Последната актуализация на този раздел е от
2020 година.
5.3.8 Концепция EPIC – явен паралелизъм на ниво команди
Концепцията,
наречена EPIC (Explicitly Parallel Instruction Computing), представлява
нов тип архитектура, която е способна да се конкурира по мащабите си на влияние
с RISC-архитектурата. Същността на разбирането за EPIC-архитектурата се
изразява от нейната цел, а тя е опростяване на апаратурата и едновременно с
това извличане на “скрития паралелизъм” на ниво команди в степен по-голяма от тази,
която са способни да постигнат суперскаларните или VLIW-архитектурите.
Паралелизмът
на ниво команди (ILP – Instruction Level Parallelism) стана възможен
след създаването на съответните процесори и методики за компилиране, които
ускоряват изпълнението на отделните RISC-операции, нещо което ние вече
пояснихме. ILP-системите използват програми, които са написани на традиционни
езици за последователни процесори, върху които благодарение на приложението на
съответната технология за компилиране и съответната й апаратна поддръжка, се
изявява и оползотворява “скритият” в програмния код паралелизъм. Фактът, че
тези системи не изискват от приложните програмисти допълнителни усилия, има
крайно важно значение. Така, към настоящия момент, паралелната обработка на ниво
команди се приема за единствения надежден подход, който позволява увеличаване
на производителността, при това без фундаментална преработка на програмните
приложения. Предполага се, че в близкото бъдеще най-ефективните многопроцесорни
системи най-вероятно ще се създават на базата на ILP-процесори.
Ние
вече пояснихме, че тази компютърна архитектура представлява своеобразна
уговорка между определен клас програми, написани за дадена архитектура и
множество механизми за нея, реализирани в процесора. Като правило тази уговорка
засяга формата и интерпретацията на отделните машинни команди. Когато обаче
става дума за ILP-архитектури, тази уговорка се разширява, като в нея се
включват и механизмите за реализация на възможния паралелизъм между командите
или операциите. Два от най-важните съвременни типа ILP-процесори се различават
точно в този аспект.
Суперскаларните
процесори – това са реализации на ILP-процесора за последователни архитектури,
програмите за които не могат да подават точна информация за пралелизмите в
кода. По тази причина задачата за откриване на паралелизмите се решава с
апаратни средства, която трябва да създава план за действията, свързани с
откриването на “скрития паралелизъм”.
VLIW-процесорите
(процесори с дълга командна дума) представляват пример за архитектура, за която
програмата предоставя точна информация за паралелизма на кода. Последният се
изявява от компилатора като съобщава на апаратурата, кои операции не зависят
една от друга. Така апаратурата, без да прави излишни проверки, кои операции
може да стартира едновременно в текущия такт.
EPIC-архитектурата
представлява еволюция на VLIW-архитектурата, която “абсорбира” и адаптира в
себе си много от концепциите на суперскаларната архитектура. В същност, EPIC е
идеология, концепция, разбиране, за това как да бъдат създавани ILP-процесори.
В този смисъл EPIC прилича на RISC, т.е. определя клас архитектури, подчиняващи
се на общи принципи. По този начин, така както и за RISC-архитектурите, могат
да съществуват различни EPIC-процесори с различни командни системи,
предназначени за различни приложения. Приема се, че първата комерсиална EPIC
система, е архитектурата IA-64.
А) Основни
недостатъци на последователните архитектури
Ярък
представител на последователните архитектури, направил реален опит в своето
развитие да реши съвременните проблеми, е архитектурата IA-32, в лицето на
микропроцесор Pentium II. Тази архитектура, определяща се като CISC, се
характеризира със система машинни команди, които имат различна дължина и
огромно количество формати. Тези команди трудно могат да се декодират бързо и
равномерност в темпото им е непостижима. Тази сложност на системата команди в
комбинация с амбициите за реализация като ILP-система, води до реализация на
микрооперационно RISC-ядро, обслужвано от изключително сложно и обемисто
апаратно осигуряване, което снижава производителността и усложнява еволюцията
на архитектурата. В това се състои основният недостатък на тази архитектура.
IA-32-архитектурата
е ориентирана към двуадресни команди. Те не съответстват на идеологията за
простота, каквито са системите, притежаващи команди от тип “зареждане” /
“съхранение”, които са регистрови. В системите машинни команди от регистров тип
операциите с обръщение към оперативната памет се изпълняват рядко и само в
случаите, когато следва да се разтоварят регистровите файлове. И тъй като
скоростта на процесорите расте много по-бързо от тази на паметта, положението в
системи с IA-32 се влошава, което е нов явен недостатък.
IA-32-архитектурата
притежава малък по обем и нерегулярен набор от регистри. Изключително малкият
брой регистри с общо предназначение, непрекъснато се налага междинните
резултати да се записват в паметта. Така относителният дял на обръщенията към
паметта нараства без особени причини, а това е трети сериозен недостатък.
Недостатъчният
брой регистри поражда множество ситуации със зависимости, които е невъзможно да
бъдат разрешени, особено такива от тип WAR, тъй като междинните резултати много
често няма къде да се поместят временно – липсват свободни регистри. Налага се
използването на виртуални регистри. В същото време, за да се снижи честотата на
кеш-пропуските, се прилага непоследователно стартиране на команди, докато
записването на техните резултати трябва да бъде в предписания от програмата
ред. Управлението на всички тези сложни ситуации се осигурява от изключително
сложно и обемисто апаратно осигуряване. Това е следващ сериозен недостатък.
За
да се постигне висока скорост (производителност) конструкторите отиват към
използването на дълбоки конвейери (12 и повече нива), което означава, че
изпълнението на машинните операции се удължава до 11 и повече цикъла. При
такава голяма дълбочина на конвейерите задръжките, които се появяват при
определяне и предсказване на преходите, също се увеличават. За целта степента
на точност на прогнозите следва да се повишава, което означава поредно
набъбване на апаратурата и е пореден недостатък.
За
да се натоварва дълбокият конвейер се минава към спекулативно стартиране на
команди, което води до нови още по-сложни за решаване проблеми. Това вече е нов
пореден сериозен недостатък.
В
резултат на всичко казано се вижда, че огромното количество транзистори в
процесора е предназначено за преобразуване на CISC командите в RISC такива по
изпълнение, за разрешаване на множество сложни конфликти, за сложно
прогнозиране на преходите, за множество поправки на неправилните прогнози и
т.н. Оставащата незначителна част от транзисторите се изразходва за реална
работа, необходима и предвидена от потребителя. Изводът е неизбежен – необходима
е нова концепция, нова архитектура.
Б) Причини за
създаване на EPIC
Приема
се, че тази концепция започва да се създава от специалисти на НР (Hewlett-Packard)
през 1990 година, но самото наименование е възприето през 1997 година, след
създаването на обединението HP-Intel. Това е времето, когато най-популярна е
суперскаларната технология. Стараейки се да оценят перспективите проучванията
водят два извода: първо производствените технологии се развиват и неизбежно
водят към възможността за разполагане на цялостен ILP-процесор върху една
кристална подложка; второ, постоянно увеличаващата се сложност на
суперскаларните архитектури неизбежно води до негативно влияние върху тактовата
честота и незадоволително нарастване на производителността на микропроцесорите.
Основната цел при разработване на новата архитектура е способността й да
осигури висока степен на паралелизъм на ниво команди и в същото време да
опрости апаратното осигуряване.
Преследван
е отказ от възможността за непоследователно изпълнение на командите – една
елегантна, но скъпа методика, започнала от IBM System 360/91 и прилагана в
много суперскаларни процесори. Алтернативните VLIW-архитектури, в своя начален
вариант (Multiflow, Cidrome – 1989, 1993 година), формално осигурявали
висок паралелизъм на ниво команди и простота на апаратурата, но тяхното
приложение не било универсално. Те не били подходящи за скаларни приложения с
интензивни разклонения, активно използващи указатели. В същото време
конкурентните RISC-процесори имат сравнително ниска производителност при
изпълнение на числови приложения. При тези условия става ясно, че новият тип
архитектура трябва да бъде архитектура с общо предназначение, т.е. архитектура,
която достига висока степен на паралелизъм както в числови, така и в скаларни
приложения. Освен това тази архитектура трябва да осигурява адекватна
съвместимост на обектния код между процесорите в едно развиващо се семейство,
което е абсолютно необходимо за процесори с общо предназначение, нещо, което
VLIW-архитектурите не осигурявали.
Програмният
код за суперскаларните процесори съдържа последователност от команди,
изпълнението на която поражда коректен резултат. Кодът е израз на конкретен
алгоритъм и с изключение на това, че е реализиран в конкретната система машинни
команди, не отразява природата на апаратното осигуряване, върху което ще се
изпълняват командите. За разлика от програмите за суперскаларните процесори,
VLIW-кодът предлага точен план за това, как процесорът ще изпълни програмата.
Този план е създаден статически от компилатора. Точността в плана се изразява в
това, че кодът точно указва кога ще се изпълни дадена операция, кои устройства
ще работят и кои регистри ще съдържат операндите. Компилаторът VLIW създава
този план за изпълнение (POE – Plan Of Execution), имайки пълна представа
за структурата на VLIW-процесора. При това създава този план така, че да
постигне исканите записи за изпълнение (ROE – Record Of Execution) –
последователност от събития, които действително става по време на изпълнение на
програмата.
Компилаторът
предава РОЕ във вид на набори от командни думи (вижте пункт
5.3.5). Този план позволява на VLIW-процесора, с помощта на относително
просто апаратно оборудване, да постигне висока степен на паралелизъм на ниво
команди. За разлика от VLIW, суперскаларното оборудване строи подобен план
динамично, върху текста на последователния код. Въпреки, че този подход води до
увеличена сложност на апаратурата, суперскаларният процесор създава РОЕ, като
използва предимствата на онези фактори, които могат да бъдат определени
единствено по време на изпълнение на програмата.
Паралелното изпълнение на машинни команди следва да реши
три основни задачи:
1.
Анализ на командите и връзките
между тях с цел групиране на тези от тях, които могат да се изпълнят паралелно
;
2.
Планиране на командите за
изпълнение върху съответните операционни устройства ;
3.
Декодиране на командите и
изпълнение.
Различните
класове паралелни архитектури се различават именно по това каква част от
горните задачи се изпълняват апаратно или програмно. Типичните архитектури на
това ниво са илюстрирани в следващата таблица.
|
Вид на
архитектурата |
Групиране |
Планиране на операционно устройство |
Иницииране на изпълнението |
|
Суперскаларна |
Апаратно |
Апаратно |
Апаратно |
|
EPIC |
Компилатор |
Апаратно |
Апаратно |
|
Динамична VLIW |
Компилатор |
Компилатор |
Апаратно |
|
VLIW |
Компилатор |
Компилатор |
Компилатор |
В) Основни принципи в технологията на явния
паралелизъм
При
разработване на технологията за явен паралелизъм се цели да се използва
принципът за статично планиране на потока команди. В същото време обаче се цели
и обогатяване на неговите възможности за по-добро отчитане на динамичните
фактори, аналогично на възможностите на суперскаларните процесори. За тези цели
концепцията EPIC залага на следните принципи:
1. Създаване на плана за изпълнение по време на компилация.
Създаването
на компилатор, който може да реши тази задача, изисква да се разчита на
предсказуем и управляем процесор. Динамичното преподреждане и
непоследователното изпълнение на команди може да “обърка” компилатора и той да
не може да разбира как неговият план влияе на реалното изпълнение (на реалното
ROE), създавано от самия процесор. Ето защо за предпочитане е “послушен”
процесор, който прави това, което иска програмата.
Създаването
на плана за изпълнение РОЕ по време на компилация се състои в подходящо
преподреждане на операциите в последователния код така, че да се оползотворят
всички форми на паралелизъм, които приложението съдържа и в същото време да се
постигне максимално натоварване на апаратните ресурси, така щото да се минимизира
времето за изпълнение на програмата.Най-доброто преподреждане може да бъде
постигнато само ако то се поддържа от съответни архитектурни възможности. Тъй
като концепцията EPIC приема създаването на плана за изпълнение да бъде
извършено от компилатора, тя е длъжна да осигури архитектурни възможности,
които ще поддържат интензивно преподреждане на програмния код по време на
компилация.
2. Използване на вероятностни оценки от компилатора.
Съответстващият
на архитектурата EPIC компилатор се изправя пред сериозен проблем при създаване
на плана за изпълнение, предвид на това, че за това е необходима информация за
хода на изчислителния процес, която става известна (истинна) едва в съответната
точка на изпълняващата се програма. Например, компилаторът няма как да знае кой
от клоновете след команда за преход ще се изпълни, докато не се установи
истинната стойност на проверяваното условие. Освен това, обикновено е
невъзможно да се създаде статичен план, който едновременно оптимизира всички
пътища в програмата. Нееднозначност възниква също така и в тези случаи, когато
компилаторът не може да реши дали указателите ще сочат едно и също място в
паметта. Ако да, то в блок-схемата (алгоритъма) обръщението към тях трябва да
се извършва последователно, а ако не, то те могат да бъдат планирани за
изпълнение в произволен ред. При такава нееднозначност често се разчита на
някакъв най-вероятен конкретен резултат.
Един
от най-важните принципи в основата на разглежданата концепция представлява
възможността да бъде разрешено на компилатора да оперира в такива ситуации с
вероятностни оценки. Това ще означава, че компилаторът ще създава и оптимизира
плана за изпълнение РОЕ, залагайки на най-вероятните ситуации. За да гарантира
коректността на изпълнението на програмата и на нейните резултати обаче, се
предполага, че е реализирана апаратна поддръжка на такива механизми, като
спекулативното изпълнение по управление и по данни.
Когато
по време на изпълнението на една програма се явяват неверни прогнози,
производителността й спада. Такъв спад на производителността се наблюдава в
планове, които са създадени върху силно оптимизирана програмна област, а кодът
се изпълнява в слабо оптимизирана област. Спад на производителността може да се
наблюдава по причина на задръжки в конвейерите (Stall Cycle), явяващи се
при зависимост по данни, които в плана на програмата няма как да бъдат видени.
3. Апаратно изпълнение на плана.
Създаденият
от компилатора обектен код съдържа по същество плана за изпълнение. Системата
от машинни команди на дадения процесор, в която е генерирана машинната
програма, трябва да притежава достатъчно богати възможности, за да предаде на
апаратурата решенията на компилатора – кога да стартира дадена операция, какви
ресурси да използва, кои операции са предвидени за едновременно изпълнение.
Както вече беше казано, целта на EPIC концепцията е да се избегне
необходимостта от динамично планиране.
Планът
за изпълнение следва да е в състояние своевременно да предоставя на апаратурата
необходимата информация. Тук става дума най-вече за командите за преход. Вече
коментирахме достатъчно подробно, че в случаите на изпълнение на такива
команди, адресите за преход следва да се подготвят предварително и информацията
по тях да се извлича изпреварващо, преди още да е извършена проверката за преход.
За разлика от разгледаните вече решения на този проблем, в съответствие с
принципите на EPIC, тази информация се предава на апаратурата точно и
своевременно посредством програмния код.
Апаратните
схеми за управление на процесора на микрооперационно ниво вземат множество
решения, които не са пряко свързани с изпълнението на програмния код, но те
съществено влияят на производителността на програмата. Основен пример за това е
логиката за управление йерархичната система от буферни памети (разгледана в глава 6). Тук апаратно се изпълняват множество
алгоритми за поддържане на актуално съдържание както в буферните памети, така и
в оперативната памет. Концепцията EPIC поддържа и разширява принципа за
използване на кеш-паметите, като заставя компилатора да създава такъв план, че
да е възможно управление на механизмите на тези памети. За целта
EPIC-архитектурата предполага реализирани възможности за осъществяване на
програмен контрол на механизмите, които обикновено управлява апаратната
микроархитектура.
4. Архитектурни възможности за поддръжка на концепцията
EPIC.
EPIC
използва компилатора за създаване на статично планиран код, който позволява на
процесора да извлече и реализира колкото се може повече “скрит паралелизъм”,
използвайки за целта широка шина за зареждане на команди (wide issue-width)
и дълги конвейери с голяма задръжка (Deep Pipeline-Latency), които обаче
имат сравнително просто апаратно управление. Предполага се, че EPIC води до
опростяване на два ключови момента, които се реализират във времето. Първо EPIC
позволява да се откажем от проверката за зависимости между операциите по време
на изпълнението, които компилаторът вече е обявил за независими. Второ, EPIC
позволява да се откажем от сложната логика за преподреждане и
непоследователното изпълнение на команди, залагайки единствено на реда,
определен от компилатора. Така EPIC усъвършенства възможностите на компилатора
за статично генериране на добри планове за изпълнение, като поддържа
разнообразни техники за разместване в кода още по време на компилиране, които
биха били некоректни в една последователна архитектура.
5. Статично планиране.
Команда
MultiOp означава, че няколко операции трябва да бъдат заредени
едновременно. Всяка операция в командата MultiOp е еквивалентна на една
последователна RISC или CISC такава. Компилаторът е този който определя
операциите, чието зареждане е планирано да става едновременно, като ги
обединява в командата MultiOp. При зареждане на тази команда в
конвейера, апаратурата не е длъжна да извършва проверка за зависимости между съставящите
я операции. Нещо повече, с EPIC-кода се свързва понятието виртуално време
(Virtual Time). По определение, за един цикъл от виртуалното време, в
конвейера се зарежда само една команда MultiOp. Това виртуално време
осигурява времева рамка за изпълнение на плана на програмата. Виртуалното време
се различава от реалното тогава, когато при изпълнението на програмата,
апаратурата за управление на конвейерите вмъква задръжки, които компилаторът не
е предвидил.
Традиционните
последователни архитектури определят изпълнението като последователност от
“атомарни” операции, като изпълнението на всяка операция завършва преди
началото на следващата. Такава архитектура на допуска възможността за четене и
запис в регистър при една операция да се застъпва във времето с четене или
запис в регистър от друга операция. В този смисъл операциите в командата
MultiOp не са атомарни. При изпълнение на операциите в тази команда, те могат
да четат или да записват данни в регистрите, независимо една от друга. Ние вече
показахме в преходите пунктове, че това се постига чрез допълнително буфериране
на степените на конвейерите. Така дава възможност неатомарността и задръжките
на операциите да се определят на архитектурно ниво.
Въвеждането
на понятието NUAL (Nonunit Assumed Latency), което следва да разбираме
като предполагаема задръжка на няколко такта, се оправдава главно със
стремежа да се постигне простота в апаратурата за такива операции, които на
практика се изпълняват за няколко такта. Ако апаратните схеми за управление
могат да бъдат сигурни, че дадена операция няма да се опита да използва един
резултат преди да го е генерирала пораждащата го операция, то на него не са му
необходими функции за вътрешна блокировка (interlock) или за “спиране”.
Ако
при това компилаторът може да бъде уверен в това, че операцията няма да записва
своя резултат преди да изчезне предполагаемата задръжка, той може да уплътни
плана за изпълнение, като планира операция-приемник (независима или зависима от
резултата) преди периода от време, равен на предполагаемото задържане на
операцията. VLIW-процесорите традиционно използват тази техника. NUAL служи
като своеобразна гаранция за приетите уговорки между компилатора и апаратното
осигуряване за това, че двете страни взаимно ще се придържат към приетите за
себе си задължения. Ако по някаква причина реалните и задръжки на процесора се
различават от предполагаемите, апаратното осигуряване трябва да гарантира
коректност на семантиката на програмата, използвайки за тази цел съответни
механизми. Операция, която има предполагаема архитектурна задръжка от един
такт, наричаме операция UAL (Unit-Assumed-Latency). Операция UAL също не
е атомарна.
MultiOp
и NUAL, това са две от най-важните особености на предаването на плана за
изпълнение, създаден от компилатора, към апаратурата. Те позволяват на
процесорите с явен паралелизъм на ниво команди, които не поддържат вътрешна
блокировка, или поддържат, но с преподреждане, ефективно да изпълняват
програми, чийто код е в силни ILP-системи.
6. Решение на задачата за преход.
След всичко казано в предходните пунктове, ето че отново трябва да дискутираме тази тема, но това не ни учудва, защото тя е фундаментална и е от голямо значение в търсенето на съвършенството. Много приложения съдържат голям брой преходи. Задръжката при преход се измерва с броя тактове на процесора от началото на прехода до момента, в който започва изпълнението на командата от целевия адрес. По време на задръжката се изпълняват няколко действия. Изчислява се истинната стойност на условието, изчислява се (предсказва се) адресът за преход, извлича се и се декодира командата от прехода. Въпреки, че традиционните командни системи указват прехода като единна операция, предприеманите действия в същност се изпълняват в различни моменти, като по този начин определят задръжката.
Невъзможността
за паралелно изпълнение на приемлив брой операции с разклонения силно понижава
производителността. Това е особено неприятно за процесори с дълги командни
думи, които могат да загубят множество слотове (гнезда) за зареждане за всеки
такт от задръжката на прехода. EPIC допуска създаване на статични планове за
изпълнение с цел осигуряването на максимално припокриване на отделните
обработки на прехода и осъществяване на други изчисления, предоставяйки
апаратни възможности, които поддържат следните функции:
1.
Отделяне на действията,
съставляващи прехода;
2.
Поддържане изключването на
преходи;
3.
Оптимизирано поддържане на
статичното преместване на операции през няколко прехода.
Разделени
преходи. Преходите според EPIC се разделят на три части:
1.
Подготовка за прехода (ПЗПр.) –
изчислява се целевия адрес на прехода;
2.
Сравнение (Ср.) – определя
стойността на кода на условието;
3.
Реален преход (РПр.) –
изпълнение на прехода.
Компилаторът
може да планира операциите подготовка за преход (ПЗПр.) и сравнение (Ср.) дълго
преди момента на реалния преход, за да може своевременно да предостави
информация на апаратурата. При изпълнение на ПЗПр. апаратурата може да изпълни
спекулативно зареждане на команди по адреса за преход. След изпълнение на
операция Ср. апаратурата може да определи дали даденият преход ще бъде избран,
да се откаже от незадължителното спекулативно зареждане, а така също да
стартира предварителното неспекулативно зареждане. Тези механизми допускат
припокриваща се обработка на компонентите на прехода, основавайки се само на
статичното преместване на компонентите на прехода.
Предикатно
изпълнение. Предикатното изпълнение (Predicate
– твърдение, изказване, предикат) представлява нов начин за обработка на
условните преходи. Концепцията за явен паралелизъм на ниво команди намалява
отрицателното влияние на преходите върху производителността за сметка на
отстранените преходи, което се постига чрез предикатно изпълнение. Последното
се постига благодарение на методиката за компилация, наречена условно преобразуване
(if-conversion). Методика за условно изпълнение на командите беше вече
разяснявана в предидущия пункт, но тук отново ще бъде пояснена във връзка с
това, че тя представлява един преходен етап в развитието си към предикатното
изпълнение. Ще разгледаме следния пример с условно изпълнение на команди, които
реализират следната конструкция if:
if (R1==0)
R2=R3 ;
Съответстващият
й машинен код е следният:
CMP R1, 0
BNE Label_1
MOV R2, R3
Label_1: < . . . . . >
Всички
тези машинни операции могат да се обединят в една условна команда:
CMOVZ R2,
R3, R1
Тази
команда проверява дали съдържанието на регистър R1 е равно на нула и ако то е
равно на нула, записва съдържанието на регистър R3 в регистър R2. Ако
резултатът от проверката на условието е “лъжа”, то командата не изпълнява
никакви действия. По същество това беше логиката и на оператора if.
Ако
можем да разполагаме с команда за зареждане, която се изпълнява при условие, че
съдържанието на избран регистър с равно на нула CMOVZ, то няма причина да
нямаме подобна, която да изпълнява аналогично действие, но при инверсното
условие – CMOVN. И като имаме предвид, че възможните условия за преход
не са толкова много (вижте например таблица 5.2.2.1
или 5.2.2.2), този механизъм е лесно реализуем. Ще разгледаме още един
по-пълноценен пример с базови блокове в двата клона:
if (R1==0)
{
R2=R3 ;
R4=R5 ;
} else
{
R6=R7 ;
R8=R9 ;
}
На
тази конструкция съответства следния машинен код:
CMP R1, 0
BNE Label_1
MOV R2, R3
MOV R4, R5
BR Label_2
Label_1: MOV R6, R7
MOV R8, R9
Label_2: < . . . . . . . >
който при използване на
условните команди ще изглежда по следния начин:
CMOVZ R2,
R3, R1
CMOVZ R4,
R5, R1
CMOVN R6,
R7, R1
CMOVN R8,
R9, R1
При
предикатното изпълнение, операциите се изпълняват условно, в зависимост от
стойността на логическия параметър, наречен предикат, свързан с всяка команда в
базовия блок, който съдържа операцията. В съвременните процесори всички команди
в смисъла на третата си задача (вижте определението)
са с безусловен преход, и в смисъла на командния цикъл, те просто се
изпълняват. При такива команди никога не се поставя въпроса: “Да се изпълни
или да не се изпълни?”. В архитектури с предикатно изпълнение всяка команда
съдържа своя предикат, чиято стойност определя дали тя ще се изпълни или не.
Стойностите на предикатите се изчисляват от операциите сравнение (Ср.) и имат стойност “истина” , ако програмата достига базовите блокове при съответните преходи, и има стойност “лъжа”, ако не ги достига. Семантиката на една операция, която се контролира от предиката Р е такава, че тя се изпълнява както обикновено, ако Р=”истина”, а когато Р=”лъжа”, тогава процесорът я отменя. Един прост пример за условно преобразуване е показан на фигура 5.3.8.1.
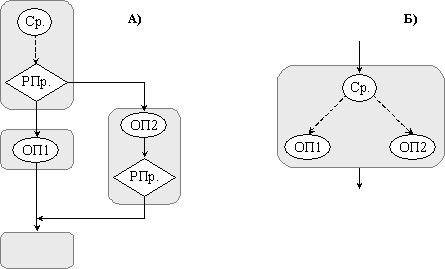
Фиг. 5.3.8.1. Използване на
предикатно изпълнение за реализация на условно преобразуване
Лявата рисунка
А) изразява блок-схемата на конструкцията if-then-else , а на дясната Б)
полученият резултат след условното преобразуване. Една операция сравнение Ср. в
EPIC изчислява допълващите се един друг предикати, всеки от които контролира
операциите в един от съответните клонове след условния преход, за който се
отнасят. Фоновите блокове в рисунка А) указват базовите блокове. Плътните
стрелки указват потока на управление, а пунктирните определят зависимостите на
данните. Условното преобразуване в рисунка Б) отстранява разклонението, като
поражда само един базов блок, който съдържа операции, контролирани от
съответните предикати.
Ето
как би изглеждал предикатният текст на машинния код за дадения последно по-горе
пример:
CMPEQ R1,
R2, P1
<P1> MOV R2, R3, P1
<P1> MOV R4, R5, P1
<P2> MOV R6, R7, P2
<P2> MOV R8, R9, P2
Обяснението е просто – командата сравнение CMPEQ сравнява съдържанието на регистрите R1 и R2, в резултат на което определя актуалното съдържание на предикатните регистри Р1 и Р2 с правата и инверсната стойности на проверяваното условие.
Преобразуваният код не съдържа преходи и лесно може да бъде планиран паралелно с останалия код, при което изявеният паралелизъм на ниво команди може да се окаже значително повече. Условното преобразование е особено ефективно, когато клоновете на програмата не се разклоняват от своя страна и когато броят на операциите не е голям.
Спекулативно
управление (Control Speculation). Командите за преход сериозно
затрудняват изменението на реда за изпълнение на операциите, което се налага за
постигане на ефективно планиране на изпълнението. Заедно с предикатното
изпълнение концепцията EPIC предполага още една възможност, позволяваща
пренасяне на операции през команди за преход – изпълнение, спекулативно по
управление. На фигура 5.3.8.2 рисунка А) съдържа фрагмент от програма, който
съдържа два базови блока.
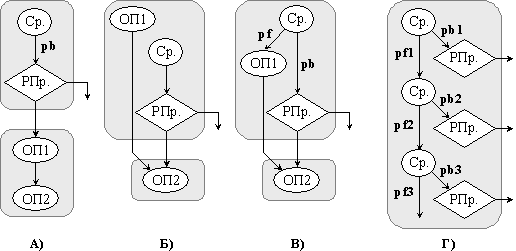
Фиг. 5.3.8.2. Пример за
преместване на код назад през един или няколко прехода
Според рисунка
А) в горната фигура, изходният код съдържа два последователни базови блока.
Операторът ОП1 се пренася нагоре в блок-схемата преди прехода с помощта или на
изпълнение Б), което е спекулативно по управление, или с помощта на изпълнение
В), с приложение на предикати. Рисунка Г) показва как използването на напълно
разрешени предикати поражда код без управляващи зависимости между преходите, а
така също между преходите и другите операции. Отсъствието на тези управляващи
зависимости поражда област с много преходи, която допуска голяма свобода при
планиране на изпълнението.
Тъй
като статичното спекулативно изпълнение позволява да се постигне по-висока
степен на паралелизъм на ниво команди, то изисква апаратна поддръжка при
обработка на изключенията (прекъсванията). Ако операцията веднага съобщава за
спекулативно изключение, последното може да се окаже лъжливо. Такава ситуация е
възможна например, ако операция ОП1* съобщи за изключение, а при това е избрано
отклонението. Изключението е лъжливо, защото е било оповестено, въпреки че
операцията ОП1 в изходната програма (рисунка А) даже не е била изпълнена.
EPIC
позволява да се избегнат лъжливите изключения за сметка на код със спекулативно
изпълнявани операции и маркирани с тегове операнди. Когато една спекулативно
изпълнявана операция (като ОП1* на рисунка Б) в горната фигура) генерира
изключение, тя не съобщава за това веднага. Вместо това операцията генерира
операнд, който се маркира с тег като грешен. За настъпило изключение при тази
операция се съобщава по-късно, когато нейният грешен резултат бъде използван от
неспекулативно изпълнявана операция. Ако разклонението бъде пропуснато,
операция ОП2 коректно ще съобщи за изключението, генерирано от ОП1*. Ако бъде
избрано отклонението в прехода, грешният операнд ще бъде игнориран и за
изключението няма да бъде съобщено.
Предикатно
преместване на кода. EPIC-процесорът не поддържа спекулативно изпълнение на
такива операции, като “преход със запис в паметта”, тъй като така могат да
бъдат предизвикани крайни ефекти, които се отстраняват много трудно. Вместо
това EPIC използва предикатно изпълнение, което допуска неспекулативно
преместване на операции през преходите. На рисунка В) от горната фигура е
показано преместване на операция ОП1 преди прехода. В този пример обаче, ОП1 си
остава неспекулативна, защото тя се контролира от предиката, който съответства
на отрицанието на условието за изход по клона ( pf=not(pb)
). Както и в изходната програма, операторът ОП1 се изпълнява само в случай, че
преходът не е избран.
EPIC
допуска неспекулативно преместване на код през няколко прехода. Компилаторът
може да свърже каскадно операциите Ср., които изчисляват предикатите през
няколко прехода, както е показано на рисунка Г) от фигурата по-горе. Всяко
сравнение оценява съществуващото условие (на рисунката не е показано) и
изчислява предикатите за съответния преход ( pbi ) и за базовия
блок, който се достига, когато преходът се пропуска ( pfi ).
Предикатът на прехода ( pbi ) има стойност “истина”, когато
предикатът на предидущия базов блок ( pfi-1 ) също има стойност
“истина” и когато условието за изход от прехода не е изпълнено. Предикатите,
които се изчисляват върху многоблочна област, се наричат напълно разрешени
(Fully Resolved Predicate - FRP).
Когато
предикатите за последващите клонове в линейна последователност се включват като
FRP-предикати, те взаимно се изключват – най-много един предикат може да бъде
истинен и така може да бъде избран само един преход. Операциите за преход и
други неспекулативни операции вече могат лесно да бъдат преподредени. Те
свободно се преместват в слотовете за задръжка (delay slots) на
предидущите клонове или през предидущите преходи. Ако преходите, в крайна
сметка, са планирани така, че да се изпълняват едновременно, взаимното
изключване гарантира коректно поведение. Когато компилаторът предлага
неспекулативни операции, използвайки FRP-предикати, той замества зависимостите
между преходите със съответни зависимости между операндите с предикати. За
оптимизация на плана за изпълнение, плановикът поддържа както спекулативно,
така и неспекулативно преместване на операциите.
Използването
на FRP-предикати позволява да бъдат заместени зависимостите между
последователностите от преходи със зависимости между последователности от
сравнения. Всяка операция сравнение се обединява с допълнителен логически
израз. Дълбочината на зависимост в логическите изрази с FRP може да бъде
съкратена за сметка на други възможности на EPIC (апаратни операции сравнение
AND и OR) за да бъде ускорено изчисляването на стойността на изразите с FRP,
съдържащи по няколко конюнктивни и дизюнктивни терма.
Г) Задачата за
адресиране на паметта
Достъпът
до клетки от паметта също може да повлияе негативно на производителността. Тъй
като продължителността на такта на процесора намалява по-бързо, в сравнение с
времето за достъп до паметта, то времето за достъп до паметта, измервано в брой
тактове на процесора, расте. Това увеличава дължината на критически важните
пътища в плановете на програмата. Кеш-паметта за данни може до известна степен
да предотврати спадането на производителността по причина на увеличената
латентност на оперативната памет. Апаратно управляваните буферни памети обаче
понякога могат да понижат производителността до такава степен, че тя да падне
под нивото, което съответства на системата без кеширане.
Концепцията
EPIC предполага реализация на архитектурни механизми, които позволяват на
компилаторите да контролират точно преместването на данните в йерархията на
буферната памет. Тези механизми следва да могат избирателно да покриват
апаратната логика, работеща по подразбиране. За яснота на изложението тук се
има предвид примерна архитектура, в която съществува кеш-памет за данни на
първо ниво (L1), както и кеш на предварително извлечените данни. На второ ниво
съществува кеш-памет с общо предназначение (L2).
Спецификатори
на кеш-паметта. За разлика от другите операции, продължителността на
зареждането може да се влияе от няколко различни задръжки, в зависимост от
нивото на кеш-паметта, в която се съдържат заявените данни. За зареждане на
NUAL (предполагаема задръжка на няколко такта) компилаторът е длъжен да
съобщи на контролерите на паметта конкретна стойност на задръжката, която
предполага за всяка операция зареждане. За целта EPIC предоставя операции
зареждане със спецификатор за кеш-източника, който компилаторът използва за да
информира контролерите за това, къде именно в йерархията на кеш-системата
най-вероятно може да се намират заявените данни и при това, косвено, съобщава
стойността на предполагаемата задръжка. За да генерира добър план за
изпълнение, компилаторът следва да извърши голям обем работа за прогнозиране на
задръжката на всяка операция зареждане (която после да предаде на апаратните
контролери чрез спецификатора на кеш-източника), така, че за всяка операция
зареждане да предскаже нивото на кеш-паметта, където най-вероятно се намират
заявените данни.
Операциите
зареждане и запис в EPIC разбиранията предоставят освен това и спецификатор за
кеш-адреса, който компилаторът използва за да покаже към кое ниво в кеш-паметта
е насочен трансфера (към по-високо или към по-ниско). Този спецификатор
намалява броя на неуспешните обръщения към L1 или L2, за сметка на управлението
на съдържанието на тези памети. Компилаторът може да извлече данни от
неефективната “временна локализация” и може да изтрие данни от съответното
ниво, където те последно са били използвани.
Буферът
на предварително извлечените данни позволява да бъдат пренасяни данни за
временна локализация към кеш-памет с малка задръжка, без да променя
съдържанието кеш-паметта на първо ниво. Тези възможности са допълнително
пояснени в глава 6 (разгледайте поясненията, свързани
с фигура 6.3.2.1.2). Програмата може предварително да извлече данните,
използвайки необвързано (несвързано) зареждане, което указва кеша за
предварително извличане за източник на адреса, т.е. като заявител.
Необвързаното зареждане не записва данни в регистрите на процесора, неговата
цел е да обслужва вътрешната йерархия на кеш-системата. Пренасянето на данни в
буфера за предварително извличане вместо в L1-кеша позволява на програмата да
зарежда предварително (изпреварващо) големи потоци данни и да ги зарежда бързо,
без премествания на съдържанието на кеш-паметите L1 или L2. Операциите за
необвързано зареждане могат освен това да използват кеш-паметите като
устройства, адресиращи данните, позволявайки по този начин да се изпълни
предварително зареждане в други кеш-нива.
Изпълнение,
спекулативно по данни (data speculation). Още едно препятствие по
пътя за създаване на добрия план за изпълнение (РОЕ) възниква по причина на
малко вероятни зависимости между указателите към паметта. Често компилаторът не
може статично да определи, че указателите сочат различни адреси в паметта и
трябва да се опира на по-безопасно предположение за това, че те сочат един и
същи адрес, даже в общият случай това да не е така. Изпълнението, спекулативно
по данни, позволява на компилатора да генерира РОЕ, който предполага, че
операциите запис и последващо зареждане, използват различни адреси в паметта,
даже ако вероятността за това да е малка.
Изпълнението,
спекулативно по данни, разделя традиционното зареждане на две операции- команда
спекулативно зареждане (СЗ) (data-speculative load) и команда зареждане
с проверка (ЗП) (data-verifying load). Компилаторът премества
командата спекулативно зареждане СЗ по-високо (преди) от командата запис, която
потенциално записва данни по същия адрес, за да може зареждането да започне
навреме, в съответствие с плана за изпълнение. Компилаторът планира следващата
команда за зареждане с проверка ЗП след командата за запис, която потенциално
записва данни по същия адрес, използвайки апаратурата за проверка на
възможността да възникне ситуация, при която операциите зареждане и запис
използват един и същи адрес. Ако подобна ситуация не възниква, това означава,
че командата спекулативно зареждане СЗ е заредила коректна стойност и командата
зареждане с проверка ЗП няма какво да прави. Така изпълнението е с максимална
ефективност. Когато командите зареждане и запис се обръщат към един и същи
адрес, командата зареждане с проверка ЗП изпълнява повторно зареждане и спира
процесора, за да гарантира своевременното получаване на коректни данни и
тяхното последващо използване в съответствие с плана за изпълнение на
програмата. Освен това концепцията EPIC поддържа по-активно спекулативно
преместване на части от кода, когато компилаторът пренася не само операции за
спекулативно зареждане, но в добавка и операции, които използват техния
резултат, преди операциите запис, които потенциално могат да използват същия
адрес в паметта.
Освен
изложените до момента аспекти, които EPIC осигурява, съществуват и други. Из
между тях например се намират разработени стратегии за осигуряване
съвместимостта на обектния код върху различни модели процесори от семейството
EPIC. Тези стратегии отчитат следните два фактора:
Първо,
операционните задръжки, предположени от компилатора при генериране на кода за
даден процесор, могат да не съвпаднат с аналогичните за друг ;
Второ,
предполагаемият и реалният паралелизми (като брой функционални устройства)
могат да се различават.
Всички
методики, използвани от суперскаларните процесори, са приложими и в EPIC
архитектурата, тя обаче позволява създаването на относително евтини програмни
решения на този проблем, предоставяйки на компилатора възможността да играе
по-важна роля в осигуряването на съвместимостта.
Д) Заключение
През
последните години сравнението на достойнствата на VLIW и суперскаларните
архитектури е основна тема в дискусиите свързани със системата машинни команди
(ILP). Привържениците на едната и другата концепции свеждат това обсъждане до
противопоставянето на простотата и ограничените възможности на VLIW
архитектурите срещу сложността и динамичните възможности на суперскаларните
структури. Това противопоставяне е изначално неправилно. Съвършено ясно е, че и
двата подхода имат своите достойнства и да се говори за тяхна алтернативност е
неуместно. Очевидно е, че създаването на плана за изпълнение по време на
компилация е съществено за осигуряване на висока степен на разпаралелване на
ниво команди, даже за суперскаларния процесор. Ясно е също, че по време на
компилация съществува нееднозначност, която може да се отстрани само по време
на изпълнение и за решаване на тази задача процесорът изисква наличието на
динамични механизми. Привържениците на EPIC са съгласни с тези две позиции.
Различието е само в това, че EPIC предоставя тези механизми на ниво архитектура
така, че компилаторът може да управлява такива динамични механизми, прилагайки
ги изборно там, където е възможно. Толкова широки функции за управление дават
на компилатора възможност да използва правилата за управление на тези механизми
по-оптимално, в сравнение с чисто апаратните възможности.
Основните
принципи на EPIC, заедно с възможностите на архитектурата, която ги поддържа,
осигуряват средствата за дефиниране на ILP-архитектурата. Така процесори,
изискващи по-висока степен на ILP при по-малка сложност на апаратурата, могат
да бъдат прилагани в най-различни области. Архитектурата IA-64 е пример за
това, как принципите на EPIC могат да се приложат към изчислителни системи с
общо предназначение, т.е. в области, където съвместимостта на обектния код има
критическо важно значение. EPIC може да играе важна роля и във високо
производителните вградени системи. Тъй като обаче в тази област изискванията
към съотношението цена / производителност са по-твърди и заедно с по-ниските
изисквания към съвместимостта на обектните модули, то тук се прилагат
по-гъвкави и настройващи се архитектури. Комерсиалната версия на такава EPIC
технология се очаква за в бъдеще.
Следващият раздел е:
5.3.9 Многоядрени процесори. Суперскаларни, Конвейерни,
VLIW, SMP, Hyper-Threading - архитектури