много от
проблемите
производителите
очакват да се
справят ако
успеят да
усвоят
степен на
дискретизация
от порядъка
на 10-12[nm].
DDR5 SDRAM
ще постига
по-висока
скорост, като
използва
технология 16n-Prefetch в буфера
за
предварително
извличане. DDR5
разделя
банките DRAM на
две, на
четири или на
осем избираеми
банкови
групи, докато
DDR4 използва до 4
банкови
групи.
Добавят се и
някои нови функции:
Както
читателят
разбира, към
този момент
нищо сигурно
за този вид
памети не е
известно. Все
още нещата са
в сферата на
патентите и
на стандартите,
за които се
конкурират
различни
фирми.
Научните
изследвания
няма да спрат
и в мрежата
вече се
анонсира
памет от тип DDR6. От нас се
очаква добре
да “смелим”
вече
известното,
защото то ще
ни помогнем по-лесно
да разберем
новите идеи.
Новият
тип памет - DDR5,
като
наследник на
DDR4, е разработен,
за да подобри
производителността.
С тази памет
системните
дизайнери се
чувстват все
по-силни в
непрекъснатия
технологичен
напредък,
където
текущата
пропускателна
способност
на паметта
просто не е в
състояние да
се справи с
по-новите
модели
процесори,
имащи
нарастващи
основни параметри.
Основният
драйвер на DDR5
обезпечава необходимостта
от по-висока
честотна
лента.
В
сравнение с DDR4
при
еквивалентна
скорост от 3200
мега-трансфера
в секунда [MT/s],
симулацията
на системно
ниво на DDR5
показва приблизително
увеличение
на
производителността
на
ефективната
честотна
лента до
1,36 пъти. При
по-висока
скорост на
пренос на данни,
например при
DDR5-4800,
приблизителното
увеличение
на
производителността
става 1,87 пъти – което
е почти
двойно
по-голяма
честотната лента,
в сравнение с
DDR4-3200.
На
системно
ниво, въпреки
скромните
подобрения в
тактовата
честота,
преходът към
много-ядрени
процесорни
архитектури
е позволил
непрекъснато
увеличаване
на производителността
на
изчисленията
от година на година.
Изкривяванията
на сигнала,
консумацията
на енергия,
сложността
на оформлението
и други
предизвикателства
на ниво
система
ограничават
повишаването
на тактовата
честота на
ядрото на
процесора.
Едновременно
с това броят
на CPU ядрата
непрекъснато
се увеличава,
което
ограничава
наличната
честотна
лента на
паметта в
ядрото. За да
отговорят на
изискванията
на
следващата
генерация в
честотната
лента на
ядрото, са
необходими
нови
архитектури
на паметта,
извън
сегашната DDR4 SDRAM.
Докато DDR4
предлага
трансфер на
данни от 1600 [MT/s]
до 3200 [MT/s], DDR5
понастоящем
е дефиниранa с данни от
3200 [MT/s]
до 6400 [MT/s].
Увеличаването
на скоростта
на предаване на
данни ще
позволи на
ядрото да
запази съществуващата
пропускателна
способност.
Основните
постижения
на
дизайнерите
са във
входно-изходния
буфер. Тук са
добавени критично
нови функции,
които позволяват
постигането
на тези
по-високи
скорости на
пренос на
данни. Една
от тях е
добавянето
на
изравнител
за обратна
връзка с многократно
натискане (DFE) в
DQ
приемниците.
Други нови
функции,
които
позволяват
увеличаване
на скоростта
на данните,
включват:
·
Верига
за настройка
на работния
цикъл (DCA, Duty cycle adjuster),
способна да
коригира
както DQ, така и
DQS работните
цикли за
вътрешния
път на
четене. Това помага
да се
коригират
малките
деформации
(закъснения)
на работния
цикъл, които
възникват
естествено,
тъй като тези
сигнали
преминават
през устройствата
и печатни
платки, като
в крайна сметка
оптимизират
работните
цикли за DQ и DQS сигналите,
получени от
контролера;
·
DQS
интервална
тактуваща
верига,
която
позволява на
контролера
да следи промените
в задръжките
на DQS
часовника,
причинени от
промени в
напрежението
и
температурата.
Това позволява
на
дизайнерите
на
контролерите
активно да
решават дали
и кога
пренастройката
може да бъде
полезна и
необходима,
за да се
запази
оптималното
време за
запис;
·
Въведени
са нови и
подобрени
режими на
обучение,
включително
нов режим за
обучение на
преамбюла за
четене, режим
за обучение
на командите
и адресите,
режим на
обучение за
избор на чип
и режим на
обучение за
изравняване
при запис.
Изравняването
при запис
осигурява същата
способност
като DDR4, която
позволява на
системата да
компенсира
разликите
във времето
между CLK модула
по пътя му до
всяко DRAM
устройство
(което варира
в зависимост
от маршрута
по модула на
паметта) и DQ и DQS
пътищата
(които са
къси, тъй
като се намират
във
вътрешността
на
интегралните
схеми). Освен
това, DDR5 има
нова
функционалност,
компенсираща
новата DQ-DQS
архитектура
на приемника,
което
допълнително
позволява по-бързи
скорости на
предаване на
данни;
·
Прочитане
на
тренировъчните
модели с регистри
за специален
режим.
Свързаните
данни
включват
модела по
подразбиране,
програмиран
сериен модел,
прост образец
на часовника
и генериран
модел на линеен
обратен
изместващ
регистър (LFSR),
които в
крайна
сметка
осигуряват
по-стабилна граница
за времето за
високи
скорости на
данни;
·
Вътрешни
референтни
напрежения
за
командните и
адресните
пинове (VREFCA),
както и пина
за избор на
чип (VREFCS). В
допълнение
към
вътрешното
референтно напрежение
е и това за DQ
пиновете (VREFDQ),
което
подобрява
границата на
напрежението
на DQ
приемниците.
Тези нови
вътрешни
референтни
напрежения
за
командния/адресния
и за чип
селекционния
пин, подобряват
границата на
напрежението
на техните съответни
приемници и
допълнително
позволяват
устройство
да постигане
по-висока скорост
на предаване
на данни;
·
Функции
на протокола
за
ефективност.
В допълнение
към
по-високите
скорости за пренос
на данни и
подобренията
в I/O-буфера, DDR5 въвежда
други нови
функции на
протокола, които
не са
свързани със
скоростта на
предаване на
данни, и
които са
неразделна
част от
увеличаването
на честотната
лента и
производителността.
Например, DDR5 DIMM
модулите
имат два
независими
канала с 40
бита (32 бита
плюс ECC). Когато
се комбинира
с нова
дължина на
пакета по
подразбиране
от 16 (BL16) в
компонента DDR5,
това
позволява
дължината на
един пакет да
достигне до 64B
(типичния
размер на
линията на
кеша на
процесора),
използвайки
само един от
независимите
канали или
само
половината
от DIMM.
Осигуряването
на тази
способност за
разместване
на достъпа от
тези два независими
канала дава
възможност
за огромни
подобрения
на
конкурентността,
като по
същество
превръща
8-каналната
система, каквато
я познаваме
днес, в
16-канална
система.
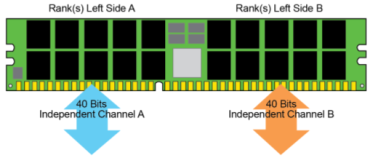
Фиг.
4.2.2.43. DDR5 DIMM
В запомнящия масив на DDR5, броят на банковите групи (BGs) се удвоява в сравнение с DDR4, като броят на банките в банковите групи остава същият. Това позволява на контролерите да избягват влошаването на производителността, свързана с последователния достъп до паметта в рамките на една и съща банка.
В
следващата
таблица е
изразен
паралелът
между DDR4 и
добавените
подобрения в
DDR5
архитектурата.
Таблица
4.2.2.3.
Сравнение
на
характеристиките
на
устройствата
между DDR4 и DDR5 SDRAM
|
Feature |
DDR4 |
DDR5 |
Ползи
/ Подобрения |
|
Скорост
на
предаване |
1600-3200 [MT/s] |
3200-6400 [MT/s] |
Повишена
производителност
и
пропускателна
способност |
|
|
|
|
|
|
Плътност
на
устройствата |
2-16 [Gib] |
8-64 [Gib] |
По-големи
монолитни
устройства. |
|
|
|
|
|
Prefetch
|
8n |
16n |
Позволява
по-високи
скорости на
пренос на данни,
като
запазва
вътрешния
обхват на
часовника
на ядрото
подобен на DDR4. |
|
|
|
|
|
|
Изравняване
на DQ
приемника |
няма |
Multi-tap
DFE |
Отваря
DQ за данни
вътре в DRAM,
като
директно
позволява
висока
скорост на
предаване
на данни. |
|
|
|
|
|
|
Настройка
на работния
цикъл (DCA) |
няма |
DQS and
DQ |
Позволява
на контролера
да
компенсира
изкривяването
на работния
цикъл (DCD) на
всички DQS и DQ
игли(pins) чрез
регулиране
на работния
цикъл вътре
в DRAM. |
|
|
|
|
|
|
Вътрешен
мониторинг
на
забавянето
на DQS |
няма |
Осцилатор
на
интервала DQS |
Осигурява
метод за
контролера
да реши дали /
кога да се
преквалифицира
въз основа
на промени в
закъсненията
на DRAM,
причинени от
промени в
напрежението
и
температурата;
осигурява
стабилност
срещу
промени в околната
среда. |
|
|
|
|
|
|
По
време на ECC |
няма |
128[b]
+ 8[b]
SEC, проверка за
грешки и изправяне |
Укрепва
RAS на чип;
намалява
тежестта
върху контролера. |
|
|
|
|
|
|
8CRC |
Запис |
Четене
/ Запис |
Укрепва
системния RAS
чрез защита
на прочетените
данни. |
|
|
|
|
|
|
Bank groups (BG)/banks |
4 BG x 4 банки |
8 BG x 2
banks (8[Gib] x4/x8) 4 BG x 2
banks (8[Gib] x16) 8 BG x 4
banks (16-64[Gib] x4/x8) 4 BG x 4
banks (16-64[Gib] x16) |
Помага да
се избегнат
влошаването
на производителността
от
последователния
достъп до
паметта на
една банка |
|
|
|
|
|
|
Интерфейс
Команди /
Адреси |
ODT, CKE, ACT, RAS, CAS, WE, A<X:0> |
CA<13:0> |
Изисква
два цикъла
за някои (но
не всички)
команди,
което
значително
намалява
броя на пиновете
на CA (Counter Address). |
|
|
|
|
|
|
ODT |
DQ, DQS, DM/DBI |
DQ, DQS, DM, CA bus |
CA ODT
осигурява
подобрена
цялост на
сигнала и спестява
разходите
за
спецификация,
като елиминира
външната
свързваща
резисторна
мрежа за CA
шината. |
|
|
|
|
|
|
BL (Дължина
на пакета) |
BL8 (and BL4) |
BL16, BL32 (and BL8 OTF, BL32 OTF) |
В
комбинация
с 2-канална DIMM
архитектура,
позволява
извличане
на 64B кеш линия,
използвайки
само
половината
от DIMM. |
|
|
|
|
|
|
Инверсия
на шината |
Инверсия
на шината за
данни (DBI) |
Инверсия
на шината
Команда/Адрес
(CAI) |
Намалява
мощността и
шума на VDDQ
линията. |
|
|
|
|
|
|
CA
обучение, CS
обучение,
запис на
нива за
обучение |
Режим
запис на
нивата за
обучение |
CA
обучение, CS
обучение и
режими за
запис на
нивата за
обучение |
Подобрената
граница на
синхронизация
на пиновете CA
и CS,
позволяваща
по-бързи
скорости на
пренос на
данни.
Обучението
за нивелиране
на запис в DDR5
също
компенсира
разнородното
DQ-DQS трасе на
устройството,
което улеснява
поддръжката
на бързи
скорости на
пренос на
данни с
кратки
преамбюли
за запис и позволява
по-кратки
превключвания
на шината. |
|
|
|
|
|
|
Четене
на моделите
за обучение |
Възможно
с MPR |
Специализирани
MRs за серийни
(потребителски
дефинирани),
часовник и LFSR генерирани
обучителни
модели |
Специализираното
обучение за
четене включва
MRs за избор на
модел на
обучение,
включително
такъв, който
използва LFSR за
осигуряване
на PRBS модел.
Това
осигурява
по-надеждна
граница за
отчитане на
времето,
особено при
по-високите
скорости на
пренос на
данни. |
|
|
|
|
|
|
Регистри
на режима |
7 x 17[b] |
До
256 x 8[b]
(четене /
запис от тип
LPDDR) |
Ниша
за
разширяване,
което е
необходимо
за новата
поддръжка и
подобрения
на функциите. |
|
|
|
|
|
|
Команди
PRECHARGE |
Всички
банки и
всяка банка
поотделно |
Всички
банки, всяка
банка
поотделно и
отделна
банка |
SAME BANK
PRECHARGE (PREsb) дава
възможност
за
предварително
зареждане
на
конкретна
банка във
всяка банкова
група, като
запазва
активното
състояние
на всички
останали
банки
непроменени. |
|
|
|
|
|
|
Команди
REFRESH |
Всички
банки |
Всички
банки, както
и отделна
банка |
SAME BANK
REFRESH (REFsb) дава
възможност
за
опресняване
на конкретна
банка във
всяка
банкова
група, като
по този
начин
всички
останали
банки в банковата
група имат
свободен
достъп. |
|
|
|
|
|
|
Режим
на обръщение |
няма |
има |
Позволява
тестване на DQ
и DQS
сигнализацията
между
контролера
и DRAM,
изолирайки
реалния масив
от паметта,
тъй като
достъпът за
четене /
запис не е
необходим. |
Следващият
раздел е:
4.2.2.1. Контролер
на
съвременни
динамични
памети