Последната актуализация на този раздел е от
2020 година.
5.3.3
Конвейерна и суперскаларна обработка
В предидущия
пункт бяха разгледани средствата за конвейеризация на изпълнението на командния
поток, чрез които се осигурява принципа на съвместените операции, когато те са
независими една от друга. Това потенциално съвместяване на изпълнението на
машинните команди представлява паралелизъм на ниво машинни команди.
В този пункт ще разгледаме развитието на идеите за конвейеризация, основаващи се на увеличена степен на паралелизма, който може да се използва при изпълнение на командите. Ще разгледаме методи, които позволяват да бъде намалено влиянието на конфликтите по данни и по управление, а после ще разгледаме възможностите на процесора да оползотвори паралелизма, заложен в програмите. В тази връзка ще разгледаме възможностите на компилаторите да увеличат степента на паралелизъм на ниво машинни команди.
В програмите,
написани на съвременни програмни езици, явно указаният паралелизъм налага
висока отговорност от страна на програмиста. Това е достатъчно трудоемка
процедура и в много случаи той може да сбърка при определяне на операциите,
които се изпълняват едновременно. Програмистът може да пропусне много ситуации,
допускащи паралелност. Едно от многото нежелателни последствия при явното
указване на паралелизма е и това, че програмата може да се окаже много сложна
за модификация. При коригиране и настройка на програма, имаща много на брой
явно паралелни алгоритмични структури, лесно може да се допусне грешка, която
да не може да се забележи.
За избягването
на така посочените проблеми може да се разчита само на автоматичното откриване
на паралелизми. В този случай, паралелизмът, съществуващ в алгоритъма, не е
посочен (деклариран) явно от програмиста. В компилаторите, в операционните
системи и в апаратните средства на процесорите, се включва специален механизъм
за откриване и оползотворяване на паралелизмите. Два са основните методи за
разкриване на паралелизми, съществуващи неявно в програмите - разгъване (развиване, разцепване) на цикъл и
редукция на височината на дърво.
А)
Паралелизъм на ниво команди, планиране зареждането на конвейера и
методика за разгъване на цикли
Всички методи,
които ще бъдат разгледани под тази точка, използват паралелизъм, който е заложен
в последователността от команди (в текста на програмата). Както по-горе вече
определихме, този вид паралелизъм се нарича паралелизъм на ниво команди
(ILP – Instruction Level Parallelism). Степента на паралелизъм в линейна
алгоритмична структура е достатъчно ниска. Така например статистическата оценка
за средната честота на преходите в целочислени програмни текстове е около 16%.
Това означава, че между два прехода се изпълняват средно по 5 команди.
Дотолкова доколкото е възможно тези 5 команди да са взаимно свързани (взаимно
зависими), то степента на конвейерното припокриване, на което можем да
разчитаме във вътрешността на линейния блок, вероятно ще се окаже по-малка от
5. За да се постигне съществено увеличение на производителността, е необходимо
да се използва паралелизмът на ниво команди едновременно за няколко линейни
структури (линейни участъка).
Ще
припомним, че коефициентът за оценка на средния брой тактове за изпълнение на
машинни команди в конвейера - CPI (Clock
Cycles Per Instruction) се формира по следния начин:
CPI на конвейера = CPI на идеалния конвейер +
+ Задръжките по причина на структурните конфликти +
+ Задръжките по причина на конфликтите от тип RAW +
+ Задръжките по причина на конфликтите от тип WAR +
+ Задръжките по причина на конфликтите от тип WAW +
+ Задръжките по причина на конфликтите по управление
Коефициентът
CPI представлява оценка на максималната пропускателна възможност на конвейера,
която е достижима при реализацията му. Намалявайки всяко от събираемите в
горния израз, се постига минимизация на общия коефициент CPI на конвейера. Това
намира израз в увеличаване на пропускателната му възможност, т.е. изпълнение на
повече команди за единица време. Декомпозирайки коефициента CPI по този начин,
можем да посочим как различните оптимизационни методи и подходи влияят на
неговите компоненти. В таблица 5.3.3.1 по-долу е представен списък на основните
методи и съответните ефекти от прилагането им.
Таблица 5.3.3.1 Методи за планиране и ефекти
|
|
Метод |
Постига намаление |
|
1 |
Разгъване на цикъл |
На задръжките по управление |
|
2 |
Базово планиране на конвейера |
На задръжките от тип RAW |
|
3 |
Динамическо планиране с централизирана схема за
управление |
На задръжките от тип RAW |
|
4 |
Динамическо планиране с преименуване на регистрите |
На задръжките от тип WAR и от тип WAW |
|
5 |
Динамическо прогнозиране (предсказване) на преходите |
На задръжките по управление |
|
6 |
Едновременно зареждане на няколко команди |
На идеалния коефициент CPI |
|
7 |
Анализ на зависимостите от компилатора |
На идеалния коефициент CPI и на задръжките по данни |
|
8 |
Програмна конвейеризация и планиране на трасетата |
На идеалния коефициент CPI и на задръжките по данни |
|
9 |
Изпълнение по предположение |
На всички задръжки по данни и по управление |
|
10 |
Динамическо отстраняване на нееднозначности в паметта |
На задръжките от тип RAW, които са свързани с паметта |
Най-лесният и
общ начин за увеличаване степента на паралелизма, който е достъпен на ниво
команди, представлява използването на паралелизма между отделните повторения на
командите в тялото на цикъл. Паралелизмът в тази ситуация се нарича паралелизъм
на ниво итеративен цикъл. За да се поясним нека разгледаме пример.
Представеният FORTRAN-текст изразява последователното изменение на стойностите
на елементите на едномерния масив X, чрез съответното им събиране с елементите
на масива Y:
DO k = 1, 1000, 1
X(k) = X(k) +
Y(k)
END DO
Изразените по същество операции могат да се характеризират като естествено и напълно паралелни във възможността си да бъдат изпълнени едновременно във времето. Всяка итерация в организирания циклически процес е възможно да бъде припокрита от всяка друга итерация, въпреки, че вътре в тялото на така записания цикъл възможността за припокриване е нищожна.
Съществуват няколко метода за превръщане на паралелизма на ниво цикъл в паралелизъм на ниво машинни команди. Същността на тези методи се постига най-вече чрез статично разгъване на цикъла с помощта на компилатора, или чрез динамично разгъване с апаратни средства. По-късно ще разгледаме такова разгъване.
Въпреки,
че в този пункт на нашето изложение смисълът на понятието архитектура на
процесора, е все още неопределено, ще си позволим, в интерес на разглежданата
тема, да употребим нови понятия. Трябва да изтъкнем, че важен алтернативен
метод, използващ паралелизма на ниво команди, се явява методът на векторните машиннио команди. Векторната команда се
нарича така, защото оперира с векторни данни. Тук понятието вектор е
еквивалентно с определеното във векторно-матричната алгебра. Така например, при
наличието на такива команди и типичен векторен процесор, приведеният по-горе
програмен текст може да бъде изпълнен с 4 команди – две команди за зареждане на
векторите X и Y, една команда за векторното събиране и още една команда за
запис на резултата в паметта. Разбира се тези команди могат да бъдат
конвейеризирани на ниво целочислени операции и да имат относително големи
задръжки при изпълнение, но тези задръжки могат да се припокриват. Векторните
команди и съответстващите им по структура векторни процесори заслужават отделно
внимание извън същността на тази книга. На практика идеите за векторна
обработка предшестват методите за използване на паралелизма на ниво команди,
които разглеждаме тук. Последните обаче се налагат в процесорната еволюция по
чисто технологични причини.
А1)
Зависимости
За
да определим какво точно разбираме под паралелизъм на ниво цикъл и паралелизъм
на ниво команди, а така също за количествена оценка на степента на достъпния
паралелизъм, ние трябва да определим първо какво е това паралелни команди и
паралелни цикли. Нека поясним какво е двойка паралелни команди. Две команди
определяме като паралелни, ако те могат да се изпълняват едновременно в
конвейера без задръжки, предполагайки, че условията в конвейера са такива, че
той е с достатъчно ресурси, така че структурните конфликти са изключени. Ето
защо считаме, че ако между две команди съществува взаимна зависимост, то те не са паралелни. Съществуват три типа
зависимости:
·
Зависимости по данни ;
·
Зависимости по идентификатори
(по имена) ;
·
Зависимости по управление.
Команда
№k зависи по данни от команда №j, ако е изпълнено поне едно от следните
условия:
1.
Команда №j изчислява резултат,
който команда №k използва ;
2.
Команда №k е зависима по данни
от команда №n, а команда №n е зависима по данни от команда № j.
Второто
условие означава, че една команда зависи от друга, ако между тези две команди
съществува верижка от зависимости от първия тип. Зависимостта по данни е
инвариантна към дължината на верижката от взаимни зависимости.
Ако
две команди са зависими по данни, то те не могат да се изпълняват едновременно
или напълно съвместено. Зависимостта по данни предполага, че между две команди
съществува верижка от един или няколко конфликта от тип RAW. Едновременното
изпълнение на команди с такива зависимости е възможно в процесори, чиито конвейери
имат апаратни схеми за анализ и блокировка. Тези схеми, а по-точно цялото
управление на конвейера е проектирано така, че да открива конфликтите между
зарежданите команди и да минимизира задръжките, за които вече говорихме в
предидущия пункт. Процесорите без вътрешно схемна блокировка на конвейера
разчитат единствено на правилното програмно планиране на зареждането на
конвейера, което извършва компилатора. Компилаторът обаче не е в състояние да
планира взаимно зависимите команди така, че последните да могат да се
изпълняват напълно съвместено. Ако това той би се опитал на направи, то
програмата би се изпълнявала неправилно. Наличието на зависимости по данни в
последователността от команди отразява зависимостта по данни в първоначалния
текст на програмата, въз основа на който компилаторът е генерирал работния код.
Ефектът от първоначалните зависимости по данни при това трябва да се запазва.
Зависимостите
се явяват свойства на програмите. Дали дадена зависимост ще доведе до откриваем
конфликт и дали даден конфликт ще доведе до реална задръжка на конвейера,
зависи единствено от организацията на последния. Много от методите, които ще
засегнем тук, позволяват заобикаляне на конфликтите, или позволяват заобикаляне
на необходимостта от задържане на конвейера при възникнал конфликт, при
запазване на зависимостта. Значението на зависимостите по данни се изразява в
това, че точно те установяват горната граница на степента на паралелизма, който
вероятно би могло да бъде използван. Наличието на зависимости по данни означава
още, че резултатите следва да се получават в определена последователност, тъй
като обикновено по-следващите команди зависят от резултатите на предидущите,
което е в пълно съответствие със свойството детерминираност (определеност) на
понятието алгоритъм (вижте определението),
чийто израз е всяка програма.
Данните
могат да се предават от команда към команда както чрез регистровата, така и
чрез оперативната памет. Когато данните се предават чрез регистрите,
откриването на зависимостите се улеснява значително, тъй като адресите на
регистрите са записани в командите (въпреки, че този процес става по-сложен ако
се намесват команди за условен преход). Зависимостите по данни, които се
предават чрез оперативната памет, се откриват значително по-трудно, тъй като
два адреса, които външно изглеждат различни, могат да се отнасят за една и съща
клетка. Например, означенията 100(R4) и 20(R6) могат да определят един и същи
адрес, с което още повече се усложнява откриването на зависимостта. Освен това,
ефективният адрес на командата LOAD или на командата STORE може
да се променя от едно изпълнение към друго, например в цикъл, при индексна
адресация, което още повече усложнява откриването на зависимостите. В такъв
случай за такива две команди означенията 20(R4) и 20(R4) ще определят различни
адреси. Ще напомним, че означението например 20(R4) следва да се разбира така:
Mem[(R4)+20]), адрес на клетка от паметта, относително адресирана спрямо
базовия адрес в регистър R4 и отместване D=20. Ще се спрем както на апаратните,
така и на програмните методи за откриване на зависимости по данни, свързани с
клетките на оперативната памет. Методите за компилация със същата цел са много
важни при разкриване на паралелизма на ниво цикъл.
Вторият
тип зависимости в програмите представляват зависимостите по идентификатори.
Този тип зависимости възникват, когато две команди използват едно и също име
(разбирай адрес) или на регистър или на клетка от паметта, но при отсъствие на
предаване на данни между командите. Съществуват два типа зависимости по имена
между команда №k, която предхожда в програмата команда №j.
1.
Антизависимост между команда №k и команда №j възниква тогава, когато
команда №j записва в регистър или клетка на паметта, чието съдържание команда
№k чете и при това се изпълнява първа. Антизависимостта съответства на конфликт
от тип WAR, и откриването на конфликти от този тип означава преподреждане на
изпълнението на двойката команди с антизависимост.
2.
Зависимост по изход възниква, когато команда №k и команда №j записват
резултат в един и същи регистър или в една и съща клетка на паметта. Редът за
изпълнение на тези команди трябва да се съхрани. Зависимостите по изход се
съхраняват чрез откриване на конфликти от типа WAW.
Както
антизависимостите, така и зависимостите по изход представляват зависимости по
имена, за разлика от истинските зависимости по данни, тъй като в тяхното
изпълнение отсъства предаване на данни от едната команда към другата. Това
означава, че командите, свързани със зависимост по имена, могат да се
изпълняват едновременно или могат да бъдат преподредени, ако използваното в
командите име (номер на регистър или адрес на клетка от паметта) се промени
така, че командите престанат да конфликтуват. Преименуването може да бъде
осъществено по-лесно за регистрови операнди и се нарича register renaming – преименуване
на регистрите. Преименуването на регистрите може да се изпълни статически – от
компилатора, или динамично – с помощта на апаратни средства.
Ще разгледаме следния пример:
ADD R1, R2, R3 R1:=(R2)+(R3) - целочислено събиране ;
SUB R2, R3, R4 R2:=(R3)-(R4) - целочислено изваждане ;
AND R5, R1, R2 R5:=(R1)Ç(R2) - поразрядно логическо умножение ;
OR R1, R3, R4 R1:=(R3)È(R4) - поразрядно логическо събиране .
В
тази последователност съществува антизависимост спрямо съдържанието на регистър
R2 между командите ADD и SUB, която може да доведе до конфликт от
тип WAR. Първата команда чете съдържанието на регистър R2 в качеството му на
операнд, а втората – записва в него резултат. Тази зависимост може да бъде
отстранена чрез преименуване на регистъра за резултат на команда SUB,
например с името R6, като след това всички следващи команди, които използват
резултата от команда SUB, бъдат актуализирани с новото име на този резултат.
В примера това следва да се направи само за команда AND. Използването на
регистър R1 в командата OR води както към зависимост по изход от команда
ADD, така и към антизависимост между командите ADD и AND.
Двата типа зависимости могат да бъдат отстранени чрез подмяна на регистъра за
резултата или на команда ADD, или на команда OR. В първия случай
е необходимо да се промени всяка команда, която използва резултата от команда ADD,
преди команда OR да запише своя резултат в регистър R1 (в примера това е
първият операнд на команда AND, намиращ се в R1). Във втория случай, при
замяна на регистъра за резултата на команда OR, всички следващи команди,
използващи нейния резултат, също трябва да бъдат променени. Алтернатива на
преименуването в процеса на компилация представлява апаратното преименуване на
регистрите. Последното може да бъде използвано в случаите, когато възникват
дълги вериги от условни преходи, които не се поддават на анализ от компилатора.
Последният тип зависимост на който се спираме е зависимостта по управление. Тези зависимости определят реда на командите по отношение на командата за условен преход така, щото онези, които не са команди за преход, се изпълняват само тогава, когато следва да се изпълняват. Всяка команда в една програма е зависима по управление от някакво множество условия. В общия случай тези зависимости по управление трябва да се съхраняват (да се помнят). Нека да припомним, че след всяка операция в процесора освен резултат се формира и множеството признаци на резултата. Един от най-простите примери на зависимост по управление, който може да бъде даден, представлява условният оператор с вписаните в клона “истина” оператори:
Оператор S1
if
(условие P1) then
Оператор S2
end if
if
(условие P2) then
Оператор S3
end if
Оператор
S2 е зависим по управление от условие P1, а оператор S3 е зависим по управление
от условие P2 и не зависи от условие P1.
Съществуват две ограничения, свързани със зависимостите по управление:
1.
Една команда, която зависи по
управление от условен преход, не може да бъде поставена в резултат на
преместване преди командата за условен преход, тъй като нейното изпълнение не
може да не бъде управлявано от съответната стойност на проверяваното условие, в
съответствие с логиката на алгоритъма, който програмата реализира. Например, не
е възможно преподреждане на горната структура по начина:
Оператор S1
Оператор S2
if
(условие P1) then
end if
2.
Една команда, която не е
зависима по управление от командата за условен преход, не може да бъде
поставяна след командата за условен преход, така че нейното изпълнение да се
управлява от съответното условие, реализиращо този условен преход. Такава
зависимост също не отговаря на логиката на алгоритъма, изразен чрез
първоначалния текст на програмата. Например, не е възможно преподреждане на
цитираната структура по начина:
if (условие P1) then
Оператор S1
Оператор S2
end if
Ето още един
пример:
ADD R1, R2, R3
R1:=(R2)+(R3)
BEQZ R12,
skipnext ако (R12)=0 то преход в точка <skipnext>
иначе преход към следващата по ред команда.
SUB R4, R5, R6 R4:=(R5)-(R6)
skipnext: OR R7, R1, R9 R7:=(R1)È(R9)
MULT R13, R1, R4 R13:=(R1)*(R4)
В тази
последователност от команди съществуват зависимости по управление. Командата за
изваждане SUB зависи по управление от команда BEQZ, тъй като
изменението в реда на следване на тези команди, ще промени резултата. Ако
команда SUB се премести преди командата за условен преход, резултатът от
командата за умножение MULT няма да бъде същия, както в случая, когато
условният преход е изпълним.
Аналогично,
команда ADD не може да бъде поставена след командата за условен преход,
тъй като тогава ще се промени резултатът от команда MULT, в случая на
изпълним преход. Командата OR не е зависима по управление от условния преход,
тъй като тя се изпълнява независимо от това, дали преходът е изпълним или не.
Тъй като команда OR не зависи по данни от предходните команди и не
зависи от командата за условен преход, тя може да бъде преместена в текста
преди командата за условен преход, което няма да доведе до изменение на
стойностите, изчислявани от тази последователност от команди. Разбира се това
предполага, че команда OR не предизвиква странични ефекти (например
възникване на изключения). Ако искаме да преподредим команди с подобни
потенциални ефекти, то се изисква компилаторът да извърши допълнителен анализ
или да бъде реализирана допълнителна апаратна поддръжка.
Зависимостите
по управление се запазват с помощта на две свойства на конвейера, подобни на
разгледаните в предидущия пункт. Първо, командите се изпълняват в реда,
определен от програмата. Това гарантира, че командата, която предхожда
командата за условен преход, се изпълнява преди прехода. Така команда ADD
в горния пример ще се изпълни преди командата за условен преход. Второ,
средствата за откриване на конфликти по управление или конфликти по условни
преходи гарантират, че командата, която зависи по управление от условния
преход, няма да се изпълни, докато не стане известно направлението на прехода.
В горния пример, команда SUB няма да се изпълни, докато процесорът не
определи, че условният преход е неизпълним.
Въпреки, че
запазването на зависимостите по управление е полезен и лесен начин за
осигуряване на коректността на програмата, сама по себе си зависимостта по
управление не представлява фундаментално ограничение на производителността. Ние
бихме се радвали да изпълним команди, които не следва да се изпълняват,
нарушавайки по този начин зависимостите по управление, ако правейки това бихме
могли да сме сигурни че не нарушаваме коректността на програмата. зависимостта
по управление не представлява критично свойство, което следва да се запазва. В
действителност, двете свойства, които се приемат за критични от гледна точка на
коректността на програмата и които обикновено се запазват чрез зависимостите по
управление, представляват поведение на изключителните ситуации (exception
behavior) и на потока от данни (data flow).
Запазване на
поведението на изключителните ситуации означава, че промените в реда за
изпълнение на командите, не следва да променят условията за възникване на
изключителните ситуации в програмата. Това изискване може да бъде смекчено:
преподреждането на командите не трябва да води до поява в програмата на нови
изключителни ситуации. Следващият пример показва как поддържането на
зависимостите по управление може да запази тези ситуации.
BEQZ R2, L1
LOAD R1, 0(R2)
L1: < . . . . . . . >
В дадения
случай, ако игнорираме зависимостта по управление и поставим командата LOAD
преди командата за условен преход, командата за зареждане на регистър R1 може
да предизвика изключителна ситуация от системата за защита на паметта. Ще
отбележим още, че тук зависимост по данни, която да препятства разместването на
командите BEQZ и LOAD, отсъства, на лице е само зависимост по
управление. Подобна изключителна ситуация може да възникне и при изпълнение на
операция с плаваща запетая. Във всеки случай, ако преходът се изпълнява, то
изключителна ситуация няма да възникне, ако командата LOAD не е
преместена преди командата за условен преход. За да разрешим преподреждането на
командите ние сме длъжни да игнорираме именно изключителната ситуация, ако
преходът не се изпълнява. По-късно ще разгледаме как се вземат решения за
изпълнение при предположение.
Второто
свойство на програмите, което се запазва чрез поддържане на зависимостите по управление,
представлява потокът от данни. Потокът от данни е действителен поток от данни
между командите, които изчисляват резултатите и командите, които използват тези
резултати. Условните преходи правят този поток динамичен, тъй като те
позволяват на данните за конкретна команда, да постъпват от много източници. Ще
разгледаме следната последователност от команди:
ADD R1, R2, R3
BEQZ R4, Line
SUB R1, R5, R6
Line: OR R7, R1, R8
Съдържанието
на регистър R1, което команда OR използва, зависи от това, изпълнява ли
се или не условният преход. Само зависимостта по данни не е достатъчна за да
бъде запазена коректността на програмата, тъй като тя има работа само със
статически ред на четене и запис. По този начин, въпреки че команда OR
зависи по данни както от команда ADD, така и от команда SUB, това
не е достатъчно за коректно изпълнение. При изпълнението на командите трябва да
се запазва потокът от данни: ако преходът не се изпълнява, то команда OR
трябва да използва стойността на R1, която е изчислена от команда SUB, а
ако преходът се изпълнява – стойността на R1, която е изчислена от команда ADD.
Преместването на команда SUB в място преди командата за условен преход
не променя статичната зависимост, но тя определено ще повлияе на потока от
данни и по този начин ще доведе до некоректно изпълнение. При запазване на
зависимостта по управление на команда SUB от условния преход, ние
предотвратяваме “незаконното” изменение на потока от данни. Изпълнението на
команди по предположение и условни команди, които спомагат за решаването на
проблема с изключителните ситуации, позволяват също така да се промени
зависимостта по управление, поддържайки при това правилен поток от данни.
Понякога може да се установи, че отстраняването на зависимостта по управление, не може да повлияе върху поведението на изключителните ситуации, или на потока от данни. Ще разгледаме малка модификация на примерния текст:
ADD R1, R2, R3
BEQZ R12, skipnext
SUB R4, R5, R6
ADD R5, R4, R9
skipnext: OR R7,
R8, R9
Ще
предположим, че ние знаем, че регистърът за резултата R4 на команда SUB
не се използва след командата, която е маркирана с етикета skipnext.
Свойството, което определя дали една стойност ще се използва от следващите
команди, се нарича жизненост (liveness). Това свойство ще
доопределим допълнително. Ако регистър R4 не се използваше в следващите
команди, то изменението на съдържанието му непосредствено преди изпълнение на
условния преход не би повлияло на потока от данни. По този начин, ако не се
използваше регистър R4 и команда SUB не довежда до изключителна
ситуация, ние бихме могли да преместим команда SUB преди командата за
условен преход, тъй като на резултата от програмата това изменение не влияе.
Ако преходът се изпълнява, то изпълнението на команда SUB ще бъде
безполезно, но това няма да повлияе на резултата от програмата. Този тип
планиране на кода понякога се нарича планиране по предположение (speculation),
доколкото компилаторът залага предимно на съответния изход на условния преход.
В дадения случай се предполага, че условният преход обикновено е неизпълним.
Съществуват и по-амбициозни механизми за планиране по предположение.
Механизмите на
задържаните (отложените) преходи могат да се използват за намаляване на
престоите в конвейера, които възникват по вина на условните преходи, и понякога
позволяват да се използва планирането по предположение за оптимизация на
задръжките на преходите.
Зависимостите
по управление се запазват чрез реализация на схема за откриване на конфликт по управление.
Тази схема причинява спиране на конвейера по управление. Тези спирания по
управление могат да бъдат отстранявани или минимизирани с помощта на различни
апаратни и програмни методи. Например, задържаните (отложените) преходи могат
да намалят задръжките, възникващи в резултат на конфликти по управление. Други
методи за намаляване на задръжките предизвикани от конфликти по управление се
отнасят до разгъване на цикли, до преобразуване на условни преходи в условно
изпълнявани команди и планиране по предположение, изпълнявано с помощта на
компилатор или апаратура. По-долу се говори за тях.
А2) Паралелизъм на ниво цикъл – концепции и методи
Паралелизмът на ниво цикъл обикновено се анализира в изходния текст на програмата и в близка до него форма, докато анализът на паралелизма на ниво команди се извършва, когато машинният текст на програмата е вече генериран от компилатора. Анализът на ниво цикъл цели да се изявят зависимостите, съществуващи между операндите, използвани в тялото на цикъла. Така ние ще разглеждаме само зависимости по данни, които възникват, когато даден операнд се записва в една точка и се чете в друга следваща (по-късна) точка. Анализът на паралелизма на ниво цикъл се съсредоточава върху това, зависят ли по данни обръщенията към данните в по-следващата итерация от стойностите на данните, получавани в по-ранната итерация. Ще разгледаме цикъла:
do i=1,100,1
A(i+1) = A(i) + C(i)
//оператор S1//
B(i+1) = B(i) + A(i+1)
//оператор S2//
end do
Ще
предположим, че А, В и С са отделни и не застъпващи се масиви. На практика това
могат да бъдат различни имена на едни и същи масиви или срезове от един масив.
Тъй като масивите могат да се предават в качеството си на действителни
параметри в подпрограма и в процедура, където се съдържа разглежданият цикъл,
определянето на това дали масивите се припокриват или съвпадат, изисква
сериозен анализ на връзките между процедурните елементи в програмата. В дадения
пример зависимостите по данни, които изявяваме, са следните (зависимостите са две
и те са различни): Оператор S1 използва стойност, изчислена от същия оператор
S1, но на по-ранна итерация, тъй като при операция №i се изчислява елемент
А(i+1), чиято стойност се чете по време на следващата итерация №(i+1). Същата
констатация се отнася и за оператор S2 и елементите В(i) и B(i+1). На второ
място, оператор S2 използва стойността А(i+1), която се изчислява от оператор
S1 в текущата итерация. Тези две зависимости се отличават една от друга и имат
различен ефект. За да разберем в какво се отличават, ще предположим, че във
всеки един момент съществува само една от тях.
Ще разгледаме
зависимостта на оператор S1 от по-ранни итерации на S1. Тази зависимост (loop-carried
dependence) означава, че между отделните итерации на цикъла, съществува
зависимост по данни. Нещо повече, тъй като оператор S1 зависи от само от себе
си, последователните му итерации се изпълняват в необходимия ред.
Втората
зависимост (зависимостта на S2 от S1) не се предава от итерация към итерация.
По този начин, ако това е единствената зависимост, няколко итерации на цикъла
биха могли да се изпълнят паралелно, при условие, че всяка двойка оператори в
итерацията се поддържа в зададения ред.
Съществува
трети вид зависимост по данни, който възниква в цикли, както е показано в следващия
пример.
do i = 1,100,1
A(i) = A(i) + B(i)
//оператор S1//
B(i+1) = C(i) + D(i)
//оператор S2//
end do
Оператор S1
използва стойност, която се присвоява чрез оператор S2 в предходната итерация.
В този смисъл съществува зависимост между операторите S2 и S1 между итерациите.
Въпреки тази зависимост, този цикъл може да бъде направен паралелен. Както и в
по-ранния цикъл тази зависимост не е циклическа: нито един от операторите не
зависи сам от себе си, и въпреки че S1 зависи от S2, то S2 не зависи от S1.
Цикълът е паралелен, само ако липсва циклическа зависимост.
Въпреки че в горния цикъл отсъстват циклически зависимости, за да изявим паралелизма, той трябва да бъде преобразуван в друга структура. Тук трябва да направим две забележки:
·
Зависимост от S1 към S2 не
съществува. Ако тя съществуваше, то в зависимостите би се появил цикъл, който
не би бил паралелен. В резултат на отсъствието на други зависимости,
разменянето на двата оператора няма да влияе на изпълнението на оператор S2.
·
В първата итерация на цикъла
оператор S1 зависи от стойността B(i), която е изчислена преди началото на
цикъла.
Тези две забележки ни позволяват да заменим по-горе
представения текст на цикъл със следния:
A(1) = A(1) + B(1)
do i = 1,99,1
B(i+1) = C(i) + D(i)
A(i+1) = A(i+1) + B(i+1)
end do
B(101) = C(100) + D(100)
При този текст
итерациите на цикъла могат да се изпълняват с припокриване, при условие, че
операторите във всяка итерация се изпълняват в зададения порядък. Съществуват
много преобразования от този род, които могат да реструктурират един цикъл при
изявяване на паралелизма.
Основното ни внимание по-нататък ще насочим върху методите за изявяване на паралелизма на ниво команди. Зависимостите по данни в компилираните програми представляват ограничения, които оказват влияние на това, каква степен на паралелизма може да бъде използвана. Смисълът се състои в това, че е необходимо да се подходи към тази граница по пътя на минимизация на действителните конфликти и свързаните с тях задръжки на конвейера. Методите за това стават все по-гъвкави в стремежа да използват целия достъпен паралелизъм при запазване на истинските зависимости по данни в кода на програмата. Както компилаторът, така и апаратурата тук играят своята роля – компилаторът се старае да отстрани или да минимизира зависимостите, докато в същото време апаратурата се старае да предотврати превръщането на зависимостите в задръжки на конвейера.
А3) Основи на планирането на зареждането на конвейера и разгъване на цикли
За поддържане на максимално натоварване на конвейера трябва да бъде използван паралелизма на ниво команди, основаващ се на изявяването на последователностите от несвързани команди, които могат да се изпълняват съвместно в конвейера. За да се избягнат задръжките в конвейера, зависимата команда трябва да бъде отделена от изходната команда на разстояние в тактове, равно на задръжката на конвейера за тази изходна команда. Способността на компилатора да изпълнява подобно планиране зависи както от степента на паралелизъм на ниво команди, което е достъпно в програмата, така и от задръжките на функционалните устройства в конвейера. Тук ще предполагаме задръжките, които са показани в следващата таблица, ако явно не са установени други задръжки.
Таблица 5.3.3.2 Продължителност на задръжките
|
Команда, получаваща резултат |
Команда, използваща резултата |
Задръжка в тактове |
|
Операция в АЛУ с плаваща запетая |
Друга операция в АЛУ с плаваща запетая |
3 |
|
Операция в АЛУ с плаваща запетая |
Запис на число с двойна дължина |
2 |
|
Зареждане на число с двойна дължина |
Друга операция в АЛУ с плаваща запетая |
1 |
|
Зареждане на число с двойна дължина |
Запис на число с двойна дължина |
0 |
Ще предполагаме, че условните преходи имат задръжка от един такт, така че командата, следваща след командата за условен преход, не може да бъде определена в продължение на един такт след командата за условен преход. Освен това ще предполагаме, че функционалните устройства са напълно конвейеризирани или дублирани (толкова пъти, колкото е дължината на конвейера), така че операция от произволен тип може да бъде зареждана за изпълнение във всеки такт и структурни конфликти отсъстват. Ще разгледаме накратко по какъв начин компилаторът може да увеличи степента на паралелизъм в нивото на машинните команди чрез разгъване на циклите. За илюстрация ще разгледаме обикновен цикъл, който добавя скаларна величина към вектор в паметта. Това е паралелен цикъл, тъй като няма зависимост между отделните му итерации. Нека първоначално в регистър R1 да се съдържа адресът на последния елемент на вектора. Това е елементът, чийто адрес е най-голям. Нека още в регистър F2 да се съдържа стойността на скаларната величина, която трябва да се добави към всеки елемент на масива. Програмата, която при това не разчита на конвейерен процесор, има следния примерен текст:
Loop: LOAD F0,
0(R1) // F0:=(Mem[(R1)+0]) зарежда елемент от масива//
ADDD F4,
F0, F2 // F4 := (F0) + (F2) добавяне на скалар от F2 //
STORED 0(R1), F4 // Mem[(R1)+0] := (F4)
запис на резултата //
SUBI R1, R1, #8 // R1 := (R1)+8 модифициране
на указателя
8 байта (в двойна дума) //
BNEZ R1,
Loop // (R1)¹0 ? условие за край на цикъла //
За простота в
горния текст е прието, че масивът е разположен от начален адрес 0. Ако той беше с друг
начален адрес, в цикъла трябва да се включи една допълнителна целочислена
команда за сравнение на съдържанието на регистър R1. Ще анализираме
изпълнението на този цикъл върху обикновен конвейер, имащ задръжките от таблица
5.3.3.2.
Ако не правим
никакво планиране (т.е. разместване), работата на цикъла би изглеждала така:
Loop: LOAD F0, 0(R1) 1 такт
Задръжка 2 такта
ADDD F4, F0, F2 3 такта
Задръжка 4 такта
Задръжка 5 такта
STORED 0(R1),
F4 6
такта
SUBI R1,
R1, #8 7
такта
BNEZ R1,
Loop 8
такта
Задръжка 9 такта
За изпълнение
на една итерация са необходими 9 такта –задръжка 1 такт за команда LOAD,
два такта за команда ADD и един такт за задържания преход. Цикълът обаче
можем да планираме по следния начин:
Loop: LOAD F0, 0(R1) 1 такт
Задръжка 2 такта
ADDD F4, F0, F2 3 такта
SUBI R1,
R1, #8 4
такта
BNEZ R1,
Loop 5
такта (задържан преход)
STORED 8(R1),
F4 6
такта (командата е променена)
Времето за
изпълнение на една итерация е намалено от 9 на 6 такта. Ще отбележим, че за
планиране на задържания преход компилаторът трябва да установи, че може да
размени местата на команда SUB и STORE чрез промяна на адреса за
запис. Адресът за запис беше 0(R1), но в новия текст е 8(R1). За един
компилатор тази задача съвсем не е тривиална, тъй като повечето компилатори
биха виждали зависимостта на команда STORE от команда SUB, а това
със сигурност ще ги откаже от подобно разместване. Един по-прецизен компилатор
обаче би могъл да анализира и разбере отношенията между командите и да изпълни
разместването. Веригата от зависимости от команда LOAD към команда ADD
и по-нататък към команда STORE, определя броя на тактовете, необходим на
дадения цикъл.
С помощта на горния текст извършваме една итерация от цикъла и записваме един елемент от вектора на всеки 6 такта. Действителната работа за получаване на този елемент обаче отнема само 3 (зареждане, събиране и запис) от тези 6 такта. Останалите 3 такта представляват неизбежните разходи за организация на цикъла (изваждане, сравнение и задръжка). За да отстраним тези 3 такта са необходими повече операции в цикъла в сравнение с тези, които са свързани с организацията му. Един от най-простите методи за увеличение броя на командите в тялото на цикъла в отношение към командата за условен преход с цел преодоляване на неизбежните разходи, представлява разгъването на цикъла. Това разгъване (развиване) се изпълнява чрез многократна репликация (повторение, предизвикано повторение) на тялото на цикъла придружена от съответната корекция в “условието” за край на цикъла. Ако броят на повторенията за един цикъл са три и репликациите на тялото му са също три, то проверката на условието за край на цикъла чрез команда за условен преход става безсмислена и в разгънатия вариант на неговата реализация тя не съществува. Тази реализация на регулярни и нерегулярни повторения в изчислителния процес е обяснена в §2.1. Тук отново се връщаме към този вариант, но принудени от други причини, което е един чудесен пример за еволюционната спирала.
Разгъването на цикли може да се използва също така за оптимизиране на планирането на кода на програмите. В този случай може да бъде отстранена задръжката, свързана с командата LOAD (вижте горния пример), чрез създаване на допълнителни независими команди в тялото на цикъла. След това компилаторът може да планира тези команди за поместване в слота на задръжка на командата LOAD (вижте фигура 5.3.2.11). Ако при разгъване на цикъла командите биват просто репликирани, то резултиращите зависимости по имена могат да попречат на ефективното планиране на цикъла. По този начин, за различните итерации е желателно да бъдат използвани различни регистри, което засилва изискванията за по-голям обем на регистровата памет на процесора.
След направените по-горе коментари ще разгънем примерния цикъл в четири копия на тялото му, предполагайки, че съдържанието на регистър R1 първоначално е кратно на 4. При разгъването ще отстраним всички очевидно излишни изчисления и няма да използваме повторно нито един регистър. Резултатът е получен чрез сливане на командите SUBI и изхвърляне на ненужните проверки BNEZ, които се дублират при разгъване на цикъла.
Loop: LOAD F0, 0(R1)
ADDD F4, F0, F2
STORED 0(R1), F4 //следващите SUBI и BNEZ са изхвърлени//
LOAD F6, 8(R1)
ADDD F8, F6, F2
STORED 8(R1), F8 //следващите SUBI и BNEZ са изхвърлени//
LOAD F10, 16(R1)
ADDD F12, F10, F2
STORED 16(R1), F12 //следващите SUBI и BNEZ са изхвърлени//
LOAD F14, 24(R1)
ADDD F16, F14, F2
STORED 24(R1), F16
SUBI R1, R1, #32
BNEZ R1, Loop
И така,
ликвидирани са три операции изваждане в R1 и три проверки за условен преход.
Адресите в командите LOAD и STORE са коригирани така, че да бъде
постигнато сливането на командите SUB до една команда в края на текста.
При отсъствие на планиране тук след всяка команда следва зависима команда, а
това ще води до задръжки в конвейера. Текстът на този цикъл ще се изпълнява за
27 такта (на всяка команда LOAD са необходими 2 такта, на всяка команда ADD
– 3, на условния преход – 2 и на всички други по 1 такт) или средно по 6,75
такта за една четвърт част от текста. Въпреки че изпълнението на този разгърнат
вариант е по-бавно в сравнение с оптимизирания вариант на изходния цикъл, то
след оптимизация на самия разгънат цикъл, ситуацията ще се промени. Обикновено
разгъването на циклите се извършва на по-ранни етапи в процеса на компилиране,
така че излишните изчисления могат да бъдат изявени и отстранени от
оптимизатора.
В реалните
програми обикновено не знаем горната граница на цикъла. Да предположим, че тя е
равна на n и искаме
да разгънем цикъла с k
копия на тялото. Вместо един разгънат цикъл ние генерираме два. Първият е
съставен така, че изпълнява nmod(k) пъти изходното му тяло.
Разгънатата част на цикъла се влага във външен цикъл, който се изпълнява (n/k)
пъти. Тук искаме да предупредим читателя, че съотношенията по модул са
приложими само за цикли от вида с предварително известен брой повторения.
В приведения
по-горе пример разгъването на цикъла увеличава производителността му чрез
отстраняване на команди, свързани с непроизводителните разходи за организацията
му, въпреки че при това съществено се увеличава машинния код. Възниква въпросът
колко ще се увеличи производителността, ако цикълът бъде оптимизиран.
Loop: LOAD F0, 0(R1)
LOAD F6, -8(R1)
LOAD F10, -16(R1)
LOAD F14, -24(R1)
ADDD F4, F0, F2
ADDD F8, F6, F2
ADDD F12, F10, F2
ADDD F16, F14, F2
STORED 0(R1), F4
STORED -8(R1), F8
STORED -16(R1), F12
SUBI R1, R1, #32
BNEZ R1,
Loop
STORED 8(R1), F16 // 8 - 32 = -24 //
Времето за
изпълнение на така разгънатия цикъл е спаднало до 14 такта или по 3,5 такта на
една четвърт от текста. Този резултат стои срещу оценката от 6,75 такта до
оптимизацията и даже срещу оценката от 6 такта за оптимизирания, но не разгънат
цикъл. Печалбата от оптимизацията на разгънатия цикъл е даже по-голяма в
сравнение с оптимизирания първоначален вариант на цикъла. Това се случва защото
разгъването на цикъла изявява повече изчисления, които могат да бъдат
оптимизирани за минимум конвейерни задръжки – представеният по-горе текст се
изпълнява без задръжки. При подобна оптимизация е необходимо да се съзнава, че
командите за зареждане на регистър и командите за запис в паметта са независими
и могат да бъдат редувани. Анализът на зависимостите по данни ни позволява да
определяме са ли командата за зареждане и командата за запис независими
команди.
Разгъването на
цикли представлява прост, но полезен метод за увеличаване на линейната дължина
на кодовия фрагмент, който може ефективно да бъде оптимизиран. Това
преобразование е полезно за множество машини – от такива с прости конвейери,
подобни на разгледания по-рано тук, до суперскаларни конвейери, които могат да
бъдат зареждани с повече от една команда в един такт.
По-надолу ще
разгледаме методи, които използват апаратни средства за динамично планиране на
зареждането на конвейера и съкращаване на задръжките по причина на конфликти от
тип RAW, аналогични на горе разгледаните методи за компилиране.
Б) Отстраняване на зависимостите по данни и
механизми за динамично планиране
Основното
ограничение в методите за конвейерна обработка представлява необходимостта от
зареждане на командите в строго определения ред на програмата. Така ако при
изпълнението на дадена команда конвейерът бъде задържан, то изпълнението на
следващата команда също ще бъде задържано. В случай на зависимост между две
близко разположени в конвейера команди би възникнала задръжка на много команди.
Ако в структурата на конвейера съществуват няколко функционални устройства,
много от тях биха се оказали незаредени. Ако команда №j зависи от една дълга
команда №i , изпълняваща се в конвейера, то всички команди след команда №j
трябва да бъдат задържани дотогава, докато команда №i не завърши своето
изпълнение и не се възстанови изпълнението на команда №j. Нека разгледаме
следващата последователност:
DIVD F0, F2, F4
ADDD F10, F0, F8
SUBD F8, F8, F14
Операция
изваждане SUBD не може да се изпълни по причина на това, че зависимостта
между командите за деление и събиране причинява задръжка на конвейера. Команда SUBD
обаче няма никакви зависимости от командите в конвейера. Това представлява
ограничение на производителността, което може да бъде отстранено чрез
премахване на изискването за изпълнение на командите в предписания ред. В
разгледания конвейер структурните конфликти и конфликтите по данни се
проверяваха по време на началния етап АО – декодиране на командата (вижте
определенията в предидущия пункт 5.3.2.). Ако
командата би могла да се изпълни нормално, тя се прехвърля от тази в следващата
степен на конвейера. За да бъде позволено да започне изпълнението на команда
SUBD, е необходимо да разделим процеса на зареждане на две части: на проверка
за структурни конфликти и четене на операнди при очакване на отсъствие на
конфликт по данни. Когато зареждаме командата за изпълнение, можем да
осъществим проверка за наличие на структурни конфликти, при което ние все още
използваме установения ред на командите. Ние обаче искаме да започнем
изпълнението на операцията веднага щом получим достъп до нейните операнди. По
този начин конвейерът ще изпълнява командите непоследователно, а това означава,
че тяхното завършва също ще бъде непоследователно. Непоследователното
завършване на командите създава основните трудности при обработка на
изключителните ситуации (прекъсванията). Процесът на прекъсване в разглежданите
тук машини с динамично планиране на потока команди ще бъде неточен, тъй като
командите могат да завършат изпълнението си преди процесът на изпълнение на
по-рано заредени команди да причини изключителна ситуация. В резултат много
трудно може да бъде организиран повторен старт на командата след връщане от
прекъсването. Ето защо възможните решения на така поставения проблем ще бъдат
обсъдени по-късно при разглеждане на точните прекъсвания в контекста на машините,
използващи планиране по предположение.
За да реализираме непоследователно изпълнение на командите, ще разделим степента АО на конвейера на две степени:
1.
Зареждане на командата –
декодиране и проверка за структурни конфликти;
2.
Четене на операндите – при четенето
се очаква отсъствие на конфликти по данни.
След степента
АО, с две й части, следва изпълнителната степен ИО на конвейера (вижте фигура 5.3.2.2). Тъй като изпълнението на операциите
с плаваща запетая изисква няколко такта, ние сме длъжни да знаем кога започва и
кога завършва изпълнението на командата. Това ще позволи в един и същи момент
да се изпълняват няколко команди. В допълнение към тези изменения в структурата
на конвейера, ще изменим и структурата на функционалните устройства, променяйки
техния брой, задръжката в операциите и степента на конвейеризацията им, по
такъв начин, че по най-добър начин да използваме методите на конвейеризация.
Б1) Динамична оптимизация с централизирана схема
за откриване на конфликти
В конвейер с динамично планиране
на потока, всички команди преминават през степента за зареждане в строго
съответствие с предписания от програмата ред. Те обаче могат да бъдат задържани
и да се изпреварват една друга на втората степен (степента, в която се четат
операндите) и по този начин да постъпват в степента за изпълнение
непоследователно. Централизираната схема (scoreboard) за откриване на
конфликти представлява метод, който допуска непоследователно изпълнение на
командите при наличие на достатъчни ресурси и при отсъствие на зависимости по
данни.
Преди да
започнем обсъждането на възможността за приложение на споменатите схеми е важно
да отбележим, че конфликти от тип WAR, които отсъстват в обикновени конвейери,
могат да се появят при непоследователно изпълнение на командите. В по-горе
приведения пример, регистър на резултата от команда SUBD е регистър R8,
но в същото време той е посочен от команда ADDD като източник на
операнд. Така между тези две команди съществува антизависимост: ако конвейерът
изпълни команда SUBD по-рано от команда ADDD, той ще наруши тази
антизависимост. Този WAR конфликт може да бъде заобиколен, ако се спазят
следните две правила:
1.
Да се четат регистрите само по
време на етапа четене на операнди ;
2.
Операция събиране (ADDD)
да се постави в опашката заедно с копията на своите операнди.
За да се
избегнат нарушения на зависимостите по изход, конфликтите от тип WAW следва да
бъдат откривани. Например, такъв конфликт би могъл да възникне, ако за
фиксиране на резултата команда SUBD бе посочила регистър F10). Обърнете
внимание, че този регистър се използва за същата цел от по-рано изпълняваната
команда събиране. Конфликтите от тип WAW могат да бъдат отстранявани чрез
задръжка на зарежданата команда, чийто регистър за резултат съвпада с вече
използван в конвейера.
Задачата на
централизираната схема за откриване на конфликти е да поддържа изпълнението на
командите със скорост една команда за един такт (при отсъствие на структурни
конфликти), чрез колкото се може по-ранно стартиране на изпълнението. По този
начин, когато команда в началото на опашката бъде задържана, другите команди ще
могат да се зареждат и изпълняват, ако не зависят от вече изпълняваща се или
задържана команда. Централизираната схема носи пълната отговорност за
зареждането и изпълнението на командите, включително и за откриването на
конфликтите. Непоследователното изпълнение на командите в същност изисква
няколко команди едновременно да се намират в състояние на изпълнение. Това
положение може да се постигне по два начина: чрез реализация в процесора на множество
неконвейерни функционални устройства или чрез конвейеризация на всички
функционални устройства. От гледна точка на организацията тези две възможности
са еквивалентни. Ето защо ще предполагаме, че в процесора има няколко
неконвейерни функционални устройства за работа с плаваща запетая. Ще приемем,
че съществуват 2 устройства за умножение, 1 за деление, 2 за събиране
(изваждане) и 1 целочислено устройство, което се използва още при всички
операции за обмен с оперативната памет и преходи. На следващата фигура 5.3.3.1
е показано мястото на схемата за централизиран контрол.
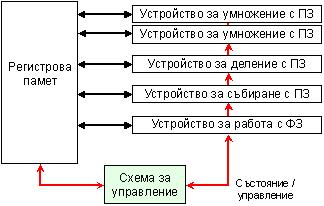
Фиг. 5.3.3.1. Схема за
управление на конвейера
Всяка команда от опашката преминава при зареждането си в конвейера през централизираната схема за откриване на конфликти, която определя зависимостите по данни – тази стъпка съответства на етапа ДК (доставка на командата) и заменя част от следващия етап АО в разглеждания тук конвейер. Зависимостите по данни определят по-късно моментите от времето, когато командата може да чете своите операнди и да започне изпълнението на същинската операция. Ако централизираната схема реши, че командата не може незабавно да се изпълни, тя я задържа като следи за всички изменения в апаратурата и по този начин определя кога командата ще може да се изпълни. Тази схема решава кога една команда може да запише в регистър своя резултат. По този начин, цялата логика за откриване и разрешаване на конфликтите в конвейера, е съсредоточена в това устройство за централизирано управление.
Всяка команда преминава през 4 етапа на своето изпълнение. Тези 4 етапа съответстват и заменят онези 4, които описахме за обикновения конвейер. Етапите и тяхната същност са следните:
1. Зареждане в конвейера. Ако функционалното устройство, необходимо за изпълнение на командата, е свободно и никоя друга вече изпълняваща се команда не използва същия регистър за резултата, централизираната схема зарежда командата във функционалното устройство и обновява своята вътрешна даннова структура. Тъй като никое друго работещо функционално устройство не може да запише резултат в регистъра за резултата на нашата команда, ние гарантираме, че конфликти от тип WAW не могат да възникнат. Ако съществува структурен конфликт или конфликт от тип WAW, зареждането на командата се блокира и никакви следващи команди няма да се зареждат за изпълнение до тогава, докато поне тези конфликти съществуват. Този етап заменя част от етапа ДК в нашия конвейер.
2. Четене на операнд. Управляващата схема следи и контролира възможността съответните източници да зареждат операндите на командата. Операндът източник е достъпен, ако липсва изпълняваща се команда, която да желае да записва резултат в този регистър или ако в дадения момент в регистъра, съдържащ операнда, се изпълнява запис от страна на работещо функционално устройство. Ако операндите-източници са достъпни, централизираната схема съобщава на функционалното устройство за необходимостта да бъдат прочетени операндите от регистрите и за началото на изпълнението на операцията. На този етап централизираната схема за управление на конвейера разрешава динамично конфликтите от тип RAW и командите могат да се изпращат за изпълнение не в реда, предписан от програмата. Този етап, съвместно с етапа зареждане, съответства на работата на степен АО в обикновения конвейер.
3. Изпълнение. Функционалното устройство започва изпълнението на операцията след получаване на операндите. Когато резултатът е готов, то уведомява схемата за управление. Тази част от изпълнението заменя етапа ИО и заема няколко такта в по-рано разгледания от нас конвейер.
4. Запис на резултата. Когато централизираната схема за управление, че функционалното устройство е завършило изпълнението на операцията, тя проверява за наличие на конфликт от тип WAR. Конфликт от тип WAR съществува, ако е налице последователност от команди, аналогична на представената в нашия пример, но с командите ADDF и SUBF:
DIVF F0, F2, F4
ADDF F10, F0, F8
SUBF F8, F8, F14
Командата
ADDF има за операнд-източник регистър F8, който се явява едновременно
операнд-източник и регистър за резултата на команда SUBF. В
действителност обаче, командата ADDF зависи от предидущата команда,
която трябва да запише своя резултат в регистър F0. Така централизираната схема
за управление ще блокира зареждането на команда SUBF в конвейера, до
тогава, докато команда ADDF не прочете своите операнди. В общият случай,
на завършващата команда не се позволява да запише своя резултат, ако:
·
Има команда, която не е прочела
своите операнди ;
·
Един от операндите представлява
регистър за резултата на завършващата команда.
Ако
няма конфликт от тип WAR, схемата за управление съобщава на функционалното
устройство за необходимостта резултатът да се запише в определения регистър.
Този етап заменя действията в последната степен ФР на обикновения конвейер.
Основавайки
се на своята собствена даннова структура, централизираната схема за управление
на конвейера, командва придвижването на командата от една степен на друга,
взаимодействайки при това с функционалните устройства. Тук обаче съществува
едно усложнение: регистровата памет е достъпна чрез ограничен брой магистрали
за източниците на операнди и за запис на резултати. Схемата за управление
трябва да гарантира, че броят на функционалните устройства, на които е
разрешено да работят на степени 2 и 4, не превишава броя на достъпните шини.
Обикновено този проблем се решава, като функционалните устройства се групират
според необходимостта от даден вид връзки. Връзките на всяка група устройства
се поддържа от съответен комплект шини. Така в рамките на един такт само едно
устройства от дадена група получава достъп до регистровата памет за четене на
операнд или за запис на резултат.
Общата
структура на регистрите на състоянието на устройството за централизирано
управление е показана чрез таблица 5.3.3.2. Тя се състои от 3 части:
1.
Състояние на командата – показва всеки един от четирите етапа за изпълнение на
командата.
2.
Състояние на функционалните
устройства – съществуват 9 полета,
описващи състоянието на всяко функционално устройство:
·
Заетост – показва заето ли е
устройството или е свободно ;
·
Op – съответства на
изпълняваната в устройството операция ;
·
Fi – регистър на резултата ;
·
Fj , Fk – регистри-източници на операнди ;
·
Qj , Qk – функционални устройства, изчисляващи
резултати, които ще се записват в регистрите Fj , Fk ;
·
Rj , Rk – регистри, съдържащи признаците за
готовността на операндите в регистрите
Fj , Fk .
3.
Състояние на регистрите на
резултата – показва функционалното
устройство, което ще прави запис във всеки от регистрите. Това поле се
установява в нула, ако съществуват команди, които записват резултат в дадения
регистър.
Състоянието
на централизираната схема е представено за една последователност от команди,
която се съдържа в следващата таблица 5.3.3.3:
Таблица 5.3.3.3 Регистри на състоянието на ЦСУ
|
Състояние на командите |
|||||
|
КОМАНДА |
Зареждане |
Четене на операнди |
Край на
изпълнението |
Запис на резултата |
|
|
LOADF |
F6,
34(R2) |
Ö |
Ö |
Ö |
Ö |
|
LOADF |
F2,
45(R3) |
Ö |
Ö |
Ö |
|
|
MULTD |
F0,
F2, F4 |
Ö |
|
|
|
|
SUBD |
F8,
F6, F2 |
Ö |
|
|
|
|
DIVD |
F10,
F0, F6 |
Ö |
|
|
|
|
ADDD |
F6,
F8, F2 |
|
|
|
|
|
Състояние на функционалните устройства |
|||||||||
|
Име |
Заетост |
Op |
Fi |
Fj |
Fk |
Qi |
Qk |
Ri |
Rk |
|
Integer |
Да |
LOAD |
F2 |
R3 |
|
|
|
|
|
|
Mult_1 |
Да |
MULT |
F0 |
F2 |
F4 |
Integer |
|
Не |
Да |
|
Mult_2 |
Не |
|
|
|
|
|
|
|
|
|
Add |
Да |
SUB |
F8 |
F6 |
F2 |
|
Integer |
Да |
Не |
|
Divide |
Да |
DIV |
F10 |
F0 |
F6 |
Mult_1 |
|
Не |
Да |
|
Състояние на регистъра на резултата |
|||||||||
|
|
F0 |
F2 |
F4 |
F6 |
F8 |
F10 |
F12 |
… |
F30 |
|
FU |
Mult_1 |
Integer |
|
|
Add |
Divide |
|
|
|
Няколко
ситуации не се обработват от централизираната схема за управление. Например,
когато една команда записва своя резултат, зависимата от нея команда в
конвейера трябва да дочака разрешение за обръщение към регистровата памет, тъй
като всички резултати винаги се записват там и никога не се използват
заобикалящи (транзитни) връзки, от вида показан на фигура
5.3.2.5. Всичко това увеличава задръжките и ограничава възможността да
бъдат изпълнявани няколко команди, очакващи резултата. Конфликтите от тип WAW
се явяват много рядко и поражданите от тях задръжки са несъществени за общия
ход на програмата. При динамично планиране на потока команди в конвейера обаче,
когато могат да бъдат съвместени за изпълнение няколко итерации на цикъла, за
да бъде планирането ефективно, се налага използването на апаратна схема за
обработка на конфликтите от този тип. Това се налага още по причина, която
поражда самото динамично планиране – повишава се честотата на този тип
конфликти.
Един
от най-ранните компютри, прилагащ централизирано управление на потока команди е
CDC6600 (1964 година). В този процесор са били реализирани 16 функционални
устройства (4 за работа с плаваща запетая, 7 за работа с фиксирана запетая и 5
за обмен на данни с паметта), групирани по 4 в 4 групи. Всички съвременни
процесори на фирмите Intel, AMD, Motorola и др. ,
реализиращи суперскаларна архитектура, използват под една или друга форма
изложения тук подход за управление на потока команди в конвейера.
Б2) Динамично планиране с алгоритъм на Томасуло
Ще разгледаме друг подход към управление на паралелното изпълнение на команди, който е бил използван в устройството за работа с плаваща запетая в компютъра IBM-360/91 (1967 година). Задачата на IBM се състояла в достигане на висока производителност при изпълнение на операции с плаваща запетая, използвайки определен набор команди и компилатори, разработени за цялата гама модели в системата 360. В архитектура на системата 360 се предвиждали само 4 регистъра за числа с плаваща запетая с двойна дължина, което ограничавало компилатора в задачата за ефективно планиране на кода. В условията на голяма продължителност на операциите с плаваща запетая и голямо закъснение при обръщение към паметта, задачата за оптимално натоварване на процесора е стояла изключително актуално.
Ще разясним алгоритъма на Томасуло също в условията на функционални устройства с плаваща запетая. Разликата между нашия конвейер с плаваща запетая и този на IBM-360 се състои в това, че последният може да обслужва машинни команди от тип регистър-памет (R-M). Тъй като алгоритъмът на Томасуло използва функционално устройство за зареждане, то не са необходими значителни разходи за реализация на този вид адресация, които се изразяват в добавяне на допълнителна шина за връзка. IBM-360/91 притежавала конвейерни операционни устройства. В конвейера с плаваща запетая се изпълнявали до 3 операции събиране и 2 операции умножения. В процес на изпълнение са можели да бъдат до 6 операции зареждане на числа с плаваща запетая от паметта в регистри и до 3 операции запис в паметта на числа с плаваща запетая. За реализация на последните се използвали буфер за зареждане и буфер за запис на данни. От казаното се установява, че фундаментални разлики с нашата постановка няма, така че ние ще опишем алгоритъма на Томасуло за условията на конвейер с няколко функционални устройства. Тъй като при нас командите са единствено от вида регистър-регистър (R-R), ще добавим само буфер за операнди.
В сравнение с описаната в предидущата точка Б1) централизирана схема за управление, схемата на Томасуло се реализира като разпределена. Тя е разпределена по две причини. Първо, средствата за откриване на конфликтите в потока команди и за управление на изпълнението им, са разпределени – те се намират в така наречените reservation station (разбирайте фиксатори на междинни резултати). Станциите за резервиране се намират във всяко функционално устройство и имат задължението да определят кога дадена команда може да стартира изпълнението си върху дадено функционално устройство. На второ място схемата е разпределена, защото резултатите от операциите се изпращат директно във функционалните устройства без да е необходимо да преминават през регистровата памет. За целта се изгражда една обща шина за данни (common data bus – CDB), която може да зареди едновременно всички устройства, които очакват този операнд. По-долу на фигура 5.3.3.2 е показан общата структура на устройствата с плаваща запетая въз основа на алгоритъма на Томасуло.
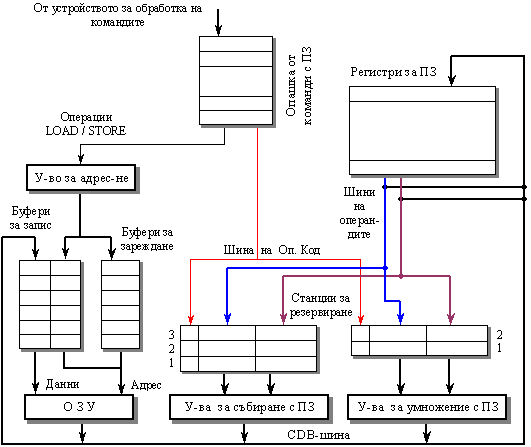
Фиг. 5.3.3.2. Структура на
устройството с ПЗ, базирано на алгоритъма на Томасуло
В него не съществуват таблици за състоянието и управлението, подобни на показаните в предидущата точка. Станциите за резервиране съхраняват заредените команди и очакват изпълнението в съответните функционални устройства. Те съхраняват още и информацията, необходима за управление на започналото изпълнение на съответната операция в устройството. Буферите за зареждане и за запис съхраняват постъпилите от паметта данни и готовите за запис в паметта резултати. Регистрите с плаваща запетая са свързани към функционалните устройства с една двойка даннови шини, а с буферните памети – чрез общата даннова шина CDB. Така всички резултати от функционалните устройства и от паметта се разпространяват чрез CDB-шината до входовете на всички устройства с изключение на буфера за зареждане. Всички буфери и станции за резервиране притежават полета за теговете, използвани при управление на конфликтите.
Изпълнението на една команда в представената структура преминава през следните етапи, които за разлика от предходната, са само три:
1. Зареждане в конвейера. Взема се команда от опашката команди с плаваща запетая. Ако операцията е за обработка, тя се зарежда ако има свободна станция за резервиране, като в последната се зареждат нейните операнди, ако те се съдържат в регистрите с ПЗ. Ако операцията е операция зареждане или запис, тя може да се зарежда ако има свободен буфер. При липса на свободна станция за резервиране или на свободен буфер възниква структурен конфликт и командата се задържа до тогава, докато не се освободи станция или буфер.
2. Изпълнение. Ако единият или и двата операнда на командата са недостъпни по някакви причини, то се контролира състоянието на CDB-шината и се очаква края на изчислението на стойността за необходимия регистър. На този етап се прави контрол на конфликтите от типа RAW. Когато двата операнда са достъпни, то операцията на заредената команда се изпълнява.
3. Запис на резултата. Когато резултатът от операцията се получи той се подава на CDB-шината, чрез която той попада в регистър с ПЗ или в онази станция за резервиране, която обслужва очакващото този резултат функционално устройство.
Въпреки че
формулираните по-горе действия са сходни с тези при централизираното
управление, тук има три важни различия. Като първо ще отбележим, че липсва
контрол на конфликти от тип WAW и WAR, тъй като тяхното отстраняване се явява
страничен ефект на алгоритъма. На второ място, за трансфер на резултатите се
използва общата шина (CDB-шината), а не схема за очакване на готовността на
регистрите. На трето място, буферите за зареждане и за запис се разглеждат като
основни функционални устройства. Данновите структури, използвани за откриване и
отстраняване на конфликтите, са свързани със станциите за резервиране, с
регистровата памет и с буферите за зареждане и за запис. Въпреки че с
различните обекти е свързана различна информация, всички устройства, с
изключение на буферите за зареждане, съдържат във всеки свой ред поле на тега.
Това тегово поле съдържа 4-битова комбинация, която адресира една от петте
станции за резервиране или един от шестте буфери за зареждане. Полето на тега
се използва за описание на онова устройство, което ще доставя резултат,
необходим в качеството си на операнд-източник. Неизползваните комбинации,
такива като нула, показват че операндът е вече достъпен. Важно е да се помни,
че теговете се позовават на буфери или на устройства, които ще доставят
резултат. Когато командата попадне в станция за резервиране, номерата
(адресите) на регистрите се изключват от разглеждане.
Всяка станция
за резервиране съдържа 7 полета:
·
Op – операция, която следва да се изпълняваната върху
операндите-източници S1 и S2 ;
·
Qj , Qk – станции за резервиране, които ще издават съответния
операнд-източник. Нулевата комбинация показва, че операндът-източник е вече
достъпен в полето Vj или Vk , или е незадължителен. В
IBM-360/91 тези полета се наричат SINK-unit и SOURCE-unit съответно.
·
Vj , Vk – адрес на операнда-източник. За даден
операнд само едно от полетата V или Q е действително.
·
А – полето съхранява информацията за изчисляване на адреса в
паметта, от който ще се чете, или в който ще се записва. Първоначално, полето
съдържа адресната част на командата, а след изчисленията – съдържа
действителния адрес.
·
Заето – признак, който показва, че
дадената станция и съответстващото й функционално устройство, са заети.
Регистровата
памет и буферите за запис имат поле Qi , в което се съдържа номера
на функционалното устройство, което ще изчислява (ще изработва) стойността,
която следва да бъде записана в регистъра или в паметта. Ако Qi=0,
това означава, че нито една текущо активна команда не изчислява резултат за
дадения регистър или буфер.
Във всеки от
буферите за зареждане и за запис съществува поле, съдържащо признак (флаг) за
заетост. Този флаг показва кога съответният буфер става достъпен, благодарение
на завършило зареждане или запис, назначено върху него. Буферите за запис
съдържат още поле V, което съдържа стойността, която трябва да бъде записана в
паметта.
Ще разгледаме
същата командна последователност, която беше представена в таблица 5.3.3.3.
Преди да разгледаме алгоритъма, ще се спрем на системните таблици за тази
последователност, които описват станциите за резервиране, буферите за зареждане
и за запис и регистровите тегове. Тук към имената add, mult и load са добавени
номера, стоящи зад теговете за тази станция за резервиране. Така Аdd_1
представлява тег за резултата от първото устройство за събиране. Състоянието на
всяка операция, която е подадена за изпълнение, се съхранява в станцията за
резервиране.
Таблица 5.3.3.4 Тегове на станцията за резервиране и
регистрите
|
Състояние на командите |
||||
|
КОМАНДА |
Зареждане |
Четене на операнди |
Запис на резултата |
|
|
LOADF |
F6,
34(R2) |
Ö |
Ö |
Ö |
|
LOADF |
F2,
45(R3) |
Ö |
Ö |
|
|
MULTD |
F0,
F2, F4 |
Ö |
|
|
|
SUBD |
F8,
F6, F2 |
Ö |
|
|
|
DIVD |
F10,
F0, F6 |
Ö |
|
|
|
ADDD |
F6,
F8, F2 |
Ö |
|
|
|
Станции за резервиране |
|||||||
|
Име |
Заетост |
Op |
Vj |
Vk |
Qj |
Qk |
A |
|
Load_1 |
Не |
|
|
|
|
|
|
|
Load_2 |
Да |
LOAD |
|
|
|
|
45+Regs[F3] |
|
Add_1 |
Да |
SUB |
|
Mem[34+Regs[R2]] |
Load_2 |
|
|
|
Add_2 |
Да |
ADD |
|
|
Add_1 |
Load_2 |
|
|
Add_3 |
Не |
|
|
|
|
|
|
|
Mult_1 |
Да |
MULT |
|
Regs[F4] |
Load_2 |
|
|
|
Mult_2 |
Да |
DIV |
|
Mem[34+Regs[R2]] |
Mult_1 |
|
|
|
Състояние на регистрите |
|||||||||
|
Поле |
F0 |
F2 |
F4 |
F6 |
F8 |
F10 |
F12 |
… |
F30 |
|
Qi |
Mult_1 |
Load_2 |
|
Add_2 |
Add_1 |
Mult_2 |
|
|
|
Тук има две важни различия със
схемата за централизирано управление, които се забелязват в горните таблици.
Първо ще отбележим, че стойността на операнда се съхранява в станцията за
резервиране, в едно от полетата V, веднага щом той стане достъпен. Той не се
чете от регистровата памет по време на зареждане на командата в конвейера. На
второ място, тук командата ADDD е заредена за изпълнение. Нейното
зареждане беше блокирано в схемата с централизирано управление поради наличие
на структурен конфликт.
Силните страни в алгоритъма на Томасуло се изразяват в:
1.
Разпределение на логиката за
откриване на конфликтите ;
2.
Отстраняване на задръжките,
свързани с конфликтите от тип WAW и WAR.
Първото
достойнство възниква поради наличието на станции за резервиране и използването
на CDB-шината. Ако няколко команди очакват един и същи резултат и всяка команда
има вече своя друг операнд, то командите могат да се зареждат едновременно чрез
трансфер по общата даннова шина (CDB). За сравнение, в схемата с централизирано
управление очакващите команди трябва да четат своите операнди от регистрите,
когато се освободят регистровите шини.
Конфликтите от
тип WAW и WAR се отстраняват чрез преименуване на регистрите, използвайки
станциите за резервиране. В разгледания по-горе примерен програмен текст за
изпълнение е заредена както команда DIVD, така и команда ADDD,
въпреки съществуващият WAR конфликт по регистър F6. Конфликтът се преодолява по
един от двата начина. Ако командата, доставяща стойност за команда DIVD,
е завършила изпълнението си, то полето Vk ще съдържа резултата,
позволявайки на DIVD да се изпълнява независимо от команда ADDD. От
друга страна, ако изпълнението на команда LOADF не е завършило, то
полето Qk ще сочи Load_1 и командата DIVD ще бъде независима
от команда ADDD. По такъв начин, команда ADDD може винаги да бъде
заредена и да започне да се изпълнява. Всяко използване на резултата на команда
MULTD ще сочи станция за резервиране, позволявайки на команда ADDD
да завърши и да запише своя резултат в регистър, без въздействие от страна на
команда DIVD.
За да разберем
пълната сила на алгоритъма за отстраняване на конфликтите от тип WAR и WAW с
помощта на динамичното преименуване на регистрите сме длъжни да разгледаме
цикъл. Разглеждаме следния програмен текст, представляващ умножение на
елементите на един вектор със скаларна величина, чиято стойност се съдържа в
регистър F2:
Loop: LOADD F0,
0(R1)
MULTD F4,
F0, F2
STORED 0(R1),F4
SUBI R1, R1, #8
BNEZ R1, Loop // условен преход при R1¹0 //
При стратегия
за изпълним условен преход използването на станцията за резервиране ще позволи
изпълнението на няколко итерации на този цикъл. Това преимущество се дава без
статично разгъване на цикъла с програмни средства, тъй като в действителност
цикълът се разгъва динамично от апаратурата. Както вече беше отбелязано,
малкият брой регистри силно затруднява (ограничава) прилагането на статично
разгъване на цикъла. Статичното разгъване и планиране изпълнението на цикъла
изисква голям брой свободни регистри за да бъдат заобиколени взаимните блокировки
между командите. Алгоритъмът на Томасуло поддържа изпълнението с припокриване
на няколко копия от един и същи цикъл дори при наличие на малък брой регистри,
използвани от програмата.
Ще
предположим, че сме заредили за изпълнение всички команди на две последователни
итерации на цикъла, но още не завършило изпълнението на нито една операция от
тип зареждане/запис в паметта. Станциите за резервиране и таблиците със
състоянието на регистрите и на буферите за зареждане и за запис в тази точка са
представени по-долу. При това операциите на целочисленото функционално
устройство се игнорират и се предполага, че условният преход е бил прогнозиран
като изпълним. Когато системата е достигнала такова състояние могат да се
поддържат две копия на цикъла с коефициент CPI близък до единица при условие,
че операциите умножение могат да завършват за 4 такта. Ако игнорираме
допълнителните разходи на цикъла, които не са намалени в тази схема,
достигнатото ниво на производителност ще съответства на онова, което ние бихме
могли да достигнем чрез статично разгъване и планиране на цикъла от компилатора
при условие, че броят на свободните регистри е достатъчен.
В този пример
е показан допълнителен елемент, който е важен за работоспособността на
алгоритъма на Томасуло. Командата за зареждане LOAD от втората итерация
може лесно да завърши преди командата за запис STORE от първата
итерация, въпреки че нормалният последователен ред е различен. Операциите
зареждане и запис могат надеждно (безопасно) да се изпълняват в различна
последователност при условие, че посочват различни адреси в паметта. Това
различие се контролира чрез проверка на адресите в буфера за запис всеки път
когато се зарежда за изпълнение команда LOAD. Ако адресът в командата LOAD
съответства на един от адресите в буфера за запис, командата се задържа докато
буферът за запис не получи необходимата стойност, след което задържаната
команда може да се обръща към него или да изпълни обръщение към паметта. Това
динамично сравнение на адресите представлява алтернативната техника, която може
да се прилага от компилатора при разместване на командите за зареждане и за
запис.
Таблица 5.3.3.5 Състояние на станциите за резервиране, на
регистрите и на буферите
|
Състояние на командите |
|||||
|
КОМАНДА |
№ на итерация |
Зареждане |
Изпълнение |
Запис на резултата |
|
|
LOADD |
F0,
0(R1) |
1 |
Ö |
Ö |
|
|
MULTD |
F4,
F0, F2 |
1 |
Ö |
|
|
|
STORED |
0(R1),
F4 |
1 |
Ö |
|
|
|
LOADD |
F0,
0(R1) |
2 |
Ö |
Ö |
|
|
MULTD |
F4,
F0, F2 |
2 |
Ö |
|
|
|
STORED |
0(R1),
F4 |
2 |
Ö |
|
|
|
|
|
|
|
|
|
|
Станции за резервиране |
|||||||
|
Име |
Заетост |
Op |
Vj |
Vk |
Qj |
Qk |
A |
|
Load_1 |
Да |
LOAD |
|
|
|
|
Regs[R1]+0 |
|
Load_2 |
Да |
LOAD |
|
|
|
|
Regs[R1]-8 |
|
Add_1 |
Не |
|
|
|
|
|
|
|
Add_2 |
Не |
|
|
|
|
|
|
|
Add_3 |
Не |
|
|
|
|
|
|
|
Mult_1 |
Да |
MULT |
|
Regs[F2] |
Load_1 |
|
|
|
Mult_2 |
Да |
MULT |
|
Regs[F2] |
Load_2 |
|
|
|
Store_1 |
Да |
STORE |
Regs[R1] |
|
|
Mult_1 |
|
|
Store_2 |
Да |
STORE |
Regs[R1]-8 |
|
|
Mult_2 |
|
|
Състояние на регистрите |
|||||||||
|
Поле |
F0 |
F2 |
F4 |
F6 |
F8 |
F10 |
F12 |
… |
F30 |
|
Qi |
Load_2 |
|
Mult_2 |
|
|
|
|
|
|
|
Буфери за зареждане |
|
Буфери за запис |
||||||
|
Поле |
Load_1 |
Load_2 |
Load_3 |
|
Поле |
Store_1 |
Store_2 |
Store_3 |
|
Адрес |
Regs[R1] |
Regs[R1]-8 |
|
|
Qi |
Mult_1 |
Mult_2 |
|
|
Заетост |
Да |
Да |
Не |
|
Адрес |
Regs[R1] |
Regs[R1]-8 |
|
|
|
|
|
|
|
Заетост |
Да |
Да |
Не |
Тази динамична схема може да достигне много висока производителност при условие, че се поддържа ниска “стойност” на преходите, на която ще се спрем по-късно. Основният недостатък на алгоритъма на Томасуло се състои в сложността на схемата, която има големи апаратни разходи при своята реализация. Това особено силно се отнася за сложната и голяма по обем асоциативна памет, която трябва да работи с висока скорост, а така също и до сложната логика за управление. Наличието на само една обща даннова шина (CDB) също е причина за ограничаване растежа на производителността. Въпреки че могат да бъдат добавени допълнителни CDB-шини, всяка от тях трябва да взаимодейства с цялата апаратура на конвейера, включително и със станциите за резервиране. В частност, апаратурата за асоциативно сравнение трябва да се дублира във всяка станция за всяка отделна CDB-шина.
В схемата на Томасуло се комбинират две различни методики: методика за преименуване на регистрите и методика за буфериране на операндите-източници от регистровата памет. Буферирането на източниците на операнди позволява да бъдат разрешени конфликтите от тип WAR, които възникват когато операндите са достъпни в регистрите. Както ще изясним по-късно, възможно е отстраняване на такива конфликти чрез преименуване на регистър заедно с буферизация на резултата до тогава, докато все още има обръщения към старата версия на регистъра. Това е подход, който се използва апаратно изпълнение по предположение.
Разглежданата схема е привлекателна за конструктори, които са принудени да реализират конвейерна архитектура, за която е трудно да се изпълни планиране на програмния код или да се реализира регистрова памет с голям обем. От друга страна, предимството на подхода на Томасуло е възможно да бъде подценено на фона на увеличената цена на реализацията, в сравнение с методите за планиране на зареждането на конвейера чрез компилатора в машини, ориентирани към зареждане за изпълнение само на една команда за един такт. Тъй като обаче машините стават все по-агресивни в своите възможности за зареждане на команди, конструкторите се сблъскват с въпросите за производителността на код, който трудно се планира, какъвто в повечето случаи е той при нечислени обработки на данните. Така методиките за преименуване на регистрите и динамичното планиране на потока команди става все по-важни.
Ключови компоненти за увеличаване на паралелизма на ниво команди в алгоритъма на Томасуло са динамичното планиране; преименуването на регистрите и динамичното отстраняване на нееднозначното обръщение към паметта. Много е трудно обаче да се оцени значението на всеки едни от тези компоненти.
На апаратната техника за динамично планиране на зареждането на конвейера при наличие на зависимости по данни съответства и динамичната техника за ефективно заобикаляне на преходите. Последната се използва за две цели:
· За прогнозиране на това, дали преходът ще бъде изпълним ;
· За прогнозиране на това, дали е възможно по-ранно определяне на целевата команда на прехода.
Тази техника се нарича апаратно прогнозиране на преходите.
Следващият раздел е:
5.3.4 Апаратно
прогнозиране посоката на условните преходи