Последната
актуализация
на този
раздел е от 2020
година.
§ 5.3
Етапи при
изпълнение
на машинната команда
Излагайки
в
предидущите
два пункта
методите за
адресиране
на операнди и
на машинни команди
ние по
същество
внесохме
значително
детайлизиране
в действията
на основния
(първичния)
организационен
алгоритъм за
функциониране
на процесора,
така
наречения
команден
цикъл. Тук отново
се връщаме
към този
алгоритъм,
тъй като сме
убедени, че
доброто
познаване на
процесите в
цифровите
процесори се
основава именно
на този
алгоритъм. В
този
параграф
нашето внимание
към него е
провокирано
от еволюцията
в
компютърната
архитектура,
която създаде
и приложи
много нови
организационни
принципи,
водещи до
тази висока
производителност,
на която сме
свидетели. И
понастоящем този
процес е
много
активен.
Водещите
фирми
работят
активно по
техническата
реализация
на множество
нови
организационни
принципи,
отнасящи се
до
максималното
оползотворяване
на реалния
паралелизъм,
което се
изразява не
само в
апаратно-архитектурното
развитие, но
и до
алгоритмите
за неговото
оптимално
управление.
В
представената
на фигура
5.1.4 блок-схема
на командния
цикъл ясно се
различават
два основни
етапа –
доставяне (fetch)
на машинната
командата от
оперативната
памет в
регистъра на
командата и
изпълнение (execution)
на команда.
Прочитането
на командата
става от
адрес, който
се формира
автоматично
в програмния
брояч.
Адресът на
командата е
нейния
начален
адрес,
съдържащ
нейния КОП.
При
доставяне на
командата, в
зависимост
от дължината
й, от
ширината на
данновата
шина и от
структурата
на физическата
памет,
програмният
брояч се
модифицира
(инкрементно)
така, че
съдържанието
му в края на
този етап
винаги
представлява
следващия
адрес.
Прочитането
и
доставянето
на команда
или операнд
от паметта ще
наричаме още извличане.
Извличането
на командата
от
оперативната
памет в
регистъра на
командата,
при тази първоначална
класическа
постановка,
се осъществява
от
централното
управляващо
устройство ЦУУ
(вижте фигура
5.1.3).
В
края на
първия етап,
с попадането
на командата
в регистъра
на командата,
същата се използва
от
управляващото
устройство
за преход към
нейната
микропрограма
и стартиране
на същата. В
литературата,
реализацията
на този
преход често
се нарича декодиране
на командата,
т.е. намиране
на нейната
микропрограма.
За целта се
използва
информацията
от всички
полета на
командата,
които имат отношение
към нейния
КОП. Тук
следва да
поясним на
читателя, че
в ЦУУ се
съдържат
алгоритмите
за
изпълнение
на всички
машинни
команди, т.е.
това
устройство,
като
управляващ автомат,
е
многофункционално.
Изпълнявайки
съответната
микропрограма,
управляващото
устройство
управлява
изпълнението
на
операцията в
операционното
устройство.
Принципите
за синтез и
реализиране
на управляващи
устройства
са изложени в
глава 7 на
тази книга,
а така също в
съответните
теми на книга
[1] и на книга [2]. С
прехода към
съответния
алгоритъм
управляващото
устройство
фактически
преминава
към втория
етап в
командния
цикъл – изпълнението
на командата.
По
време на
изпълнение
на типичната
машинна
команда,
както вече
подробно
разгледахме,
се открояват
допълнително
следните
общи етапи в
нейната
микропрограма:
·
Изчисляване
на
изпълнителния
адрес на операндите
;
·
Прочитане
и доставяне
(извличане)
на операндите
от
оперативната
памет ;
·
Изпълнение
на
операцията в
операционното
устройство
(АЛУ, ОЗУ) ;
·
Фиксиране
на резултата
и неговите
признаци.
Интересно
е да
погледнем в
случая на
управляващото
устройство
като на
устройство съсредоточило
в себе си
цялата власт,
държащо под
контрол и
управляващо
всички процеси
в структурата
на процесора.
Ще изобразим
във вид на
времедиаграма
заетостта на
това устройство
с останалите
устройства в
класическата
структура на
процесора.
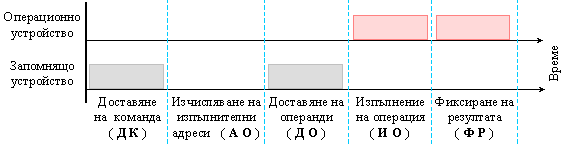
Фиг.
5.3.1. Заетост
на ЦУУ с
устройствата
на процесора
Колкото
и идеалистична
да е
представата
за работата
на централното
управляващо
устройство
от фигура 5.3.1,
безспорно се
налага
изводът, че
то не общува
непрекъснато
с отделните
устройствата.
Бихме могли
да засилим
този извод като
кажем, че при
неговата централизация,
то не е в
състояние да
направи това.
Като следствие,
в работата на
отделните
устройства, неизбежно
се появяват престои.
Този факт е
особено
нелицеприятен,
когато целим
висока
производителност
на процесора.
В
съответствие
с този вид,
първичният организационен
алгоритъм на
командния
цикъл се
практикува в
процесори с
елементарна
и непретенциозна
архитектура.
Ще подкрепим
казаното с командния
цикъл
(представен
обобщено) на
серия
8-битови
микропроцесори
на фирма Motorola МС68
– фигура 5.3.2.
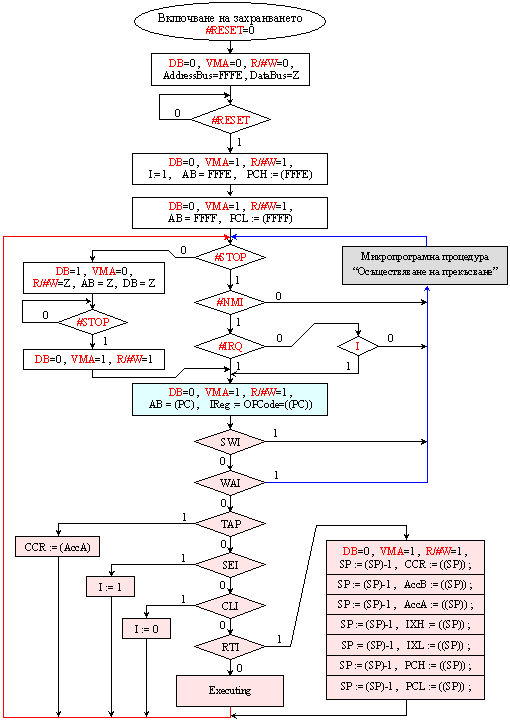
Фиг.
5.3.2. Команден
цикъл на
8-битови
микропроцесори
Motorola
Разбираме,
както се
вижда от
рисунката, че
след
включване на
захранването
се генерира
сигнал RESET. Този
сигнал се
нарича още авторесет,
за разлика от
студения
ресет и
топлия ресет,
които
вероятно са
познати на
читателя.
След неговото
автоматично
снемане,
върху адресната
шина се
генерира
фиксиран
адрес FFFE и от
паметта се
прочита 1
байт, който
се записва
като
съдържание
на старшата
половина на програмния
брояч ( PCH:=(FFFE) ).
Операция
четене се
повтаря за
младшата
половина ( PCL:=(FFFF) ).
Така
програмният
брояч РС се
оказва зареден
с началния
адрес на
първата
програма. Влизайки
с този адрес
в командния
цикъл, най-напред
се проверява
наличието на
входните
сигнали:
·
#STOP
(изключване
на шините и
тактовия
вход). Докато
този сигнал
се подава, в
логическата
структура на
процесора
няма никакви
превключвания.
Работата
продължава
след
изчезване на
сигнала ;
·
Заявка
за
немаскируемо
прекъсване #NMI.
Ако такава
има, следва
незабавно
прекъсване
на текущата
програма.
Прекъсването
се реализира
от
микропрограмна
процедура,
която ще
покажем
по-късно ;
·
Заявка
за
маскируемо
прекъсване #IRQ.
Ако такава
има и не е
маскирана
(флаг I=0), следва
прекъсване.
Част
от
употребените
току що
понятия предстои
да бъдат
определени и
разглеждани
тук в следващите
пунктове.
Следва извличане на първия байт на командата. Тъй като във всички случаи това е кодът на операцията, следват проверките дали това не е:
·
Команда
за програмно
прекъсване SWI ;
·
Команда
очаквай
прекъсване WAI ;
·
Зареждане
на
акумулатор в
регистъра на
признаците TAP ;
·
Установяване
на маската за
прекъсване SEI ;
·
Изчистване
на маската за
прекъсване CLI ;
·
Връщане
от
прекъсване RTI.
За
тези команди,
както и за
всички
останали това
е етапът на
изпълнение.
След изпълнението
командният
цикъл се
затваря.
Допълнителни организационни принципи
За
разлика от
представеното
по-горе,
развитите в
архитектурно
отношение
процесори се
характеризират
с
използването
на множество
допълнителни
организационни
принципи,
които имат за
цел
оптимизиране
на
управлението
на автоматичния
ход на
изчислителния
процес и повишаване
на общата им
производителност.
Всички тези
принципи
обаче си
приличат по
това, че се
стремят да
реализират
на практика
под една или
друга форма паралелни
във времето
действия.
Това е лесно
разбираемо,
като се има
предвид
желанието за
по-висока
производителност
на
компютърните
системи.
Възможностите
за паралелни
във времето
действия се
съдържат в
хода на
изчислителния
процес, който,
както беше определен,
е структурен
процес. Ще
подкрепим
казаното
чрез един обикновен
пример:
необходимо е
да се изчисли
стойността
на израза Z=a+b+c-d, в
който са
записани 3
последователни
операции от
тип събиране.
Ако запишем
обаче израза
така: Z=(a+b)+(c-d),
веднага
можем да
съобразим, че
първата и
последната
операции
могат да се
изпълнят
едновременно
(паралелно
във времето),
в резултат на
което
изчислението
ще завърши
по-бързо.
Положителният ефект от реализацията на различните видове паралелни във времето действия е естествено разбираем и не се нуждае от допълнителни разяснения. Ето защо по-долу ще изброим някои от организационните принципи, прилагани с цел автоматично откриване и реализация на паралелизми:
1. Изхождайки
от
неефективността
на класическата
организация,
която по-горе
бе изяснена,
е напълно
разбираем
отказът от
централизираното
управление и
преход към
децентрализирано
или още разпределено.
Този подход
се
характеризира
с декомпозиране
на
управляващите
алгоритми.
Отделно обособените
части, имащи
самостоятелна
роля, се
реализират
като отделни
управляващи
автомати,
които както
териториално,
така и
функционално,
са
неразривно
свързани
(съвместени)
с операционните
устройства,
които
управляват.
Това
превръща
съответните
операционни
устройства в
самостоятелни
операционни автомати.
Главното
достойнство
на тази
организация
се състои във
възможността
за паралелно
(във времето)
функциониране
на тези
самостоятелни
операционни
автомати.
Паралелното
и асинхронно
функциониране
води, от една
страна до
рязко
повишаване
на производителността
при обработка
на потока от
назначени
операции, а
от друга
страна до
нови
архитектурни
решения
относно
структурата
на
съществуващите
в процесора
устройства,
както и до
появата на
нови такива.
Задачата, да
бъде стройна
“песента” на
този “хор”, е
поверена на
така наречения
диспечер.
Същността на
съвместното
функциониране
на
множеството
автомати е
воденият
между тях “диалог”
на ниво
сигнали
(вижте книга
[2]).
Типичен
пример за
този подход е
ранната структура
на
микропроцесор
Intel8086. В този
процесор е
организирано
асинхронно
паралелно
функциониране
на операционното
устройство (EU – execution
unit) и
устройството
за
управление
на интерфейса
с
оперативната
памет (BIU – bus interface unit).
Основната
задача на
устройството
BIU е да поддържа
командния
FIFO-буфер (опашка
от извлечени
машинни
команди)
винаги пълна.
Това то
постига, като
изпреварващо
спрямо хода
на
изчислителния
процес,
извлича от
оперативната
памет
машинни
команди на текущата
програма и ги
поставя в
командния
буфер. При
завършване
изпълнението
на текущата
команда в
операционното
устройство,
по силата на
командния
цикъл, се
заявява
следващата
команда. Тя
обаче вече се
намира на върха
на командния
буфер и може
непосредствено
да бъде
декодирана и
да започне
нейното
изпълнение.
Докато
изпълнителното
устройство е
заето с
новата
операция,
устройството
за
управление
на
интерфейса
попълва
изпразнената
част от
командния
буфер. Ако по
време на
изпълнение
на
операцията
на операционното
устройство
са
необходими
данни от оперативната
памет или
иска да
запише данни
там, то
процесът на
изпреварващо
доставяне на команди
се прекъсва и
BIU изпълнява
цикъл на обръщение
към паметта,
заявен от
операционното
устройство.
След това
отново
възобновява
процеса на
изпреварващо
доставяне на
команди.
Такова
припокриване
във времето
на етапите
доставка на
команда (ДК) и
изпълнение
на операция
(ИО),
практически
напълно изключва
времето за
доставка на
командите от оперативната
памет от
сумарното
време за изпълнение
на
програмата
(вижте
по-долу фигура
5.3.3). Без да
изпадаме в
подробности, тук
ще обърнем
внимание
само на
факта, че този
асинхронен
начин на
съвместно
функциониране
на 2
устройства
поражда нов
елемент в
структурата
на процесора
– командния
FIFO-буфер.
Съвместяването
(запаралелването)
във времето
на работата
на отделните
етапи от
командния
цикъл и
ролята на
необходимата
за целта
буферна
памет са
подробно
разгледани в глава 6 на
тази книга.
2. За да
бъде по-лесна
реализацията
на принципа
за
разпределено
управление
на операционните
устройства,
се прилагат
два подхода:
·
Подход
за минимизиране
на
множеството
изпълними
операции, при
запазване на
функционалната
му пълнота. В
резултат са
развити така
наречените RISC-системи
(Reduce Instruction Set Computer –
компютър със
съкратен
набор
команди) ;
·
Пълна
хардуерна
реализация
на управляващите
микропрограми.
Има се
предвид
апаратна
реализация
на
операционните
автомати във
вид на
комбинационни
схеми. Като
пример за такава
реализация
можем да
посочим на
читателя
случая със
схемните
умножители
(вижте пункт
3.2.5.5, а така
също книга
[2], фигура 4.12),
схемните
делители (пункт 3.2.9.3 и пункт 3.2.9.4),
съвременните
изчисления
на
елементарни функции
и др.
В комбинация тези два подхода водят до значително съкращаване обема на микропрограмната управляваща информация, значително повишаване на производителността в следствие минимизиране на времето за изпълнение на операциите но и значително нарастване обема на апаратните разходи.
3. Наличието
на етапност в
тялото на
командния
цикъл, в
комбинация с
инвариантността
на тази
етапност
относно
конкретните
операции (команди),
създава
възможността
за неговата конвейерна
организация.
Като имаме
предвид
отделните
етапи, през които
преминава
изпълнението
на една операция
(команда) и
като имаме
предвид, че
тази етапна
последователност
се повтаря по
силата на
логиката на
командния
цикъл, идеята
за
конвейерна
организация
възниква
естествено, а
нейните ползи
стават
очевидни.
Същността на
ползите се
състои в
изпреварващо
зареждане на
конвейера с
команди от
една страна и
отпадане от
командния
цикъл на
задължението
му да управлява
изпълнението
на самите
операции.
Грижа за
изпълнение
на вече
доставените
команди е на
самия
конвейер. За
командния
цикъл остава
само грижата
за командния
буфер, който следва
да бъде пълен
с подготвени
машинни команди
– вижте
следващата
фигура:
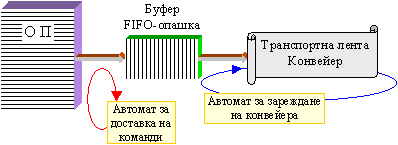
Фиг.
5.3.3. Асинхронни
безкрайни
циклически
процеси след
декомпозиция
на командния
цикъл
Може
да се твърди,
че в
структурата
на конвейера
в даден
момент са
заредени за
“едновременно”
(паралелно)
изпълнение няколко
команди.
Интересното
е, че във
вътрешността
на конвейера
те се намират
в различни
стадии на
завършеност.
Може да се
твърди, че
конвейерът е
генератор на
своеобразен
вид
паралелизъм.
Естествено е
при това да
очакваме
повишена
производителност.
Конвейерната
организация
е възможна за
дадена
последователност
от операционни
автомати, ако
те имат една
обща характеристика
– получават
резултатите
си за едно и
също време.
Последното
изискване се
налага, тъй
като
конвейерната
организация
предполага синхронен
темп на
управление
(вижте книга
[3], пункт 8.4).
Следва да
отбележим, че
конвейерът е
един тип нова
структурна
единица,
синтезът и управлението
на която
изисква нови
методи.
Искаме
да уведомим
читателя, че
изчерпателни
сведения за
конвейерната
организация
той може да
получи от книга [5],
която е
посветена
тази тема.
Конвейерната
организация,
като метод за
управление
на
изчислителния
процес, може
да се
разглежда на
различни
нива. На ниво
логически
възли
конвейерната
организация
беше
разгледана в пункт 3.8.3
на тази
книга. Това
ниво на
детайлизация
се нарича още
ниво на микрооперациите.
Конвейерната
организация
на ниво
устройства е
още
организация
на ниво
машинни
команди.
4. Съвременните
технологии
пораждат
нови структурни
изменения и
правят
възможни нови
видове
организация
на изчислителния
процес.
Най-напред ще
споменем
подхода на
апаратното
насищане с
функционални
устройства
(вижте пункт
3.8.4). Процесори,
чиято
структура се
характеризира
по този
начин, са
известни с
наименованието
суперскаларни.
Процесорите
се наричат
скаларни, тъй
като тяхната
структура
все още
съдържа само един
конвейер.
Апаратното
насищане с
функционални
устройства
(схеми) се
реализира в конвейерното
ниво,
съответстващо
на етапа ИО -
изпълнение
на
операцията
(вижте
по-горе фигура
5.3.1). В това ниво
се
реализират
няколко
независими
АЛУ,
обикновено
за работа с
фиксирана и с
плаваща
запетая.
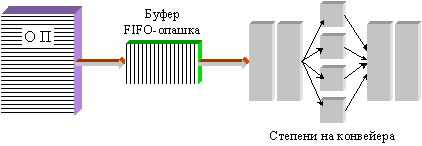
Фиг.
5.3.4. Насищане
на отделна
степен в
конвейера с операционни
устройства
Ясно е, че наличието на няколко функционални устройства в отделна степен на конвейера създава възможността за тяхното паралелно функциониране. Ако тази възможност се реализира, естественото последствие за конвейера се изразява в необходимостта от увеличаване темпа на неговото захранване с команди. Увеличаване на темпа на конвейера означава в крайна сметка повишена производителност.
5. Паралелната
организация
на ниво
машинни команди
чрез
конвейеризация
на архитектурата
и апаратното
й насищане с
функционални
устройства
увеличава
производителността
на процесора
средно до 10
пъти. Практическите
необходимости
от висока производителност
обаче са
много
по-големи. Ето
защо са
разработени
и
продължават
да се разработват
нови
алгоритми за
откриване и пораждане
на
паралелизъм.
Такъв
паралелизъм
се търси на
ниво процеси,
на ниво
задачи и на ниво
данни.
Оползотворяването
на една или друга
форма на
паралелизъм
се постига
чрез нови
езици за
паралелно
програмиране,
а така също и
чрез
разнообразни
паралелни
архитектури,
които
най-общо
можем да
обединим под
наименованието
паралелни процесори.
От изключително
значение за
оползотворяване
на формите на
паралелизъм
е
организацията
на
комуникациите
в системите.
Следващият
раздел е:
5.3.1
Същност на
допълнителните
организационни
принципи.
Паралелизъм