Последната актуализация на този раздел е от
2020 година.
5.3.5 Едновременно зареждане за изпълнение на няколко команди и динамично планиране. Процесори с дълга командна дума (VLIW).
Методите за
минимизиране на задръжките в работата на конвейера по причина на съдържащите се
в програмите логически зависимости по данни и по управление, които разгледахме
в предходните раздели, имаха за цел достигането на идеалния коефициент CPI=1,
(1 такт на команда). Допълнителното повишение на производителността на процесора
би снижило този коефициент под единица. Това обаче е непостижимо, ако на всеки
такт в конвейера се зарежда само една команда. От тук следва изводът, че е
необходимо паралелно зареждане на няколко команди в един такт. Съществуват два
типа процесори, построени на този принцип. Това са така наречените суперскаларни
процесори и процесори с много дълга командна дума (архитектура VLIW – Very
Long Instruction Word). Суперскаларните процесори могат да зареждат за
изпълнение на всеки такт променлив брой команди и работата на техния конвейер
може да бъде планирана както статично чрез компилатора, така и динамично със
средствата за апаратна оптимизация. За разлика от суперскаларните,
VLIW-процесорите зареждат за изпълнение фиксиран брой команди, които са обединени
в една “голяма” команда, или представляват пакет от команди с фиксиран формат
(команда MultiOp). Планирането на VLIW-процесорите се извършва винаги от компилатора.
Автор
на термина VLIW е Джоузеф Фишер (Joseph Fisher), учил в университета на Йел (Yale University),
където по-късно е професор. Терминът той употребява още през 1980 година,
когато в своите изследвания публикува идеята за групирането на машинни команди
и паралелното им изпълнение във множество операционни устройства. Фишер
предложил групирането на командите да бъде възложено на специализиран
компилатор. През 1984 година е създадена компания "Multiflow Computer”, която произвежда до 1990 година компютри с архитектура VLIW. Били
разработени 3 поколения компютри и специализирани компилатори за тях.
Процесорите Multiflow Trace можели да изпълняват за един цикъл 7, 14 или 28
операции. В зависимост от модела, дългата командна дума можела да достига до
1024[b].
Суперскаларните процесори оползотворяват паралелизма на ниво команди чрез изпращане на няколко команди от обикновения команден поток в различните функционални устройства на конвейера. Допълнително, за да избягнат ограниченията на последователното изпълнение на командите, тези процесори използват механизмите за преподреждане преди зареждане, на непоследователното (изпреварващо) завършване на командите, за прогнозиране на преходите, кеш-памети за целевите адреси на преходите както и условно (по предположение) изпълнение на команди. Нарастващата алгоритмична и апаратна сложност на тези механизми обаче създава сериозни проблеми при реализация на точно прекъсване.
В типичната суперскаларна машина апаратурата може да зареди от една до осем команди за един такт. Обикновено тези команди трябва да са независими и да удовлетворяват някои ограничения, като например, че във всеки такт може да бъде заредена само една команда за обръщение към паметта. Ако някоя команда е логически зависима или не удовлетворява критериите за зареждане в конвейера, за изпълнение ще бъдат заредени само онези команди, които я предхождат. Ето защо скоростта за зареждане в тези процесори е променлива. Това ги отличава от VLIW-процесорите, в които цялата отговорност за формиране на пакета от команди, които ще бъдат заредени едновременно, се поема от компилатора и апаратурата не взема никакви динамични решения, отнасящи се до това зареждане.
Нека да приемем, че процесорът може да зарежда за изпълнение 2 команди в един такт. Едната от тези команди може да бъде команда за зареждане на регистър с прочетена от паметта стойност, или обратното – запис в паметта на съдържанието на регистър, или команда за преход, или някаква операция в целочисленото АЛУ. Другата команда може да бъде някаква операция с плаваща запетая. Изискването за паралелното зареждане на команда за целочислена операция и команда за операция с плаваща запетая се реализира значително по-лесно, отколкото зареждането на 2 произволни команди. В реалните процесори (PA7100, hyperSPARC, Pentium, и др.) се прилага именно този подход. В по-мощни процесори (MIPS R10000, UltraSPARC, PowerPC 620 и др.) е възможно зареждане до 4 команди в един такт.
Зареждането на 2 команди в един такт изисква едновременно дешифриране и извличане на 64 бита. За да се облекчи дешифрирането се изисква командите да се разполагат в паметта по двойки или да бъдат изравнени на 64-битова граница (за изравняването като подход четете в пункт 6.3.2.3). В противен случай е необходимо командите да се анализират в процеса на извличане и вероятно да сменят местата си при пренасянето им към двете устройства (CPU и FPU). При това възникват допълнителни изисквания към схемите за откриване на конфликти. Във всеки случай втората команда може да се подава, само ако може да бъде подадена за изпълнение първата команда. Апаратурата взема такива решения в динамика, осигурявайки зареждането само на първата команда, ако условията за едновременно зареждане на 2 команди не се спазват. По-долу е представена времедиаграмата на конвейера в идеалния случай, когато във всеки такт за изпълнение се зареждат 2 команди. Предвид операциите с плаваща запетая ще имаме предвид 5 степенен конвейер със следните етапи (нива):
· ДК – доставка на командата ;
· АО – декодиране на командата / доставка на операндите ;
· ИО – изпълнение на операцията / изчисляване на ефективния адрес в паметта ;
· ОП – обръщение към паметта ;
· ФР – фиксиране на резултата в буфер.
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
|
Целочислена команда |
ДК |
АО |
ИО |
ОП |
ФР |
|
|
|
|
Команда с плаваща запетая |
ДК |
АО |
ИО |
ОП |
ФР |
|
|
|
|
Целочислена команда |
|
ДК |
АО |
ИО |
ОП |
ФР |
|
|
|
Команда с плаваща запетая |
|
ДК |
АО |
ИО |
ОП |
ФР |
|
|
|
Целочислена команда |
|
|
ДК |
АО |
ИО |
ОП |
ФР |
|
|
Команда с плаваща запетая |
|
|
ДК |
АО |
ИО |
ОП |
ФР |
|
|
Целочислена команда |
|
|
|
ДК |
АО |
ИО |
ОП |
ФР |
|
Команда с плаваща запетая |
|
|
|
ДК |
АО |
ИО |
ОП |
ФР |
Фиг. 5.3.5.1. Работа на
суперскаларен конвейер
Такъв конвейер позволява съществено увеличение на скоростта. Обаче за да може той да работи така, е необходимо да разполага или с напълно конвейеризирани устройства за работа с плаваща запетая, или съответния брой независими функционални устройства. В противен случай устройството с плаваща запетая ще се превърне в тънко (тясно) място на конвейера и ефектът, достигнат за сметка едновременното зареждане на 2 команди, ще стане минимален.
При паралелно подаване на 2 команди (една целочислена и една с плаваща запетая) нуждите от допълнителна апаратура, освен обикновена логика за откриване на конфликти, е минимална. Целочислените операции и операциите с плаваща запетая използват различни регистрови файлове и различни функционални устройства. Нещо повече, засилването на ограниченията за зареждане на команди, които могат да се разглеждат като структурни конфликти (тъй като за изпълнение могат да се подават само определени двойки от команди), откриването на които изисква само анализ на кодовете на операциите. Единственото усложнение възниква, когато командите са само команди за зареждане (от тип LOAD), за запис (от тип STORE) или команди за преместване на числа с плаваща запетая (от тип MOVE). Тези команди създават конфликти по портовете на регистровата памет за плаваща запетая (регистрите Fi), а така също могат да доведат до нови конфликти от тип RAW, когато операция с плаваща запетая, която би могла да се подаде за изпълнение в конвейера в същия такт, е зависима от първата команда в командната двойка.
Проблемът с регистровите портове може да бъде разрешен, например, чрез отделно подаване (зареждане) в конвейера на командите от споменатите типове. В случаите, когато те все пак се включват в двойки с операции с плаваща запетая, ситуацията можем да разглеждаме като структурен конфликт. Тази схема може лесно да се реализира, но тя ще има съществено въздействие на общата производителност. Конфликтът от подобен тип може да бъде отстранен чрез реализация в регистровата памет на два допълнителни порта (за извличане и за запис). Напомняме на читателя, че най-често регистровата памет за плаваща запетая е с организация LIFO.
Ако двойката команди се състои от една команда от тип зареждане на число с плаваща запетая и една операция с плаваща запетая, която зависи от нея, то подобен конфликт е необходимо да се открива и да се блокира зареждането в конвейера на операцията с плаваща запетая. Изключвайки този случай, всички други конфликти могат да възникват естествено, както това се случва в обикновен процесор, който осигурява зареждане на една команда в такт. За предотвратяване на ненужните задръжки, в структурата на конвейера е възможно да се наложат и допълнителни заобикалящи връзки.
Друг проблем, който може да ограничи ефективността на суперскаларната обработка, представлява закъснението при извличане на данни от паметта. В нашия примерен конвейер командите за зареждане имат задръжка от един такт, което не позволява на следващата команда да се възползва от зареденото число без задръжка. Тоест, в суперскаларния конвейер резултатът на командата за зареждане (LOAD) не може да бъде използван в този и в следващия такт. Това означава, че следващите три команди не могат да използват резултата на командата за зареждане без задръжка. Задръжката при преход също се получава с дължина три такта, тъй като командата за преход трябва да бъде първа в подадената за изпълнение двойка команди. За да използваме достъпния в суперскаларната машина паралелизма ефективно са необходими по-сложни методи за планиране на потока команди, от тези, които използват компилаторите или апаратните средства, а така също и по-сложни схеми за декодиране на командите.
Ще разгледаме например, какво ще ни даде разгъването на цикли и планирането на потока команди за суперскаларния конвейер. По-долу е представен цикълът, който ние вече разгъвахме и планирахме изпълнението му върху обикновен конвейер.
Loop: LOADD F0,
0(R1) // регистър F0 се
зарежда с елемент от масива
ADDD F4, F0, F2 // събиране със скалар от регистър F2
STORED 0(R1), F4 // запис на резултата в клетка от паметта
SUBI R1, R1, #8 // декрементиране на брояча (регистър R1)
// 8
байта на двойна дума
BNEZ R1, Loop // ако (R1) ≠ 0, преход
в точка Loop.
За да планираме без задръжки работата на този цикъл, е необходимо да го разгънем и да направим 5 копия на тялото му. Така еквивалентният текст на цикъла ще съдържа по 5 команди LOAD, ADDD и STORED и една команда за условен преход BNEZ. Разгънатият програмен текст е следният:
Таблица 5.3.5.1 Разгъване на цикъл за суперскаларен конвейер
|
Целочислена команда (първа) |
Команда с плаваща запетая (втора) |
Номер на такта |
|
Loop: LOADD F0, 0(R1) |
|
1 |
|
LOADD F8, -8(R1) |
|
2 |
|
LOADD F10, -16(R1) |
|
3 |
|
LOADD F14, -24(R1) |
|
4 |
|
LOADD F18, -32(R1) |
ADDD F4, F0, F2 |
5 |
|
STORED 0(R1), F4 |
ADDD F8,
F6, F2 |
6 |
|
STORED -8(R1), F8 |
ADDD F12,
F10, F2 |
7 |
|
STORED -16(R1), F12 |
ADDD F16,
F14, F2 |
8 |
|
STORED -24(R1), F16 |
ADDD F20,
F18, F21 |
9 |
|
SUBI R1, R1, #40 |
|
10 |
|
BNEZ R1, Loop |
|
11 |
|
STORED -32(R1), F20 |
|
12 |
Този разгънат суперскаларен цикъл сега
работи със скорост 12 такта за итерация или 2,4 такта на един елемент (в
сравнение с 3,5 такта за оптимизирания разгънат цикъл, изпълняван в обикновения
конвейер). В този пример производителността на суперскаларния конвейер е
ограничена от съществуващите съотношения между целочислените операции и
операциите с плаваща запетая, а наличието само на команди с плаваща запетая не
е достатъчно за поддържане на пълно натоварване на конвейера. Първоначалният
вариант на оптимизирания неразгънат цикъл се изпълнява със скорост 6 такта на
итерация, в която се изчислява един елемент от масива. По този начин ние
получаваме ускорение в 2,5 пъти, повече от половината от което е в резултат на
разгъването на цикъла. Делът на чистото ускоряване за сметка на суперскаларната
обработка представлява около 1,5 пъти.
В най-добрия случай суперскаларният
конвейер позволява избирането на две команди и зареждането им за изпълнение,
ако първата от тях е за целочислена операция, а втората за операция с плаваща
запетая. Ако това условие не може да се спази, което лесно може да се провери,
командите се зареждат последователно. Тук могат да се забележат две достойнства
на този конвейер в сравнение с VLIW-машината. Първо, плътността на кода има
слабо влияние, тъй като процесорът сам определя може ли да подаде следващата
команда, без да ни се налага да следим за това, дали командите съответстват на
възможността за зареждане. На второ място, в такива процесори могат да се
изпълняват и неоптимизирани програми, или програми, които са компилирани за
по-стари платформи. Разбира се такива програми не могат да оползотворят
възможностите на процесора. Ето защо един от начините за подобряване на тези
условия се състои в използването на средства за динамична оптимизация.
В общия случай в суперскаларната система
командите могат да се изпълняват паралелно и възможно не в предписания в
програмата ред. Ако не се вземат никакви мерки, такова непоследователно
изпълнение при наличие на множество функционални устройства с различни времена
за изпълнение на операциите, това може да доведе до допълнителни трудности.
Например, при изпълнение на някоя продължителна операция с плаваща запетая
(деление или изчисление на корен втори), може да възникне изключителна ситуация
в момент, когато е завършило изпълнението на по-бърза команда, заредена в
конвейера след споменатата бавна команда. За да се поддържа моделът на точното
прекъсване, апаратурата е длъжна да гарантира коректно състояние на процесора
при прекъсване, за да е възможна правилната организация на последващото връщане
от прекъсване.
Обикновено в машини с непоследователно
изпълнение на командите се предполага използването на допълнителни буфери,
които гарантират завършване на изпълнението на командите в точно определения от
програмата ред. Такива буфери съдържат “историята” и представляват FIFO-опашка,
в която командите попадат при зареждане заедно с текущите съдържания на
регистрите на резултата на тези команди, в зададения от програмата ред.
В момента на зареждане на командата в
конвейера, тя се записва в края на тази “опашка”. Единственият начин командата
да достигне изхода на опашката е да изчака изпълнението на всички команди,
постъпили в опашката преди нея. Ако дадена команда бъде изпълнена извънредно
(преждевременно), тя ще продължава да съществува в опашката (заедно със своя
резултат) и да очаква завършването на заредените преди нея в опашката операции.
Командата напуска опашката когато достигне нейния край (изход) при условие, че
резултатът й е готов. Ако командата е достигнала изхода на опашката, но
резултатът й още не е получен от функционалното устройство, тя изчаква и не
напуска опашката. С това си поведение тя осигурява модела на точното
прекъсване, тъй като цялата необходима информация се съхранява в буфера, а тя
позволява да бъде коригирано състоянието на процесора във всеки един момент.
Този буфер на “историята” дава възможност
за реализиране на така нареченото условно изпълнение на команди.
A) Спекулативно изпълнение на команди, прогнозиране на преходи и управление на паметта в суперскаларни процесори
Това изпълнение се нарича още спекулативно (speculative)
или още изпълнение по предположение. Става дума за изпълнение на
операции, заповядани от команди, стоящи след команда за условен преход. Ще
припомним, че по конструкция, непосредствено след командата за условен преход,
стоят командите в нейния клон “false”, тъй като тя в този случай предава
управлението по съдържанието на програмния брояч, т.е. на следващия по ред
адрес. Казаното е особено важно за повишаване на производителността на
суперскаларните архитектури. Статистическите наблюдения показват, че в
програмите на всеки 6 обикновени команди се пада средно по 1 команда за преход.
Ако задържаме изпълнението на командите, които следват след командата за
преход, загубите от конвейеризацията могат да се окажат неприемливи. Например,
при зареждане на 4 команди в един такт, средно във всеки втори такт се
изпълнява команда за преход. Механизмът на условното изпълнение на команди,
следващи след команда за преход, позволява да се преодолее този проблем.
Условното изпълнение обикновено е свързано с последователното изпълнение на
команди в по-рано предсказан клон на команда за преход. Устройството за
управление зарежда командата за условен преход, прогнозира посоката на прехода
и продължава да зарежда команди от така предсказаната точка нататък.
Ако прогнозата се окаже вярна, зареждането
на команди ще продължава без задръжки. Ако обаче прогнозата се окаже грешна,
устройството за управление прекратява изпълнението на условно (спекулативно)
заредените в конвейера команди и ако е необходимо, използва информацията от
буфера на историята за ликвидиране на всички последствия от изпълнението на
тези спекулативно заредени команди. След това започва извличане на команди от
правилния клон на програмата. по този начин, апаратурата, която е подобна на
буфера на историята, позволява да се реши не само проблемът с реализацията на
точното прекъсване, но води още до повишаване на производителността на
суперскаларните архитектури.
След въвеждането на конвейерната обработка на команди пред конструкторите възниква проблем – оказва се че конвейерът не се използва пълноценно и доста често той бездейства. Проблемът се оказва комплексен, преди въвеждането на конвейер изпълнението е било еднопасово и е било невъзможно подаване на втора команда на изпълнителното устройство преди завършване на обработката на предходната. При конвейерната обработка обаче подаването на команди преди получаване на резултата от предходната е всъщност основната идея заложена в метода за съвместното изпълнение. Разбира се, в случаите, когато резултат от една команда е вход на друга или при условен преход, няма друг изход освен да се изчака резултата от изпълнението й, в резултат на което в конвейера се получава така нареченото мехурче, което се изразява в това, че няколко степени на конвейера не обработват команди, т.е. бездействат и възможностите на процесора не се оползотворяват на 100%. При по-задълбочен анализ на проблема се забелязва, че двете ситуации при които е възможно получаване на мехурче, са условен преход и използване на резултат от една операция за операнд на следваща, което по същество е зависимост по данни.
Вече
изяснихме, че съществуват два подхода за откриване и отстраняване на между
командни зависимости: хардуерен и софтуерен. В хардуерния вариант обикновено в
първата степен на конвейера се определят дали между операндите има такива,
които се ползват от две команди. Ако има, то настъпва задръжка на изпълнението
на командата когато се достигне до момента на обръщение към въпросния операнд.
В софтуерния вариант компилаторът е натоварен със задачата за откриване и
отстраняване на зависимостите. Когато в програмата се наложи изпълнението на
една команда да бъде забавено се използват празни команди NOP (КОП=0x90
за процесори от тип i86). Така значително се облекчава проектирането и работата на процесора.
За разрешаване
на проблема с командите за преход се използва спекулативно изпълнение на
команди.
Изпълнението на команди от който и да е
клон на един условен преход, преди получаване на истинския целеви адрес на
командата за преход, е и се нарича спекулативно.
При срещане на
команда за условен преход обработката на условните преходи се може да протече
по един от следните два сценария:
1.
По-нататъшното изпълнение на
команди се преустановява до получаване на резултата от изпълнението на
командата за условен преход ;
2.
Започва изпълнение на команди от
единия или едновременно и от двата клона на прехода (в зависимост от това,
колко функционални устройства има конвейера).
В следващата таблица са сведени качествата на двата сценария.
|
|
Предимства |
Недостатъци |
|
1 |
Прост за реализация. Не замърсява кеш-паметта. |
В процесорите с конвейерна обработка се получава мехурче. |
|
2 |
Използването на ресурсите на процесора е 100%. При вярна прогноза на клона на прехода работата е свършена предварително. |
При
изпълнение на команди от неправилния клон на прехода се получава мехурче, а
също се замърсява кеш паметта за команди. |
Забележка: Под
замърсяване на кеш-паметта се разбира изхвърлянето от кеш-паметта на “полезни”
(използвани) страници и заместването им със страници, съдържащи команди от
неправилно изпълнения клон на прехода, които най-вероятно няма да бъдат
използвани скоро.
Именно вторият подход е примамлив, защото
ни предлага с някои модификации рязко да повишим производителността при едни и
същи експлоатационни условия, но за да извлечем пълна полза от него, ще трябва
вторичните ефекти от недостатъците му да бъдат намалени до минимум. Както вече
знаем от горната таблица, недостатъците са замърсяване на кеша за команди, и
като страничен ефект от това се получава натоварване на подсистемата на
паметта, а така също и получаването на мехурче. Отстраняването на тези
недостатъци е важно, защото те са в състояние да понижат производителността в пъти,
което разбира се обезсмисля прилагането на спекулативното изпълнение.
Има няколко подхода за реализиране на спекулативно изпълнение на команди и най-често прилаганите са:
·
Използване на няколко потока
команди: подходът е предложен от IBM, идеята е паралелно да се изпълняват
командите и от двата клона на разклонението, а когато резултатът от командата
за преход е готов, невярно изпълнените команди просто се игнорират ;
·
Предварителен избор на адреса на разклонение: когато се срещне команда за
условен преход за първи път, адресът, резултат от първото изпълнение на
командата, се запомня и при следващо срещане на командата се предприема
спекулативно изпълнение по запомнения адрес ;
·
Прогнозирано разклонение: този подход е най-разпространеният, а може би и най-ефективният
подход в спекулативното изпълнение. Той се реализира в хода на изпълнение на
програмата, като се запомнят най-често използваните команди за условен преход и
адресите на техните най-често предприемани преходи. Така при следващо
изпълнение на такава команда процесорът ще предприеме спекулативно изпълнение
по адрес на най-вероятния изход от разклонението.
Тук
ние ще разкажем за изпълнението на прогнозираното разклонение, тъй като то е
най-разпространено понастоящем, както и за промените, които то внася в
конструкцията на процесора. За да се реализира ползотворна спекулация с команди
е необходима тежка реорганизация на алгоритмите за управление на кеш-паметта,
на АЛУ и въвеждането на функционално устройство за предсказване на преходи,
даващо на процесорите възможност да “предскажат близкото бъдеще”.
За
разлика от използването на няколко потока команди, прогнозираното изпълнение
има един важен недостатък: той може да сгреши в предсказването на прехода, а
неправилното предсказване на клона за изпълнение в случая се явява основната
причина за силната проява на недостатъците на алгоритъма. Решението на
проблема е устройство за прогнозиране на преход (УПП). Неговата задача е да
събере статистическа информация за това кой преход колко пъти е преминал през
клона истина и колко през клона лъжа. Имайки тази информация ние можем с
достатъчно голяма точност да определим изхода от изпълнението на командите за
условен преход (за пример алгоритъма на M’cFarling гарантира между 88% и
99% успех в предсказването на изхода от условно разклонение). Почти всички
съвременни процесори имат такава функционална единица. Ролята на УПП в
процесора е толкова значителна, че алгоритъма на почти всички останали
функционални устройства се променя така, че да обслужват предсказания от УПП
изход от прехода. Оказва се че конструкцията на целия процесор се изгражда
около устройството за прогнозиране на преходите и алгоритъма на всички
функционални устройства се модифицира по следният начин:
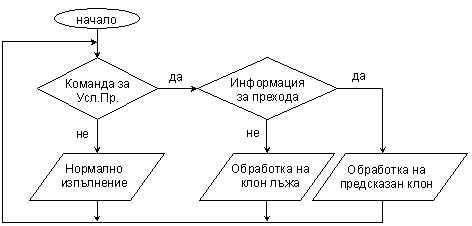
Фиг. 5.3.5.2. Обобщен
алгоритъм за работа с прогнозиране
Най-общо устройството за прогнозиране на
прехода се състои от малка кеш-памет, в която се държат следните данни: поле за адреса на командата за преход (в
зависимост от архитектурата 16/32/64/128 бита); поле за клона истина, съдържащо
число, което показва колко пъти изпълнението е преминало през него; и
аналогично поле за клона лъжа (касае се за пояснявано вече устройство – вижте фигура 5.3.4.3). Разбира се това е много обобщена
схема и тя значително може да се подобри, като например въведем ограничение за
дълбочината на следене на преходите (нека записваме само резултата от
последните 100 или 200 изпълнения на един преход) така винаги ще имаме актуална
информация а и ще отпадне необходимостта от запис на единия от клоновете.
Големината на кеша, съдържащ тази информация съществено се отразява на
бързодействието на процесора ето защо производителите се стремят да я направят
достатъчно голяма, например AMD влагат типично в своите процесори УПП за
следене на 2048 условни прехода. Важно е също да се отбележи че големината на
тази памет трябва да бъде съобразена с програмното осигуряване, което ще се
използва.
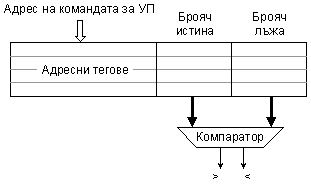
Фиг.
5.3.5.3. Схема за
използване на историята на преходите
При подаване на адреса на
командата за преход на асоциативната памет, в справочника на теговете се
извършва асоциативно търсене. Ако за командата е събирана история, ще се получи
съвпадение. От данновата част съвпадението ще извлече стойностите на броячите,
които попадат в компаратор - схема, определяща кой преход е с по-голям шанс за изпълнение. Управлението
на асоциативната памет трябва също да запомни адреса на командата за преход,
ако тя се среща за първи път. В пояснявания вариант кеш-паметта няма нужда да
записва целевия адрес на прехода, тъй като той принципно се съдържа в
командата, а адресът на клона лъжа е адреса на първата команда след командата
за условен преход, т.е. по съдържанието на програмния брояч. Трябва да се
отбележи, че тъй като е възможно програмно да се разменят местата на клон
истина и лъжа, объркване за УПП няма да настъпи, тъй като имената на двата
клона тук са само формални и УПП винаги ще прогнозира клона с по-висока
вероятност за изпълнение. Описаната структура представлява една различна
реализация на схема за прогнозиране на преходи и съответства на описаните в
предидущия пункт еднобитови и двубитови схеми.
Вече няколко
пъти споменавахме, че съществуват два варианта за натрупване на необходимата за
предсказване информация – динамичен и статичен. При първия вариант, при поява
на нови команди за преход (те са нови, защото в буфера на историята все още не
са записани техните тегове), процесорът безусловно приема направената от УПП
прогноза. В последствие информацията, натрупвана в УПП, все по-адекватно определя
прогнозата. Във втория вариант, при поява на нови преходи, процесорът изчаква
резултата от истинското изпълнение на командата за условен преход, т.е.
изчислението на целевия адрес. Така той игнорира прогнозата на УПП, докато
последното не натрупа достатъчен “опит” в прогнозирането на новия преход. Този
вариант ни гарантира забавяне на изчислителния процес поради задръжки в
конвейера при всяка нова програма или подпрограма или дори при подмяна на
страници в кеш-паметта за команди, ето защо този вариант не намира практическо
приложение и се използва само при симулации. Някои автори наричат тези варианти
за прогнозиране “оптимистичен” и “песимистичен” и дори има една смесица,
известна като “реалистичен” вариант. В този смесен вариант процесорът се подготвя
едновременно и за двата клона на разклонението. Изпълнението започва под
управлението на устройството за прогнозиране на прехода (УПП) и в опашката на
командите се зарежда командата от следващия адрес (обикновено това е първата
команда в клона лъжа). Така се получава, че в буфера се съдържат команди както
от клона лъжа, така и от клона истина. Логиката на това подсигуряване на
изпълнението е известна под името “Next Line Prefetch”. Това
“застраховане” цели да намали задръжките в конвейера при грешна прогноза. След
натрупване на надеждна информация за съответния преход, процесорът може да си
позволи да изхвърли от кеш-паметта ненужните команди.
Освен
описаните варианти съществува и един последен, чисто теоретичен, при който се
приема, че съществува някакъв механизъм, с помощта на който посоката на прехода
се разпознава във всички случаи. Този механизъм се нарича гадател и
естествено е физически не реализуем. Подобен подход обаче се използва в много
чисто теоретични изследвания за преодоляване на стохастиката в поведението на
изчислителния процес.
За
да получим пълна картина за процеса на изпълнение в съвременните процесори, ще
трябва да разгледаме и действието на кеш-паметта за команди, и как тя влияе на
скоростта на изпълнение.
Кеш-паметта
за команди е памет с изключително високо бързодействие и асоциативен достъп.
Логическата структура и функционирането й е разгледано в глава 6 на тази книга.
В логическата й организация няма нещо, което да може да бъде доусъвършенствано,
така че то да доведе до голямо повишение на ефективността й. Единствено
алгоритъмът й на функциониране (напомпване и изхвърляне на страници) може в
големи граници да влияе на нейната ефективност. Действието на кеш-паметта се
отразява на цялата система, тъй като тя се намира високо в йерархията на
паметта, при което, например, лошо избран алгоритъм за изхвърляне на страници
би довел до по-чести обръщения към основната памет, което пък води до излишно
натоварване на подсистемата на паметта и т.н.
Често при
проектирането на процесора не се обръща голямо внимание на кеш-паметта.
Кеш-паметта се използва да подобри бързодействието на системата като намали
времето за достъп до главната памет. В йерархията на паметта тя стои възможно
най-близко до АЛУ, като преди нея е само FIFO-опашката за команди. Така общата
картина на структурната организация е показана на фигура 5.3.5.4.
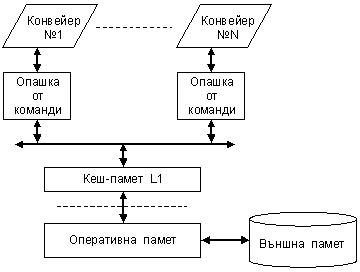
Фиг. 5.3.5.4. Схема за подхождане на командите към операционната част на
процесора
Чрез кеширане значително се
подобрява бързодействието, но ограниченият размер на кеша води редица негативни
последици, като например, изчакване напомпването на заявените блокове, ако те
не присъстват там, изхвърляне на използвани страници, за да се освободи място
за нови (често срещано явление при многозадачните операционни системи). При
програми с много далечни преходи и в силно натоварени многозадачни системи,
това понякога довежда до забавяне на системата. Тези проблеми се отнасят за
кеш-паметта за команди. В кеша за данни проблемите са още по сложни, например,
необходимостта от синхронизация на кеш-паметта с основната памет, а в много
процесорните системи е необходимо да се синхронизира и със съдържанието на кеша
за данни на всички процесори, заредили една и съща страница от паметта –
проблем, който се нарича кохерентност
на паметта (вижте пункт 6.3.2.2). Затова често
се казва, че кеш-паметта е едно необходимо зло, тя обаче практически е доказала
ефективността си и затова почти няма процесор, в който тя да не присъства.
Ще се спрем на
кеш-паметта за команди и най-вече как тя влияе върху спекулативното изпълнение.
В първите реализации на кеш-памет за команди напомпването се е преустановявало
при достигане на команда за условен преход. Този подход се оказва неефективен,
защото независимо от резултата на командата за условен преход, команди от един
от двата клона ще трябва да бъдат напомпвани, но със закъснение. Разбира се, в
чист вид тази стратегия не се прилага. Тя се оптимизира по начини, които са
изложени в пункт 6.3.1.
Едно частично решение на този недостатък произлиза от факта, че компилаторите разпределят програмния код след условен преход по следния начин:
Етикет |
Адрес |
Команда |
Коментар |
|
|
a |
Команда
за условен преход |
|
|
|
a+1 |
…
… … … |
Команда от клон лъжа |
|
|
a+2 |
…
… … … |
Още команди от клон лъжа |
|
|
a+k |
Команда
за безусловен преход към ЕТИКЕТ |
|
|
|
a+k+1 |
…
… … … |
Команда от клон истина |
|
|
a+k+2 |
…
… … … |
Команда от клон истина |
|
|
a+k+3 |
…
… … … |
Команда от клон истина |
|
|
a+m |
…
… … … |
Още команди от клон истина |
|
ЕТИКЕТ : |
a+m+1 |
|
Обща
точка на двата клона |
Отчитайки
още и факта, че статистически в повечето случаи се изпълнява клона лъжа, което
е вярно най-вече при цикли, то естествено се стига до идеята, че при
последователното напомпване на команди в кеша, при достигане на команда за
условен преход, следва да се продължи с напомпването на командите от клона лъжа.
За целта се прави предварителен анализ на КОП на всяка извлечена команда. Този
подход е достатъчно добър, за да бъде прилаган в по-ниско производителните
процесори без спекулативно изпълнение на команди. Той обаче няма място при
процесорите със спекулативно изпълнение на команди. При тях ние трябва първо да
се съобразим с прогнозния изход от изпълнението на командата за условен преход,
защото от това зависи каква операция ще започне да се изпълнява, и второ ние
можем с много по-голяма точност да предскажем кой от клоновете на прехода ще се
изпълни. Ясно е, че алгоритъмът на действие на кеш-паметта ще бъде силно
повлияно от тези фактори. Ето обобщена блок-схема на алгоритъма:
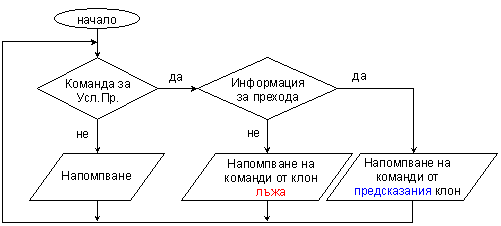
Фиг. 5.3.5.5. Обобщен
алгоритъм за работа в условия на кеш-памет
Вижда се, че управлението на
кеш-паметта работи чрез пряко взаимодействие с устройството за прогнозиране на
прехода. Всъщност всички функционални елементи на един процесор със
спекулативно изпълнение са тясно обвързани с това устройство, стремейки се по
този начин да поддържат командния конвейер запълнен на 100%.
Спекулативното
изпълнение на команди не може да бъде осъществено без някои промени в архитектурата
и на операционните устройства. Както вече знаем, при срещане на команда за
условен преход, изпълнението на програмата се “разпаралелва” при процесори с
няколко функционални устройства. Такава паралелна работа се наблюдава и при
дълги блокове от аритметични операции. Тогава всички функционални устройства
започват паралелно да изчисляват, а процесорът достига своята максимална
производителност от няколко команди за такт. В условията на няколко
конвейера, тази паралелност на изчисленията се постига чрез екипиране на
конвейерите с техни лични регистри на състоянието и програмен брояч, по
този начин те могат да работят псевдо независимо един от друг и от другите
функционални устройства. Когато процесорът реши, че може или трябва да
разапаралели обработката на програмата, той ще зареди “личния” програмен брояч
на първия свободен конвейер с началния адрес на блока, подлежащ на паралелно
изпълнение. Интересно в случая е, че процесорът има два режима на паралелна
обработка: при първия режим, паралелно обработените команди трябва да са
последователни в контекста на програмата.Тоест процесорът ще обработи няколко
последователни команди от програмата паралелно в няколко от своите конвейери, а
управлението на програмния брояч на всеки конвейер се поема от процесора и е
важно да се отбележи, че командите, които се обработват в един конвейер, не са
последователно извлечени. Този режим се използва типично при обработка на
големи последователности от аритметични команди. При втория режим
процесорът ще обработва няколко (типично 2) независими блока от програмата,
независимо един от друг в конвейерите си. В този режим процесорът зарежда
програмните броячи на конвейерите с началния адрес на блока и ги оставя на
самоуправление, което се изразява в автоматично посочване адреса на следващата
команда за изпълнение. Така конвейерите работят, докато не бъдат прекъснати от
процесора или докато не достигнат края на блока. Режимът е само за спекулативно
изпълнение на команди. Той е неприложим за дълги последователности от команди,
защото резултатите от изпълнението няма да са последователни в контекста на
програмата, което би нарушило логическата последователност на изпълнение.
Типично, блоковете, които се обработват така, са с дължината на конвейера, това
дава на процесора няколко такта, в които да реши по кой от двата клона да
продължи.
След извличане
на една команда процесорът ще я подложи на серия тестове за да реши как
най-бързо да я изпълни. Типично тестовете са:
·
Проверка за междукомандни
зависимости ;
·
Проверка, дали командата е за
условен преход ;
·
Проверка, дали това е команда за
програмно прекъсване.
В зависимост от резултата от
всяка проверка винаги има два възможни изхода:
1.
Ако командата е с междукомандни
зависимости: процесорът ще отложи нейното изпълнение, докато зависимостта
отпадне. Тук трябва да уточним, че като цяло има два метода за отлагане
изпълнението на команда: първият е директен – подаването на команди към
конвейерите се прекратява до отпадане на зависимостта. Вторият метод е
значително по-ефективен: отлага се изпълнението само на командата със
зависимост, по този начин конвейерите на процесора се оползотворяват по-добре ;
2.
Ако командата е условен преход,
то процесорът се подготвя за спекулативно изпълнение. В зависимост от
архитектурата си той или ще се допита до УПП, или ще започне паралелно
спекулиране по двата клона.
Случаят с команда за програмно прекъсване е по-интересен. Тъй като програмното прекъсване ще преустанови изпълнението на текущата програма и ще предаде управлението на операционната система, то предварително е ясно, че по-нататъшно напомпване и изпълнение на команди от тази програма е безпредметно. Това е така, защото след прекъсването операционната система ще започне изпълнение, което ще доведе до почти пълно обновяване на кеш-паметта и до промяна на съдържанието на буфера на историята на преходите, т.е. на УПП. По тази причина процесорът е най-добре да започне подготовка за прекъсването.
Ако проверката на командата не е генерира нито един от горе изброените случаи, то тя е физически независима от другите и може да бъде изпълнена паралелно с други команди в някой от конвейерите на процесора.
Нека
разгледаме как на практика се прилага спекулативното изпълнение на команди, в
процесор P5 на Intel. Pentium е суперскаларен процесор, съдържащ
две устройства за целочислена аритметика; едно устройство за работа с числа,
представени във форма с плаваща запетая; отделни кеш-памети за команди и данни
от по 8К; устройство за предсказване на преходи и устройство за управление на
паметта. Процесорът може да изпълни максимално 3 инструкции за един такт. Двата
целочислени конвейера се 5 степенни и са разделени на следните фази:
1.
Извличане на команда: извличането на команди и данни може да бъде съвместено
в един такт. Когато се извлече команда за условен преход, чрез УПП, който тук
се нарича Branch Target Buffer (ВТВ), се предсказва дали преходът ще се
изпълни или не. Ако прогнозата е за изпълним преход, то в буфера на втория
конвейер започва напомпване на команди. Ако прогнозата е била грешна,
конвейерът се изчиства ;
2.
Декодиране на командата: определя се типът на командата и се взима решение дали
тя може да се разпаралели в двата конвейра ;
3.
Декодиране на адреса ;
4.
Изпълнение на командата ;
5.
Обратно записване.
Двата
конвейера не са еднакви, единият може да изпълнява всяка команда от набора
команди на процесора, докато вторият може да изпълнява само прости команди за
целочислени операции, които се изпълняват апаратно и не изискват микрокод. Това
е направено с цел опростяване управляващата логика и за намаляване размерите на
кристала необходим за изграждането на процесора. Кеш паметта на устройството за
предсказване на прехода в този процесор има структурата, показана на фигура 5.3.4.3.
Ако във втора фаза на конвейера се открие команда за условно разклонение, то нейният адрес се използва за обръщение към BTB, т.е. към устройството за прогнозиране на прехода, за да се определи целевият адрес, който да се използва от програмния брояч и да започне извличане на кода от паметта. Разклоненията на програмите могат да се изпълняват паралелно с други целочислени операции. При грешно прогнозиран преход следва пълно изчистване на конвейерите и повторно извличане на програмния код.
Б) Процесори с дълга командна дума
В архитектурата на така наречените
VLIW-процесори се създава възможност за минимизиране на апаратурата, която е
необходима за реализация на паралелното зареждане на няколко команди, тъй като
потенциално колкото по-голям е броят на паралелно зарежданите команди, толкова
по-голяма е икономията на апаратни средства. Например, суперскаларният
процесор, осигуряващ паралелно зареждане на 2 команди, изисква паралелен анализ
на 2 КОП, 6 адресни полета на регистри, а така също изисква динамичен анализ на
възможността за зареждане на две команди, както и разпределението им по
функционални устройства. Въпреки, че изискванията към обема на апаратурата за
паралелно зареждане на 2 команди остават достатъчно умерени и може даже да се
увеличи степента на разпаралелване до 4 (което се прилага в съвременните
процесори), по-нататъшното увеличаване броя на паралелно зарежданите за
изпълнение команди води към значително нарастване на сложността на реализацията
поради необходимостта от определяне на реда на командите и съществуващите между
тях зависимости.
VLIW-архитектурата се базира на множество
независими функционални устройства. Вместо да се опитваме да зареждаме
паралелно в тези устройства независими команди, в такива архитектури в една
дълга команда се “опаковат” няколко операции. При това отговорността за
паралелното зареждане на тези няколко операции се възлага изцяло на
компилатора, а апаратните средства за суперскаларната обработка изцяло
отсъстват.
VLIW-командата може да включва например,
две целочислени операции, две операции с плаваща запетая, две операции
обръщение към паметта и операция за преход. Такава команда ще има в структурата
си няколко полета, предназначени за отделните функционални устройства.
Дължината на тези полета практически се намира в интервала от 16 до 24 бита,
което определя дължината на цялата команда в интервала от 112 до 168 бита.
Ще разгледаме изпълнението на цикъл, в
който елементите на един масив се увеличават с единица, върху VLIW-процесори,
предполагайки, че едновременно могат да се зареждат 2 операции обръщение към
паметта, 2 операции с плаваща запетая и една целочислена операция или една
команда за преход. По-долу в таблица 5.3.5.2 е показан кода на този цикъл.
Цикълът е разгънат 7 пъти, което позволява да бъдат отстранени всички възможни
задръжки в конвейера. Едно преминаване през разгънатото тяло се изпълнява за 9
такта, при което се изчисляват 7 резултата. По този начин за изчисляване на
всеки резултат се разходват 1,28 такта (за сравнение ще припомним числото 2,4
такта – времето за изчисляване на един резултат в суперскаларния процесор).
Таблица 5.3.5.2 Разгъване на VLIW-цикъл
|
Обръщение към
паметта №1 |
Обръщение към
паметта №2 |
Операция с ПЗ №1 |
Операция с ПЗ №2 |
Операция с ФЗ или
преход |
|
LOADD F0, 0(R1) |
|
|
|
|
|
LOADD F10, -16(R1) |
LOADD F6, -8(R1) |
|
|
|
|
LOADD F18, -32(R1) |
LOADD F14, -24(R1) |
ADDD F4, F0, F2 |
|
|
|
LOADD F26, -48(R1) |
LOADD F22, -40(R1) |
ADDD F12,F10,F2 |
ADDD F8, F6, F2 |
|
|
STORED 0(R1), F4 |
STORED -16(R1), F4 |
ADDD F20,F18,F2 |
ADDD F16,F14,F2 |
SUBI R1, R1, #48 |
|
STORED -16(R1), F4 |
STORED -24(R1),F16 |
ADDD F28,F26,F2 |
ADDD F24,F22,F2 |
BNEZ R1, Loop |
|
STORED -32(R1),F12 |
STORED -40(R1),F24 |
|
|
|
|
STORED 0(R1), F4 |
|
|
|
|
За
процесори с VLIW-архитектура е разработен метод за планиране на потока
(разбирайте на зареждането) под името “трасиращо планиране”. При
използване на този метод, на базата на изходната последователност от команди се
генерират дълги команди чрез разглеждане на програмата далеко зад границите на
основните блокове. Както вече беше определено – под базов блок разбираме линеен
участък от програмата без разклонения.
От гледна точка на архитектурните идеи,
вложени в процесора с дълга командна дума, същият можем да разглеждаме като
разширение на една RISK-архитектура. Както и в RISK-архитектурата, апаратните
ресурси на VLIW-процесора са предоставени на компилатора и те се планират
статически. В процесорите с дълга командна дума към тези ресурси се отнасят конвейерните
функционални устройства, шините и банките памет. За поддържане на висока
пропускателна способност между функционалните устройства и регистрите се налага
използването на няколко различни масива от регистри. Апаратното разрешаване на
конфликтите се изключва и се отдава предпочитание на по-елементарна логика за
управление. За разлика от традиционните архитектури, за регистрите и шините не
се прилага техниката на резервиране. Същите се използват изцяло по време на
компилацията.
В
процесори от вида VLIW, освен това, принципът за управление по време на
изпълнение на програмата е заместен с планиране по време на компилиране, което
също така се разпространява и върху запомнящата система. За поддържане
заетостта на конвейерните функционални устройства е необходимо да бъде
осигурена висока пропускателна способност на паметта. Един от съвременните
подходи за увеличаване на пропускателната способност се състои в изграждане на
широка даннова шина и използване на разслоеното адресиране на клетките в
паметта (вижте обясненията в точка Б) на §6.2).
В системи с разслоена памет обаче е възможен конфликт по банка, ако дадената
банка е все още заета с предидущото обръщение. В обикновените системи заетото
състояние на банките се следи с апаратни средства и се проверява когато от
процесора постъпи заявка за обръщение към паметта. В VLIW-процесорите тази
функция е предоставена на програмни средства. Възможните конфликти по банки се
определят от специален модул на компилатора – модул за предотвратяване на
конфликти.
Откриването
на конфликти не представлява задача за оптимизацията на програмата – това
по-скоро е функция за контрол на коректността на изпълнението на операциите.
Компилаторът трябва да е способен да определя, дали конфликтите са невъзможни
или в противен случай да може да допуска, че може да възникне най-лошата
ситуация. В определени ситуации просто решение не съществува, например, когато
се извършва обръщение към масив, а индексът на обръщението се изчислява по
време на изпълнението на програмата. Ако компилаторът не може да определи дали
ще възникне конфликт, операциите не могат да се планират за паралелно
изпълнение, което води до снижаване на производителността.
Компилаторът
с трасиращо планиране определя участък от програмата без преходи назад, който
става кандидат за съставяне на разписание. Преходите назад обикновено са към
входни точки на цикли. Тук методиката за разгъване на циклите води до
образуване в програмите на дълги линейни фрагменти. Ако една програма съдържа
само преходи напред, компилаторът предлага евристична прогноза на преходите в
разклоненията. Алгоритмичният път на изпълнението, образувано от най-вероятните
преходи, се нарича трасе. Това трасе се използва при оптимизация на
кода, като се отчитат зависимостите по данни между командите и ограниченията на
апаратните ресурси. По време на планирането се генерира дългата командна дума.
Всички операции, групирани в дългата командна дума, се зареждат едновременно и
се изпълняват паралелно.
След
обработката на първото трасе се пристъпва към планиране на следващия път
(трасе), който има максимална вероятност, като изключим вече обработения.
Процесът на опаковка на командите в последователната програма продължава,
докато не завърши оптимизацията на цялата програма.
Ключовото условие за постигане на ефективна работа на VLIW-архитектурата е коректното предсказване на условните клонове на програмата. Преход с връщане назад се изпълнява за всички итерации на цикъла, за изключение на последната. По този начин, прогнозата, която се изготвя от самите преходи назад ще бъде коректна в повечето случаи. При други условни преходи, например, при обработка на препълване или при проверка на гранични условия (проверка за излизане извън границите на масив), прогнозирането също е достатъчно надеждно.
Следващият раздел е: