Последната актуализация на този раздел е от
2020 година.
5.3.2
Конвейерна организация на изпълнението на машинните команди
В предидущия
пункт кратко характеризирахме организационния принцип на съвместените операции.
Пояснихме, че в него се имат предвид две различни разбирания – за паралелизъм и
за конвейеризация. Освен това пояснихме, че подходът на разпределено управление
разцепва командния цикъл, опростява го и в същото време, въвеждайки
конвейерната организация на ниво машинни команди, при което обуславя
необходимостта от буферна памет за команди (вижте фигура
5.3.3). Тази необходимост, както значението, структурата и
функционирането на този вид памет са подробно дискутирани още в глава 6, §6.3 и пункт 6.3.1, на тази книга. Тук ще се
спрем върху същността на конвейерната организация на изчислителния процес на
ниво машинни команди и проблемите, които тя поражда.
А) Конвейер и
оценка
За
да илюстрираме как този принцип се реализира в структурата на процесора от
фигура 5.1.3, ще приемем някои конкретни параметри за архитектурата му: ще
приемем например, че той съдържа 32 регистъра с общо предназначение (R0, R1, R2
,…, R31); още 32 регистъра за числа с плаваща запетая (FR0, FR1, FR2 ,…, FR31)
и брояч на командите ПБ. Ще считаме, че множеството изпълними за този процесор
операции включва типичните аритметически и логически операции, както и операции
с плаваща запетая. Ще считаме, че операндите за тези операции ще бъдат търсени
(адресирани) само в регистровата памет, а нейното обслужване (запис/четене) ще се
постига чрез операции за трансфер на данни. Ще приемем още съществуването на
операции за управление на прехода и някои системни операции. Ще считаме, че
операционното устройство е такова, че операциите в него се изпълняват за един
такт, т.е. функционирането му съответства на разбирането за RISK-процесори. При
това положение приемаме, че в командния цикъл последователно следват 4 етапа:
·
ДК – доставяне на командата по адреса, подаван от програмния брояч (от
паметта се прочита и доставя поредната машинна команда) ;
·
АО – декодиране (анализ) на командата / прочитане на операнди от регистровата
памет ;
·
ИО – изпълнение на операцията / изчисляване на действителен адрес в
оперативната памет ;
·
ФР – фиксиране на резултата и неговите признаци / обръщение към оперативната
памет.
Работата на конвейерите най-често се представя чрез особен вид времедиаграми, позволяващи да се проследят етапите на отделните команди в отделните тактове и тяхното взаимно разположение. Ще използваме тази техника за да представим и оценим изпълнението на един програмен участък при не конвейерно, т.е. последователно изпълнение на командите:
|
Номер на такта: |
Т1 Т2 Т3 Т4 |
Т5 Т6 Т7 Т8 |
Т9 Т10 Т11 Т12 |
Т13 Т14 Т15 Т16 |
|
Команда № r |
ДК АО ИО ФР |
|
|
|
|
Команда № r+1 |
|
ДК АО ИО ФР |
|
|
|
Команда № r+2 |
|
|
ДК АО ИО ФР |
|
|
Команда № r+3 |
|
|
|
ДК АО ИО ФР |
Фиг. 5.3.2.1. Времедиаграма
на последователно изпълнение на команди
Ще приемем, че продължителността на отделните последователни етапи е както следва: 50[ns], 50[ns], 60[ns], 50[ns]. Това е времето за което се превключват комбинационните схеми в отделните степени на конвейера. Както се вижда времето в третия такт е завишено с 10[ns]. Има се предвид различната сложност на алгоритмите за изпълнение на отделните операции. Към времето на отделните тактове следва да добавим и времето за запис на междинните резултати в тригерите на регистрите фиксатори в отделните степени на конвейера – примерно 5[ns]. Така общото време за изпълнение на 4 последователни команди при синхронен темп на управление, разпределено в 16 такта с продължителност 65[ns] всеки, ще бъде равно на 1040[ns].
Алтернативната организация на изчисленията е конвейерната. При 4-тактов цикъл за изпълнение на командите конвейерът ще има 4 степени, всяка от която ще се управлява от микрокода в съответния такт на микропрограмата на изпълняваната операция. Конвейерната структура е представена обобщено на следващата фигура. Вижда се, че микрокомандите на отделните машинни команди са разположени в опашките за всяка степен косо (с изоставане), т.е. според такта, в който ще управляват операционните устройства.
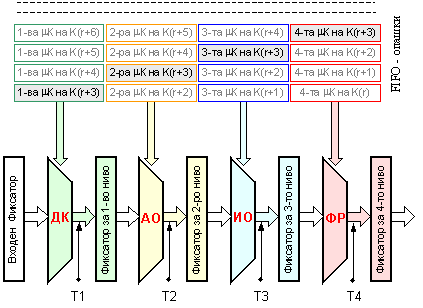
Фиг. 5.3.2.2. Структура на 4-степенен конвейер
Като приемем, че на всеки такт в конвейера се зарежда нова команда, схемата във времето би изглеждала по следния начин:
|
Номер на такта: |
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
|
Команда № r |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
Команда № r+1 |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
Команда № r+2 |
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
Команда № r+3 |
|
|
|
ДК |
АО |
ИО |
ФР |
|
Фиг. 5.3.2.3. Времедиаграма на конвейерно изпълнение на команди
От схемата се вижда, че в четвърти такт първата команда завършва своето изпълнение с фиксиране на резултата и в същото време на входа на конвейера постъпва четвъртата по ред команда. Резултатът на последната ще бъде фиксиран в края на 7-ия такт. Така общата продължителност на изчислението от 4 последователни действия протича за 7 такта или общо за 455[ns]. Сравнението между двата вида организация може да се оцени с помощта на отношението 1040/455»2,3. Отношението на броя на тактовете между сравняваните организации: 16/7, има същата стойност и е известно още като коефициент CPI (clock cycles per instruction).Така за представения пример можем да твърдим, че конвейерният вид организация повишава производителността на процесора повече от 2 пъти, при същите по бързодействие логически схеми. Този резултат е толкова добър, че конвейерната организация не може да не бъде използвана в реалните процесори.
Конвейерът
и организацията на непрекъснато зареждане в него на последователни команди
обаче не е без проблеми. Съществуват редица реални последователности от
команди, за които тази организация се оказва неподходяща, тъй като опитвайки се
да я приложим, възникват ситуации, които се наричат конфликти.
В резултат конфликтите водят до нарушаване на тази организация и тогава
производителността се понижава. Съществуват три класа конфликти:
1.
Структурни конфликти. Възникват във връзка с апаратните ресурси на конвейера,
когато същите не поддържат всички възможни комбинации от команди желани за
зареждане в конвейера ;
2.
Конфликти по данни. Възникват в случаите, когато изпълнението на една
команда зависи от резултата, който получава предидущата команда ;
3.
Конфликти по управление. Възникват при конвейеризация на командите за управление
на прехода, чието изпълнение изменя съдържанието на програмния брояч.
Конфликтите
в конвейера предизвикват неговото спиране,
т.е. преустановява се зареждането и пробутване (изпълнението) на командите (pipeline
stall). Конфликтите изискват изменение в организацията на изчислителния
процес. Като цяло тя си остава конвейерна, но обогатена с действия, изпълняващи
се само в тези извънредни ситуации. Така например, ако дадена команда причини
спиране на конвейера, то всички следващи след нея команди също спират
изпълнението си. Ако е възможно, конвейерното изпълнение на следващите команди
може да продължи, но без зареждане на нови команди в конвейера. Така те
“изпреварват” спрялата команда, като я заобикалят.
Б) Структурни конфликти и подходи за тяхното
минимизиране
Принципът за съвместено изпълнение на командите в общия случай изисква конвейеризация на функционалните (операционните) устройства и дублиране на ресурсите за разрешаване на всички възможни комбинации от команди в конвейера. Ако някаква комбинация от команди не може да бъде приета поради конфликт за ресурси, то говорим че в процесора има структурен конфликт. Най-типичен пример са процесорите с не напълно конвейеризирани функционални устройства. Причината се състои в това, че поради сложен алгоритъм или поради компромис с обема на апаратните разходи, конструкцията на такова устройство е реализирана въз основа на последователния микроалгоритъм, при което времето за неговото изпълнение се измерва с няколко синхро такта на тактовата последователност, синхронизираща работата на конвейера. В този случай, последователни команди, които използват това устройство, не могат да бъдат зареждани в него на всеки конвейерен такт.
Друга възможност за поява на структурни конфликти е свързана с недостатъчното дублиране на някои ресурси, което от своя страна пречи на изпълнението на произволна последователност от команди в конвейера и води до неговото спиране. Например, процесорът може да има само един порт за запис в регистровата памет, но при определени обстоятелства е възможно конвейерът да генерира и пожелае да изпълни два записа в един такт. Това е също структурен конфликт. Ясно е, че тази конструкция ще наложи спиране на конвейера, тъй като ще му се наложи да изчака освобождаването на изходния порт, тъй като ще бъдат изпълнени два последователни записа.
Структурни конфликти възникват още в процесори, които имат обща памет за данни и за команди. В този случай е възможен конфликт, когато една команда изисква обръщение към паметта за доставка на данни, когато по същото време от нея се извлича някоя следваща команда. Ситуацията може да се разреши със спиране на конвейера (pipeline stall) до завършване на завареното обръщение.
Описаните ситуации, в които възниква временен период на бездействие за конвейера, наричаме конвейерно мехурче (pipeline bubble). Това е метафора, с която изразяваме престоите във времето по хода на изчислителния процес. Вмъкване на мехурче или такова спиране на конвейера може да се постигне чрез прекратяване достъпа на тактовите импулси към фиксаторите във всички негови нива (вижте книга [2], фигури 8.4.2 и 8.4.3 или по-горе фигура 5.3.2.3).
При всички други обстоятелства, процесорът без структурни конфликти винаги ще се характеризира с изпълнение на командите за по-малък брой тактове. Естествено възниква въпросът защо конструкторите допускат наличието на структурни конфликти? За това могат да се изтъкнат две причини:
· Стремеж към понижаване на цената и ;
· Намаляване на закъсненията в устройствата.
Конвейеризацията на всички функционални (операционни) устройства може да се окаже много скъпа. Процесори, които допускат например две обръщения към паметта в един такт, трябва да имат памет с удвоена пропускателна способност. Обикновено това се постига с прилагане на така наречената Харвардска архитектура – разделни буферни памети за команди и за данни или с двупортова памет. Аналогично например е твърдението за напълно конвейеризирано устройство за деление на числа с плаваща запетая (вижте фигура 3.8.3.8). В този случай на реализация се изисква огромно количество градивни логически елементи. Ако структурните конфликти не възникват много често, то може би не си струва да се плаща така скъпо за това те да бъдат преодолявани. Като правило, може да бъде разработено неконвейерно, или не напълно конвейерно функционално устройство, което да има общо закъснение по-малко от това на напълно конвейерното. Естествено използването на такова устройство в отделна степен на конвейера изисква понижаване на темпа за управлението на последния. Такъв пример представляват някои реални устройства с плаваща запетая в процесори на CDC или MIPS например, в които вместо пълна конвейеризация е предпочетено апаратно-схема реализация.
В) Конфликти по
данни, спиране на конвейера и заобикалящи механизми
Един
от факторите, който оказва съществено влияние на производителността на конвейерните
системи, представляват логическите зависимости между командите. Тези
зависимости в голяма степен ограничават потенциалния паралелизъм в съседни
операции. Степента на влияние на тези зависимости се определя от
характеристиките на програмата, а така също от архитектурата на процесора (от
структурата за управление на командния конвейер и от параметрите на
функционалните устройства). Конфликтите по данни възникват в случите, когато
конвейерната обработка променя реда за обръщение към операндите, в
сравнение с последователната обработка.
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
|
ADD R1,R2,R3 |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
|
|
SUB R4,R1,R5 |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
|
AND R6,R1,R7 |
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
OR R8,R1,R9 |
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
Read |
|
Write |
|
|
XOR R10,R1,R11 |
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
Read |
|
Write |
Фиг. 5.3.2.4. Илюстрация на
конфликт по данни
В представената схема е записана последователност от 5 команди, указващи на действията събиране, изваждане, логическо И, логическо ИЛИ и логическа неравнозначност. Прието е изпълнението на операциите да се разбира според следните означения:
R1 := (R2) + (R3)
- сумата от съдържанията на
регистър R2 и R3 се записва в регистър R1 ;
R4 := (R1) - (R5)
- разликата от съдържанията на R1
и R5 се записва в R4 ;
R6 := (R1) Ç (R7) - поразрядната конюнкция от съдържанията на R1 и R7 се
записва в R6;
R8 := (R1) È (R9) - поразрядната дезюнкция от съдържанията на R1 и R9 се
записва в R8;
R10 := (R1) Å (R11) - поразрядната сума от съдържанията на R1 и R11 се записва
в R10.
Това
което се вижда е, че получената след първата операция сума, се използва като
първи операнд във всички следващи операции. Команда ADD записва своя
резултат в регистър R1,
а команда SUB чете съдържанието на този регистър като първи операнд. За
съжаление, както може да се види в конвейерната схема по-горе, прочитането на
регистър R1 от тази команда се реализира преди предидущата команда да е
записала актуалния резултат! Аналогично е положението и със следващата команда AND.
Ако не се вземат мерки за предотвратяване на този конфликт, командата SUB ще
прочете и използва неправилна стойност. В същност стойността, която ще
използва команда SUB, е неопределена – въпреки, че можем да предположим, че в
регистър R1 би се съхранявала някаква стойност получена от команда, предхождаща
команда ADD, това не винаги е така. Ако например възникне прекъсване
между командите ADD и SUB, то команда ADD ще завърши
своето изпълнение напълно и в регистър R1 ще се запише нейният резултат.
Тогава, след връщане от прекъсване команда SUB ще използва правилна
стойност. Да се разчита обаче на подобно непрогнозирано поведение в системата е
неприемливо.
Проблемът, който се поставя в този пример, може да бъде разрешен с помощта на достатъчно проста апаратна техника, която се нарича транзитно прехвърляне на данни (data forwarding), или заобикаляне, обхождане (data bypassing), или още окъсяване (short-circuiting). Както се вижда наименованията са няколко, но същността е една – резултатът от изпълнението на дадена операция, който се получава в изходния регистър на АЛУ, винаги се подава назад отново на неговия вход. Ако апаратурата открие, че предидущата операция на АЛУ записва резултат в регистър, който съответства на източника на операнда за следващата операция на АЛУ, то логическите схеми за управление избират в качеството на вход за АЛУ резултатът, който постъпва по веригата за заобикаляне, а не стойността, която е прочетена от регистровата памет. Изказаното правило представлява техниката за заобикаляне и се илюстрира със структурата, представена на следващата фигура 5.3.2.5. Тази техника може да бъде обобщена и резултатът да се изпраща за запис (фиксиране) направо в онова функционално устройство, което се нуждае от него. Така резултатът от изхода на едно устройство се “препраща” на входа на друго устройство.
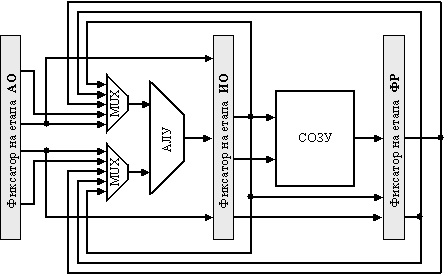
Фиг. 5.3.2.5. Конвейерна структура със “заобикалящи” (транзитни) връзки
В1) Класификация на конфликтите по данни
Конфликт възниква на всяко място в програмата, където има зависимост между командите, които като са записани достатъчно близко една спрямо друга, съвместяването на операциите се осъществява фактически при тяхната конвейеризация. Както вече показахме по-горе (вижте фигура 5.3.2.4), при такъв конфликт е възможно да се измени реда за обръщение към операндите. За разлика от този пример, в който конфликтът става с регистрови операнди, конфликт е възможен още поради зависимост на двойка команди, които изпълняват операции четене или запис в една и съща клетка на оперативната памет. Ако обаче при реализация на достъпа до паметта заявените обръщения се изпълняват строго в реда, в който са възникнали, то появата на такъв тип конфликти ще бъде предотвратена.
Известни са три възможни конфликта по данни в зависимост от реда на операциите четене и запис. Ще разгледаме две команди – команда №q и команда №k, при това ще приемем, че команда №q предхожда команда №k (в текста на програмата). Възможни са следните конфликти:
· RAW (read after write) – четене след запис. При своето изпълнение команда №k се опитва да прочете операнд от източник на данни, преди предхождащата я команда №q да е записала там актуалния резултат. По този начин команда №k може да получи некоректна стара стойност. Този вид конфликти е най-често срещания, а тяхното преодоляване се реализира чрез механизма на транзитните връзки, който разгледахме вече.
· WAR (write after read) – запис след четене. Команда №k се опитва да запише резултат в приемник на операнд преди неговото съдържание да е прочетено от команда №q. Така вместо необходимата стойност, команда №q ще работи с актуализираното съдържание и ще получи некоректен резултат. Такива конфликти могат да възникнат в системи, които допускат изпълнение на команди не в реда, в който те са разположени в текста на програмата. В същото време, в системи с централизирано управление на потока от команди, такива конфликти като правило не настъпват, тъй като те осигуряват правилния ред на изпълнение на командите.
· WAW (write after write) – запис след запис. Команда №k се опитва да запише операнд в приемник на данни, преди в същия да е записала резултата си команда №q. По този начин записите в приемника за данни се извършват в неправилен ред, при което в него остава записана неподходящата стойност. Този вид конфликти е възможен само в конвейери, записи от които могат да се извършват от много нива, или позволяват изпълнението на дадена команда да продължава дори в случая, когато изпълнението на предидущата е спряно.
В2) Конфликти по данни, водещи до спиране на
конвейера
За съжаление не всички потенциални конфликти по данни могат да се разрешават чрез механизъма на транзитните връзки. Ще разгледаме следната последователност от команди:
|
Команда |
Коментар |
|
LOAD R1, 32(R6) |
R1 := (Mem[(R6)+32]),
зареждане в регистър R1 на съдържанието на клетка от паметта, относително
адресирана спрямо базовия адрес в регистър R6 и отместване D=32. |
|
ADD R4, R1, R7 |
R4 := (R1)+(R7),
сумата от съдържанията на R1 и R7 се записва в R4 |
|
SUB R5, R1,R 8 |
R5 := (R1)+(R8),
разликата от съдържанията на R1 и R8 се записва в R5 |
|
AND R6, R1, R7 |
R6 := (R1)Ç(R7),
конюнкцията от съдържанията на R1 и R7 се записва в R6 |
Ако приемем,
че команда LOAD чете операнда си от регистър R6 във втори такт (АО) и го
записва в регистър R1 в четвъртия такт (ФР), то следва, че следващите 2 команди
ще имат конфликт по данни, тъй като при тяхното конвейерно изпълнение,
съдържанието на регистър R1 няма да бъде правилното. Конфликтът може да бъде
отстранен чрез спиране на конвейерното изпълнение на следващите команди до
момента, когато стане възможно използването на необходимата стойност.
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
T9 |
|
LOAD R1, R6 |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
|
|
|
ADD R4,R1,R7 |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
|
|
SUB R5,R1,R8 |
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
|
AND R6,R1,R7 |
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
Read |
|
Write |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LOAD R1, R6 |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
ADD R4,R1,R7 |
|
ДК |
АО |
stall |
stall |
ИО |
ФР |
|
|
|
SUB R5,R1,R8 |
|
|
ДК |
stall |
stall |
АО |
ИО |
ФР |
|
|
AND R6,R1,R7 |
|
|
|
stall |
stall |
ДК |
АО |
ИО |
ФР |
Фиг. 5.3.2.6. Последователност
от команди със спиране на конвейера
В горната част на представената времедиаграма са изобразени конфликтните тактове. В долната част е показано двутактовото задържане на конвейерното изпълнение на потока команди, в резултат на което конфликтите са отстранени и командите ще получат правилни резултати. Логиката на задържането се състои в това, че етапът на формиране на адреса на операнда и неговото прочитане (АО) да се получи винаги след етапа за фиксиране на резултата (ФР).
Решение за спиране на конвейера взема специална апаратна схема, която следи и открива този вид конфликти. Апаратурата за вътрешна блокировка на конвейера (pipeline interlock) осигурява коректното изпълнение на този вид конфликти. Апаратурата спира конвейера за последователността от команди, започвайки от командата, която иска да използва данните в онзи момент, когато предидущата команда, е в процес на тяхното създаване. Така се появява мехурче в конвейерния процес, точно така както в случая на структурни конфликти.
В3) Планиране по време на компилиране
отстраняването на конфликти по данни
Много от видовете спирания на конвейера могат да се случват достатъчно често. Например, за реализация на оператора за присвояване A=B+C, един компилатор най-вероятно би генерирал следващата последователност от машинни команди:
LOAD R1, B R1:=(MemB) ;
LOAD R2, C R2:=(MemC) ;
ADD R3, R1, R2 R3:=(R1)+(R2) ;
STORE A, R3 MemA:=(R3) .
Конвейерното изпълнение на този линеен програмен участък е изразено чрез следващата времедиаграма.
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
T9 |
T10 |
T11 |
|
LOAD R1, B |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
|
|
|
R1=B |
|
|
|
|
|
|
|
|
LOAD R2, C |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
|
|
|
R2=C |
|
|
|
|
|
|
|
ADD R3,R1,R2 |
|
|
ДК |
stall |
stall |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
|
Read R1,R2 |
|
R3=S |
|
|
|
|
STORE A, R3 |
|
|
|
|
|
stall |
stall |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
|
Read R3 |
|
|
Фиг. 5.3.2.7. Конвейерно изчисление на израза A=B+C
Очевидно е, че изпълнението на команда ADD следва да бъде преустановено дотогава, докато не стане достъпен в регистър R2 от СОЗУ и операндът C. Същото закъснение трябва да се наложи и на следващата команда за запис, която трябва да изчака фиксирането на сумата S=B+C в регистър R3.
За този елементарен пример компилаторът няма да може да облекчи ситуацията, но в редица по-общи случаи той е в състояние да реорганизира последователността от команди така, че да се избегне спирането на конвейера. Тази техника, наричана планиране на зареждането на конвейера (pipeline scheduling) или още планиране на потока команди (instruction scheduling), е използвана още в началото на 60-те години на миналия век, но тя се практикува и усъвършенства масово едва в 80-те години.
Ще разгледаме класически пример, който читателят може да намери в много литературни източници. Въпросът е, как да се проведат изчисленията за следните два оператора за присвояване:
A = B+C ; D = E-F ;
Вижда се, че между двата математически израза няма връзка. Ще приемем още, че операндите A,B,C и D, се намират в оперативната памет и тяхното зареждане в регистър на СОЗУ отнема един такт. За всеки операнд е определен отделен регистър. Необходимо е да се състави такъв машинен код за тези изчисления, при който няма да настъпи спиране на конвейера. Нека разгледаме следната естествена последователност:
|
Команда |
Коментар |
|
LOAD RB, B |
|
|
LOAD RC, C |
|
|
ADD RA, RB, RC |
Блокировка за 2 такта, поради липса на операнд |
|
STORE A, RA |
Блокировка за 2 такта, поради липса на операнд |
|
LOAD RE, E |
|
|
LOAD RF, F |
|
|
SUB RD, RE, RF |
Блокировка за 2 такта, поради липса на операнд |
|
STORE D, RD |
Блокировка за 2 такта, поради липса на операнд |
Спирането на
конвейера на два пъти за по 2 такта е необходимо за изчакване завършването на
командите за зареждане на вторите операнди, съответно C и F. Ситуацията е
напълно аналогична на показаната по-горе на фигура 5.3.2.7. Така всяка група от
по 4 команди внася закъснение от 4 такта и вместо 11 изчислението изисква 19 такта.
Ще приложим логиката на разместването на командите така щото да бъде отстранена или поне намалена тяхната взаимна зависимост. Ако това е възможно, минимизирането на времето за изчисляване е гарантирано. Въз основа на тази логика е извършено преподреждането на командите от горния текст и на долната времедиаграма е изразен изчислителния процес при новия текст:
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
T9 |
T10 |
T11 |
T12 |
T13 |
|
LOAD RB, B |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
|
LOAD RC, C |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
LOAD RE, E |
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
LOAD RF, F |
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
ADD RA, RB, RC |
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
SUB RD, RE, RF |
|
|
|
|
|
ДК |
stall |
АО |
ИО |
ФР |
|
|
|
|
STORE A, RA |
|
|
|
|
|
|
stall |
ДК |
АО |
ИО |
ФР |
|
|
|
STORE D, RD |
|
|
|
|
|
|
stall |
stall |
stall |
ДК |
АО |
ИО |
ФР |
Фиг. 5.3.2.8. Пример за
оптимизиране на конфликтите от компилатора
Както се
вижда, пълно отстраняване на зависимостите в този пример не е постигнато, но
оптималността на новия текст е безспорна. Команда SUB трябва да изчака
записа на операнд F в регистър RF , а втората команда STORE трябва да изчака записа
на разликата (E-F) в регистър RD. Така закъснението в това изчисление е само 2 такта.
Следва
да отбележим, че използването на 2 различни регистъра за фиксиране на сумата и
разликата, позволява свободното разположение на командите STORE в
текста, т.е. във времето и способства за по-доброто планиране на изчислителния
процес от компилатора. В частност, ако се вземе решение разликата да бъде
фиксирана също в регистър RA , то преди това е задължително употребата на команда STORE,
която ще го освободи, записвайки сумата в паметта. Такова обвързване на
командите във фиксиран ред обаче прави логиката на преподреждането невъзможна.
От тук следва изводът, че планирането на потока команди в конвейера изисква
увеличаване на обема на регистровата памет на процесора. Увеличаване броя на
регистрите с общо предназначение може да се окаже съществено за архитектури,
които зареждат за изпълнение няколко команди в един такт.
Съвременните
компилатори прилагат техниката pipeline scheduling за повишаване
на производителността на конвейера. В тривиалните алгоритми компилаторът просто
планира разпределението на командите в един базов блок (линеен програмен
участък, в който не се съдържат команди за управление на прехода, за изключение
в началото и в края на този участък). Планирането на такава последователност се
осъществява достатъчно лесно, тъй компилаторът “знае”, че всяка команда в блока
се изпълнява, ако се изпълни първата. И така, може просто да се построи граф
(таблица) на зависимостите между командите в участъка и след това същите да
бъдат преподредени с цел да се отстранят или минимизират зависимостите и да се
минимизират конвейерните мехурчета. За прости конвейери тази стратегия е
напълно удовлетворителна. За по-наситени и интензивни конвейери обаче се налага
да се използва значително по-сложни алгоритми за планиране.
За
щастие съществуват методи, чиято апаратна реализация позволява да се промени реда
за изпълнение на командите така, че спиранията на конвейера се минимизират.
Тези методи са получили общото наименование динамична
оптимизация. Основните средства на динамичната оптимизация са :
1.
Разполагане на схемите за
откриване на конфликти в началните нива на конвейера, което позволява на
командата да се придвижва в конвейера до момента, когато реално ще й потрябва
операнд, представляващ резултат на по-предна незавършила изпълнението си
команда. Алтернативен подход представляват схемите за централизирано откриване
на конфликтите още в началните нива на конвейера ;
2.
Буферизация на командите,
очакващи разрешаване на техния конфликт и пробутване (изпълнение) на следващите
логически несвързани команди, които “заобикалят”, минават транзитно покрай
буфера. В този случай командите ще бъдат подавани за изпълнение не в този ред,
в който са подредени в текста на програмата. Апаратурата за управление на
конвейера обаче е длъжна да осигури коректни резултати в съответствие с
алгоритъма на програмата ;
3.
Съответна организация за
комутиране на магистралите (шините и връзките), осигуряваща внасяне на
резултата (междинния) от операцията непосредствено в онзи буфер, който
съхранява логически зависимата команда, задържана по причина на конфликта, или
непосредствено на вход на функционалното устройство до момента, когато този
резултат бъде записан в регистровата памет или в оперативната памет. Последното
се постига чрез така наречените транзитни връзки, подход, който вече
разгледахме.
Друг апаратен
метод за минимизация на конфликтите по данни представлява методът за преименуване на регистрите (register renaming).
Този метод е получил своето име от широко прилагания в компилаторите метод за
преименуване В компилаторите се прилага метод за такова разпределение на
данните, което цели минимизиране на зависимостите при отразяване на обектите в
изходната програма (променливите) върху апаратните ресурси на процесора (клетки
в оперативната памет и регистри с общо предназначение).
При
апаратната реализация на метода за преименуване на регистрите се отделят логически регистри, обръщението към които се
изпълнява с помощта на съответните адресни полета в командата, а така също и физически регистри, които реално съществуват в
СОЗУ на процесора. Номерата (адресите) на логическите регистри динамически
отразяват номерата на физическите регистри. Съответствието се постига с помощта
на таблици на съответствието, които се актуализират след декодирането на всяка
команда. Всеки нов резултат се записва в нов физически регистър. Обаче
предидущото значение на всеки логически регистър се съхранява и може да бъде
възстановено, ако изпълнението на командата трябва да бъде прекъснато поради
изключителни събития или при неправилно предсказан условен адресен
(алгоритмичен) преход.
При
изпълнение на програмата се генерират множество временни регистрови резултати.
Тези временни стойности се записват в регистровия файл заедно с постоянните
стойности. Една временна стойност става нова постоянна стойност, когато завърши
изпълнението на командата и се фиксира нейния резултат. На свой ред
изпълнението на командата завършва, когато всички предидущи команди успешно
завършат изпълнението си според реда си в текста на програмата.
Програмистът
работи само с логическите регистри. Реализацията на физическите регистри е скрита
от него. Както вече отбелязахме, номерата на логическите регистри се поставят в
съответствие на номерата на физическите регистри. Таблиците на съответствието
се актуализират след декодирането на всяка команда. Всеки нов резултат се
записва във физически регистър. Докато не завърши изпълнението на съответната
команда обаче, стойността във физическия регистър се счита за временна.
Методът
за преименуване на регистрите опростява контрола върху зависимостите по данни.
В процесори, които могат да изпълняват командите в ред различен от реда им в
текста на програмата, номерата на логическите регистри могат да станат двусмислени,
тъй като един и същи регистър може да бъде избиран последователно за съхранение
на различни стойности. Но тъй като номерата на физическите регистри са
уникални, те идентифицират еднозначно всеки резултат, с което нееднозначността
се отстранява.
Г) Конфликти по
управление
Конфликтите
по управление могат да предизвикат много по-големи загуби в производителността
на конвейера по сравнение с конфликтите по данни. Когато се изпълнява команда
за условен преход, в зависимост от логическата стойност на проверяваното
условие, тя може да промени или да не промени съдържанието на програмния брояч.
Говорим, че преходът се изпълнява, ако командата зарежда адреса
за преход в програмния брояч и говорим, че не се изпълнява в противен
случай.
Тук
искаме да предупредим читателя, че командите за управление на прехода създават
проблеми още в процеса на тяхното буфериране в кеш-паметта за команди, което налага
техния предварителен анализ по време на изпреварващото им извличане от
оперативната памет. В същност там е казано, че командите за безусловен преход
се изпълняват още в процеса на предварителния анализ и не се буферират.
Последното означава, че те изобщо не достигат до конвейера. Искаме да уведомим
читателя, че тези именно проблеми, са пояснени в глава
6, §6.3 на тази книга.
Известно
е, че най-тривиалният метод за обработка на командата за условен преход (ако тя
въобще попадне в конвейера) се изразява в спиране на придвижването на
следващите я команди в момента, когато при нейното декодиране се разбере, че тя
е такава, до момента, в който тя завършва записа на новия адрес в програмния
брояч. Казаното може да се илюстрира със следната времедиаграма:
|
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
T9 |
T10 |
T11 |
T12 |
|
Условен преход
a |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
|
Следваща команда
+1 |
|
|
ДК |
stall |
stall |
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
Следваща команда
+2 |
|
|
|
stall |
stall |
stall |
ДК |
АО |
ИО |
ФР |
|
|
|
|
Следваща команда
+3 |
|
|
|
stall |
stall |
stall |
stall |
ДК |
АО |
ИО |
ФР |
|
|
|
Следваща команда
+4 |
|
|
|
stall |
stall |
stall |
stall |
stall |
ДК |
АО |
ИО |
ФР |
|
|
Следваща команда
+5 |
|
|
|
stall |
stall |
stall |
stall |
stall |
stall |
ДК |
АО |
ИО |
ФР |
Фиг. 5.3.2.9. Спиране на
конвейера при зареждане на команда за условен преход
Както се вижда в такт Т2 се зарежда следващата команда, но в този такт става ясно, че декодираната в предидущия такт команда е команда за условен преход. В резултат на този факт апаратурата за управление на конвейера взема решение за спиране на зареждането и изпълнението на следващите команди, докато в такт Т4 командата за условен преход не запише в програмния брояч новия адрес a. Едва след това, в такт Т5 започва извличането и изпълнението на следващите команди в конвейера. Така излиза, че изпълнението на командите след условния преход започва на чисто, или със закъснение от 3 такта. Започналото в такт Т2 зареждане на следващата команда се изоставя – актуална се оказва командата, заредена в такт Т5, възможно по адрес a, ако условието за преход е било изпълнено.
Ако спирането на конвейера е за 3 последователни такта при всяка команда за условен преход, то това може да се отрази крайно негативно върху производителността на процесора. Като се има предвид, че командите за условен преход в една програма са около 30% от целия й текст, то конвейерният процесор губи почти половината от производителността си! Така минимизирането на тези загуби се превръща в критически въпрос.
Броят на тактовете, които се губят при условни преходи поради спиране на конвейера за следващите команди, е възможно да бъде намален по два начина:
1.
Чрез ранна проверка на условието
за преход. Под “ранна” разбираме началните степени на конвейера ;
2.
Чрез ранно определяне на адреса
за преход в програмния брояч.
В някои процесори конфликтите по причина на условните преходи причиняват големи загуби на тактове, много повече от показаните в дадения пример, тъй като времето за проверка на условието за преход и изчисление на адреса за преход според съответния метод за адресиране отнема значителен брой тактове. Например, в процесор с отделни степени за извличане и за декодиране на командата е възможно да се появи закъснение на условния преход (продължителност на конфликта по управление), което е най-малко на един такт по-дълго. Закъснението в процесори с дълбоки конвейери имат закъснение на условните преходи от 4 до 7 такта. В общият случай, колкото по-голяма е дълбочината на конвейера, толкова по-големи са закъсненията от команди за условен преход, изчислявани в съответния брой тактове. В същото време ефектът от намаляване на относителната производителност зависи коефициента CPI на процесора. Процесори е високи стойности на CPI могат да имат условни преходи с по-голямо закъснение, тъй като загубената процентна производителност по тяхна причина е относително по-малка.
Г1) Снижаване на загубите при изпълнение на команди за управление на прехода
Има няколко метода за минимизиране на спиранията на конвейера по причина на команди за условни преходи. Тук ще бъдат обсъдени кратко 4 тривиални схеми (алгоритмични), които се прилагат при компилиране на програмите. Някои от тях се прилагат при всички видове команди за преход. В тези схеми предсказването на условните преходи е статично. Читателят може да намери допълнителни обяснения, свързани със статичното и динамично предсказване на преходите, в глава 6, пункт 6.3.1 на тази книга. Същността на статичното предсказване се състои в това, че прогнозата на посоката на условните преходи се фиксират за всяка команда за условен преход за през цялото време на изпълнение на програмата, колкото и пъти програмата да преминава през този условен преход.
1.
Метод на изчакването. Най-простата схема за обработка на командата за условен
преход представлява преустановяване на зареждането на конвейера с команди,
непосредствено следващи командата за условен преход, докато не стане известна
посоката на прехода. Именно тази схема е изразена по-горе на фигура 5.3.2.9 ;
2.
Метод на продължението. По-добра и не толкова сложна е схемата, при която се
приема, че конвейерът продължава да се зарежда с команди, които непосредствено
следват командата за условен преход. В същност това най-често е посоката на
неизпълненото условие (клон “лъжа”). В този случай следва да се вземат мерки да
не се променя състоянието на машината, докато не стане известно действителната
посока на прехода. Ако действителният преход се окаже в посока “истина”, то
конвейерът се изчиства и започва зареждане на команди от клона “истина”.
Конвейерът видимо не е спирал в този случай, но извършените изчисления в него
се оказва, че трябва да бъдат изоставени като непотребни. От момента на
зареждане на нова команда от правилия клон, до получаване на нейния резултат
обаче ще се получи “конвейерно мехурче” с продължителност равна на броя на
степените на конвейера. Изчистването на конвейера от напразно заредените
команди, в случай на неправилно прогнозиран преход, не е задължително –
достатъчно е да бъде забранено фиксирането на получените от тях резултати. Това
е възможно, тъй като стойността на проверяваното условие за преход е вече
известно в такт Т2.
|
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
T9 |
T10 |
T11 |
|
b: Условен преход a |
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
|
|
Следваща команда
b+1 |
|
|
ДК |
АО |
ИО |
|
|
|
|
|
|
|
|
Следваща команда
b+2 |
|
|
|
ДК |
АО |
|
|
|
|
|
|
|
|
Следваща команда
b+3 |
|
|
|
|
ДК |
|
|
|
|
|
|
|
|
¾ ¾ ¾ ¾ ¾ ¾ ¾ |
|
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
|
¾ ¾ ¾ ¾ ¾ ¾ ¾ |
|
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
¾ |
|
Следваща команда
a |
|
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
Следваща команда
a+1 |
|
|
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
Следваща команда
a+2 |
|
|
|
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
Следваща команда
a+3 |
|
|
|
|
|
|
|
|
ДК |
АО |
ИО |
ФР |
Фиг.
5.3.2.10. Обработка
на команда за УП според метода на продължението
в случая на неправилно прогнозиран преход “лъжа”
Както се вижда от горната фигура, след командата за условен преход, конвейерът се зарежда с команди от следващите адреси (b+1), (b+2), (b+3), а това са адреси в клона “лъжа” на условния преход. В такт Т2 става ясно, че този клон е бил неправилно предположен и след зареждане на програмния брояч с новия адрес (адресът за преход) в такт Т4, междинните резултати на погрешно заредените команди се изтриват. Защрихованите полета в горната времедиаграма съответстват на етапите изчистените команди. Изпълнението на командата от клетка (b+1) е стигнало до етап ИО (изпълнение на операцията), а на следващите две – до етапи АО (адреси на операнди) и ДК (доставка на команда) съответно. В тактовете Т5, Т6 и Т7 резултати не се фиксират. В същото време в такт Т5 започва изпълнението на първата команда от адрес (a+1), т.е. от правилния клон, която фиксира резултат в такт Т8. Пропуснатите тактове в този пример са 3.
3.
Съществува алтернативна схема,
която приема да предполага изход винаги по клона “истина”, т.е. приема
преходите винаги изпълняеми. При тази предпоставка след командата за
условен преход се зареждат команди от колона на изхода “истина”. Това разбира
се възможно, ако адресът за преход е изчислен предварително, в резултат на
което са били буферирани команди от така предположения клон на условния преход.
Ако това не е възможно, не остава нищо друго освен да се изчака оценката на
истинската стойност на условието за преход и съответния адрес за преход, който
да бъде зареден в програмния брояч. В последния случай процесът прилича на
този, който изобразихме по-горе на фигура 5.3.2.10.
4.
И на края, четвъртата схема се
нарича схема на задържаните преходи. В тази схема се реализира задържан
на n такта преход,
който се осмисля с помощта на следната рисунка:

Казваме за
командите от 1 до n, че се намират в слотове на задържан преход (във
временни интервали на задържания преход) (branch-delay slot), т.е. след
командата за преход има n на брой слота (гнезда, места). Оптимизацията на
подобен програмния код чрез подходящи правила за компилиране цели да
натовари равномерно и без прекъсвания конвейера. Това се постига чрез
съответно преподреждане на командите и чрез вмъкване в подходящите места на
команди NOOP (няма операция или още празна команда), така щото командите за
преход да не причиняват спиране на конвейера.
На
следващата фигура 5.3.2.11 са изобразени три програмни текста, при които
компилаторът може да планира задържан преход. Горната част на рисунката
представя първоначалната последователност от машинни команди, а в долната част
– последователността, която е получена в резултат на планирането.
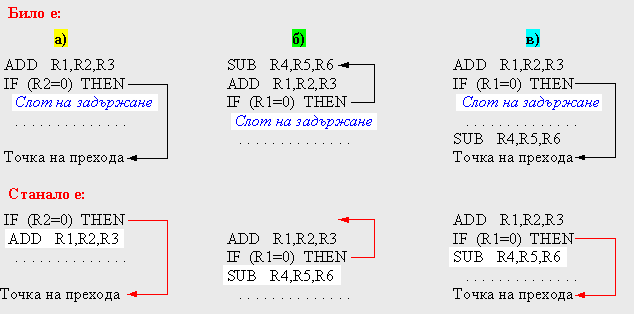
Фиг.
5.3.2.11. Планиране на задържан преход с цел оптимизация на конвейерното
изпълнение
В случай а) от горната рисунка слотът за задръжка се запълва с независима команда, намираща се преди командата за условен преход. Това е най-добрият избор. Другите две схеми б) и в) се прилагат в случаите когато е невъзможно прилагането на схемата по правило а).
В
последователностите от команди в случаите б) и в) използването на съдържанието
на регистър R1 в качеството му на условие за преход възпрепятства преместването
на команда ADD (която записва резултат в същия регистър R1) след
командата за преход. В случай б) слотът на задържане се запълва с командата,
която се намира в целевия адрес за преход на командата за преход. Обикновено се
налага тази команда да бъде копирана, тъй като към нея са възможни обръщения и
от други части на програмата. На схемата б) се отдава предпочитание, когато с
висока вероятност се предполага преходът да е изпълняем, например ако този
преход е преход към входната точка на цикъл.
И
накрая, слотът на задръжка може да се запълни с команда, която се намира между
командата по неизпълняемия преход и командата по целевия адрес на прехода,
какъвто е случаят в). За да бъде подобна оптимизация “законна”, то изпълнението
на команда SUB би следвало да бъде възможно ако преходът не се насочи в
прогнозираната посока. При това се предполага, че команда SUB ще изпълни
ненужно изчисление, но като цяло програмата ще бъде изпълнена коректно. Това ще
бъде така, ако например регистър R4 бъде използван само за временно съхранение
на междинни резултати, когато преходът се изпълнява в непрогнозната посока.
В
следващата таблица по-долу са изразени ограниченията за споменатите три схеми
за планиране на условните преходи и ситуациите, когато това води до положителен
резултат. Компилаторът следва да спазва тези изисквания при подбор на
подходящата команда, с която запълва слота на задръжка. Ако такава команда не
бъде намерена, слотът се запълва с празна команда NOOP.
Таблица 5.3.2.1 Ограничения в схемите за планиране
|
Схема |
Изисквания |
Кога се получава увеличена
производителност |
|
а) |
Командата за условен преход не трябва да зависи от
преместваната команда |
Винаги |
|
б) |
Изпълнението на преместената команда трябва да бъде
коректно, даже ако преходът не бъде изпълняван. Възможно е да се наложи
копиране на командата. |
Когато преходът се изпълнява. Обемът на програмата се
увеличава поради копирането на тези команди. |
|
в) |
Изпълнението на преместената команда трябва да бъде
коректно, даже ако преходът бъде изпълняван. |
Когато преходът не се изпълнява. |
Планирането на
задържаните преходи се усложнява
1.
От наличието на ограничения
върху командите, чието разполагане се планира в слотовете на задръжка ;
2.
От необходимостта да се
предсказва по време на компилиране ще бъде ли условния преход изпълняем или не.
Можество статистически експерименти показват, че ефективността на планирането на преходите с един слот на задръжка (възможно най-елементарната схема) е висока – повече от 60% от слотовете се запълват успешно. При това повече от 80% от така запълнените слотове се оказват полезни за изпълнението на програмите. Това може да ни учуди, тъй като условните преходи се оказват изпълнени примерно на около 53% от случаите. Високият процент оползотворени слотове се обяснява с това, че почти половината от тях се оказват запълнени с команди, които предхождат командите за условен преход, т.е. по схема а), изпълнението на които е необходимо независимо от това изпълнява ли се преходът, или не.
Съществуват известни неголеми допълнителни апаратни разходи за реализация на задържаните преходи. Поради ефекта на задържаните условни преходи, за коректно възстановяване на състоянието на процесора в случай на прекъсване, са необходими няколко програмни брояча (един плюс дължината на задържането).
Г2) Статическо прогнозиране на условните преходи (използване технологията на компилатора)
При статическото прогнозиране (предсказване) на преходите се използват два метода:
1. Метод, при който се изследва структурата на програмата. Изследването на структурата на програмата е достатъчно просто. Първоначално в изходната точка може да се предположи, че всички преходи назад в програмата са изпълняеми, преходите напред по програмата – неизпълняеми. Основавайки се на това предположение прогнозирането на преходите за повечето програми води до ниска ефективност, което означава, че структурата на програмата не е най-информативният признак, по който може да се направи добра прогноза ;
2. Метод, при който се използва информация за профила на изпълнението на програмата, събрана в резултат на предварителни изпълнения на програмата. Това, което прави този подход по-успешен, е фактът, че поведението на преходите при изпълнение на програмата често се повтаря. Всеки отделен преход в програмата често се оказва отместване в една и съща посока, т.е. той е или изпълняем или неизпълняем. Това становище се споделя от много автори на различни публикации.
Тъй като схемите за динамическо прогнозиране на преходите се основават в голяма степен на изложените по-горе идеи и подходи, същите се оказват съществени.
Д) Многотактни
операции и заобикалящи механизми в дълги конвейери
В
разглеждания до момента конвейер етапът ИО (изпълнение на операцията)
продължаваше само един такт (трети по ред в цикъла на командата - Т3). Това
положение обаче е приемливо само за целочислената аритметика, както и за още
някои други групи команди. Операциите върху числа с плаваща запетая не са в
състояние да се вместят в разбиранията ни за еднотактни операции по простата
причина, че техните алгоритми са значително по-сложни, както вече беше показано
в глава 3 на тази книга. Тези операции развиват
своите алгоритми в цяла последователност от тактове, т.е. тяхното изпълнение е
многотактово. Можем да си представим, че машинните команди, реализиращи
аритметиката с плаваща запетая, използват същия конвейер, но с две важни
изменения:
1.
Етапът
изпълнение на операцията (ИО) продължава повече от един такт, разбира се
толкова на брой, колкото е необходимо ;
2.
В процесорът
може да има няколко функционални устройства, работещи с операнди, представени
във форма с плаваща запетая.
При това
допускаме, че могат да съществуват спирания на конвейера, ако заредената за
изпълнение команда или предизвиква структурен конфликт във функционалното
устройство, което тя използва, или съществува конфликт по данни.
Ще допуснем,
че в примерно разглеждания от нас процесор са реализирани четири отделни
функционални устройства.
1.
Основно
операционно устройство за целочислена аритметика ;
2.
Операционно
устройство за умножение на числа с фиксирана и с плаваща запетая ;
3.
Операционно
устройство за изпълнение на операции от тип събиране на числа с плаваща запетая
;
4.
Операционно
устройство за изпълнение деление числа с фиксирана и с плаваща запетая.
При тези
условия структурата на конвейера на процесора наричаме суперскаларна и представата ни за нея има следния
вид:
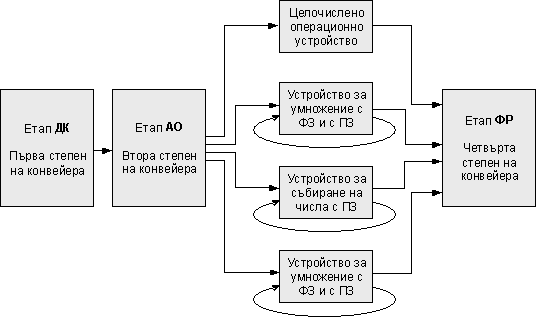
Фиг. 5.3.2.12. Конвейер с няколко
функционални изчислителни устройства (суперскаларен)
През целочисленото операционно устройство
преминава изпълнението на всички команди четене/запис в паметта, команди за
трансфер между регистрите, всички целочислени операции с изключение на
умножение и деление, както и всички команди за управление на прехода. Ако
предположим, че работа на другите функционални устройства е последователно
организирана и цялостната им работа излиза извън равномерния темп на конвейера,
то ние ги определяме като неконвейерни. На това положение съответства
структурата на показания по-горе конвейер. Тъй като етапът на изпълнение на
операцията (ИО) се оказва неконвейерен, то следва, че никоя команда, която
използва функционално устройство, не може да бъде заредена за изпълнение, преди
някоя предидуща команда не напусне степен ИО на конвейера. Нещо повече, ако
една команда не може да постъпи в степен ИО, целият конвейер за тази команда ще
бъде спрян. В действителност междинните резултати е възможно да не използват
степента ИО циклически, както е показано на фигура 5.3.2.12 и тогава тази
степен ще задържа конвейера повече от един такт. Възможно е обобщение на
структурата на конвейера, допускайки конвейеризация на някои степени в
устройствата за работа с плаваща запетая и паралелно изпълнение на няколко
операции. За да опишем работата на такъв конвейер,трябва да определим
задръжките (закъсненията) на функционалните устройства, а така също скоростта
за инициация или скоростта (темпа) за повторение на операциите. Това е
скоростта, с която нови операции от даден тип, могат да постъпват в едно
функционално устройство. Нека за пример предположим следните задръжки в брой
тактове на функционалните устройства и скоростта за повторение на операциите.
Таблица 5.3.2.2
Оценки на функционалните устройства
Устройство
|
Задръжка
|
Скорост на
повторение
|
Целочислено АЛУ
|
1
|
1
|
Събиране с плаваща
запетая
|
4
|
2
|
Умножение (с ФЗ и
с ПЗ)
|
6
|
3
|
Деление (с ФЗ и с
ПЗ)
|
15
|
15
|
При тези параметри структурата на
конвейера се конкретизира както е показано на следващата фигура 5.3.2.13. Както
се вижда, за второ и трето функционални устройства са въведени допълнително по
две регистрови степени, означени (ИО1) и (ИО2), съответстващи на два
допълнителни етапа в изпълнението на операциите. Така също са въведени и
модификации на логическите връзки между фиксаторите в степените (АО)/ИО и
(ИО)/(ФР) на конвейера. Тези изменения до голяма степен съответстват на
препоръките на стандарта за изпълнение на операции върху числа с плаваща
запетая IEEE 854.
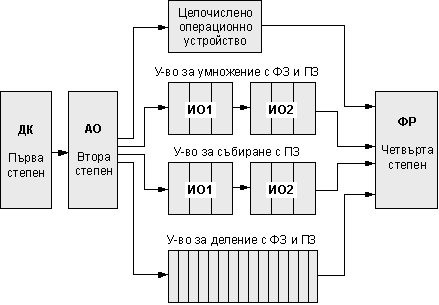
Фиг. 5.3.2.13. Конвейер с многотактови
функционални устройства
Д1) Конфликти и ускорен трансфер в дълги конвейери
Съществуват
няколко различни аспекти за откриване на конфликти и за организиране на ускорен
трансфер на данни в конвейер от показания вид:
1.
Тъй като
функционалните устройства не са напълно конвейерни, в показаната структура са
възможни структурни конфликти. Ще припомним, че структурните конфликти
причиняват спиране на команди, които не могат да бъдат осигурени с ресурси, по
причина на тяхната ограниченост и заетост. Причините за тези конфликти трябва
да се откриват и управлението на конвейера да спира зареждането на команди до
отстраняване на конфликта ;
2.
Тъй като
отделните функционални устройства имат различни времена за изпълнение на
операциите, които реализират, броят на записванията в регистровото СОЗУ може да
бъде повече от единица ;
3.
Възможни са
конфликти от типа WAW (запис след запис), тъй като командите не достигат
конвейерната степен ФР, в онзи ред, в който са били заредени за изпълнение.
Следва да отбележим, че конфликти от тип WAR (запис след четене) са
невъзможни, тъй като четенето на операнди от регистрите винаги става по време
на етап АО (вижте определението) ;
4.
Изпълнението
на командите може да завършва не в онази последователност, в която са били
стартирани (заредени), а това положение предизвиква проблеми с реализацията на
прекъсванията. Реакцията на системата за прекъсване става мудна по причина на
налагащото се изчакване на конвейера.
Ще изложим някои съображения за посочените
по-горе втора и трета ситуации.
Случай на конфликт от тип WAR.
Ако предположим типичния случай, когато регистровото СОЗУ на конвейера с
плаваща запетая има един порт за запис, то последователността от операции с ПЗ,
а така също операция зареждане на число с плаваща запетая (от вида на команда
FXCHG – floating point exchange в процесори на Intel) съвместно с
операции с ПЗ, може да предизвика конфликти в порта за запис. Ще обърнем
внимание, че регистровата памет на устройството за работа с плаваща запетая
често е с последователен достъп (структура LIFO). За да поясним казаното
ще разгледаме следната примерна последователност:
|
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
T9 |
T10 |
|
MULTF F0, F4, F6 |
|
ДК |
АО |
ИО11 |
ИО12 |
ИО13 |
ИО21 |
ИО22 |
ИО23 |
ФР |
|
|
. . . . . . |
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
|
|
ADDF F2, F4, F6 |
|
|
|
ДК |
АО |
ИО11 |
ИО12 |
ИО21 |
ИО22 |
ФР |
|
|
. . . . . . |
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
|
. . . . . . |
|
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
|
|
LOAD F8, 0(R2) |
|
|
|
|
|
|
ДК |
АО |
ИО |
ФР |
|
Фиг. 5.3.2.14. Конфликт при запис в регистровото СОЗУ
Трите команди в примерната времедиаграма
(с други 4-тактни команди), представена на горната фигура, достигат
едновременно в такт Т9 етапа на запис на резултата – ФР. Команда MULTF (умножение с плаваща запетая) се изпълнява във второ
устройство, команда ADDF (събиране с плаваща запетая) – в трето
устройство, а команда LOAD – в първо устройство (вижте по-горе структурата на
конвейера от фигура 5.3.2.13). При наличие на само един порт за запис в
регистровото СОЗУ, процесорът е принуден да организира последователно завършване
на командите. Така, този единствен порт представлява източник на структурни
конфликти. За излизане от ситуацията може да се вземе решение за увеличаване
броя на портовете. Поради това, че тези допълнителни портове ще бъдат
използвани само в такива ситуации, т.е. сравнително рядко, това решение се
счита за неприемливо. В условията на равномерен темп на работа на конвейера е
достатъчен 1 порт, ето защо конструкторите предпочитат да работят с реално
възникващи конфликти. Все пак се прилагат два подхода за преодоляване на този
тип конфликти:
1.
Първият
подход се състои в следното: всяка новозаредена команда се анализира още в
първия етап на нейното изпълнение, с цел да се установи дали използването от
нея на порта за запис не съвпада по време с това на вече изпълняващи се
команди. Ако се установи че има съвпадение, то тогава изпълнението на тази
команда (и на следващите я) се преустановява. Това решение съответства на
описаното вече по-горе, за случая на структурен конфликт в обикновен конвейер.
Схемата за откриване на такъв конфликт обикновено се реализира с помощта на
изместващ регистър ;
2.
Вторият
подход предполага задържане изпълнението на командата, предизвикала конфликта,
в момента, когато тя направи опит да премине в етап ФР – фиксация на резултата.
Предимството на тази схема се състои в това, че не изисква откриване на
конфликта на ранните стадии на изпълнение. В същото време на етап ФР този
конфликт се разпознава елементарно. Реализацията на този подход обаче е
по-сложен от предидущия, по причина на това, че (както се вижда и в горния
пример) задръжките възникват за команди в две различни устройства на конвейера.
Случай на конфликт от тип WAW.
Ако командата LOAD в горния пример беше заредена на един такт по-рано и
имаше за адрес на резултата си регистър F2 (LOAD F2,0(R2)), то би възникнал конфликт от тип WAW, тъй като тогава
тя би изпълнявала запис в регистър F2 на един такт по-рано в сравнение с
команда ADDF. Възможни са два подхода за обработка на този тип
конфликти.
1.
Първият подход се състои в
задържане на командата LOAD до момента, когато командата ADDF
встъпи в етап ФР ;
2.
Вторият подход се състои в
подтискане (скриване) на резултата, който получава командата за събиране ADDF,
в момента на конфликта, т.е. управлението на тази команда се променя така, че
тя не записва своя резултат. В тази ситуация достъпът до регистър F2 на
командата LOAD е свободен и нейното изпълнение завършва. Своят резултат
команда ADDF, или с други думи устройството за събиране може да запише
след време, когато някоя от следващите команди изконсумира съдържанието на
регистър F2. Този подход обаче води до значително усложняване на логиката за
управление изпълнението на следващите операции, където използването на
стойността в регистър F2 може да бъде непредвидимо многократно. Последните
комбинации следва да се откриват от компилатора, а в същото време незаписването
на резултата на операция събиране е свързано с блокиране на устройството за
събиране и невъзможността за неговото по-нататъшно повторно използване.
Възможно е дублиране на командата ADDF на по-късни места в текста на
програмата, което също задължава компилатора.
Предвид сложността на изложените решения, особено на второто, обикновено откриването на този тип конфликти се търси върху ранните стадии на конвейера. Така се налага да се търсят конфликти от една страна между команди с ПЗ, от друга страна между команди с ПЗ и ФЗ, и от трета страна само между команди с ФЗ. С изключение на командите за трансфер (четене/запис) на данни с ПЗ, командите за трансфер на данни между регистрите с ПЗ и ФЗ, командите на аритметиката с ФЗ и на аритметиката с ПЗ са добре разделени. Добрата разделимост се изразява в това, че при достатъчен обем на СОЗУ за работа с ФЗ и ПЗ, конфликтите са изключения. В резултат на това множеството конфликтни команди се намалява по обем и включва преди всичко командите за трансфер на данни с ПЗ и команди за разместване на данни в регистрите за данни с ПЗ. Това облекчаване на управлението на конвейера представлява допълнителен мотив за поддържане на разделни СОЗУ за данни с ФЗ и ПЗ. Основното достойнство на този мотив се състои в това, че удвоеният брой на регистрите от една страна и увеличената пропускателна способност на конвейера от друга страна, се постига без увеличаване на броя на портовете за всеки от регистровите набори.
Ако предположим, че всички конфликти в конвейера се откриват още на етапа ДК, то преди зареждането на командите за изпълнение на операциите във функционалните устройства, трябва да бъдат изпълнени следните 3 проверки:
1.
Проверка за структурни конфликти. Ако такива има, тогава командата се задържа до
освобождаване на функционалното устройство или на порта за запис, ако той е
необходим ;
2.
Проверка за конфликти по данни
от тип RAW. Ако такива има, тогава
командата се задържа докато регистрите, посочени като източник на операнди, са
указани и като регистри за запис на резултат ;
3.
Проверка за конфликти по данни
от тип WAW. Това е проверка за това, че
командите, които се намират в конвейерните станции ИО1 и ИО2, не посочват за
поместване на своите резултати, регистъра за резултата, който заявява
командата. В противен случай придвижването на командата, която се намира в
началната степен ДК, се задържа.
Въпреки, че
логиката за откриване на конфликти за многотактните операции с плаваща запетая
е малко по-сложна, концептуално тя не се отличава от съответната логика за
целочисления конвейер. Същото твърдение се отнася и до ускореното прехвърляне
(ускорения трансфер) на данни. Логиката на ускорения трансфер се основава на
проверката, дали указаният регистър на резултата за конвейерните степени ИО/ФР
представлява регистър на операнд за команда с ПЗ. Ако е налице такова
съвпадение, трансферът на данни се управлява по съответния вход на
мултиплексора (вижте по-горе фигура 5.3.2.5).
Многотактните операции с ПЗ създават също нови проблеми за механизма на
прекъсване.
Следващият раздел е:
5.3.3. Конвейерна и суперскаларна обработка