Последната
актуализация
на този
раздел е от 2020
година.
5.3.9
Многоядрени
процесори.
Суперскаларни,
Суперконвейерни, VLIW,
SMP, Hyper-Threading –
архитектури
Настоящата реалност се характеризира с окончателната масова подмяна на РС-системите с нови модели процесори, чиято архитектура е популярна под наименованието многоядрени. Това са компютърни системи, чиито процесори съдържат в логическата си структура повече от две процесорни ядра. Анонсирането на компютърни системи с двуядрени процесори компаниите AMD и Intel извършиха през втората половина на 2005 година. Съвременното развитие на производствените технологии е толкова динамично, че вече няма такава, която да не прилага успешно принципа на апаратното насищане, който пояснихме в началото на тази глава. Еволюцията на структурното и на логическото проектиране, както и на производствените технологии в това направление е вече неудържимо. Ще споделим само едно интересно съобщение – през август 2019 година компанията Cerebras представи най-големия многоядрен супер процесор “Cerebras Wafer Scale Ebgine”, който е разположен върху 30 сантиметров силиконов диск и съдържа 400000 (400*103) ядра. Схемата му изграждат над 1,2 трилиона транзистора (1,2*1012). Сам по себе си този факт е уникален и говори за възможностите на технологиите. Чрез тази тема тук отново и от малко по-различна гледна точка желаем да допълним всичко казано преди това за новите организационни принципи, чрез които се преследва непрекъснатото повишаване на производителността на компютърните системи. Тук ще бъдем принудени да намесим понятието архитектура, но с ясното съзнание, че компютърната архитектура като тематика излиза извън интересите на тази книга.
Всеки
читател
първоначално
ще потърси обяснения
относно
новите
понятия в
даден текст,
така и тук
интерес
представлява
понятието ядро,
(Processor Core) което
ние така или
иначе вече
бяхме принудени
да употребим
в
предходните
раздели. Принудени
сме да го
поясним, тъй
като то се превърна
в характерен
параметър на
съвременните
микропроцесори
и неизбежна
част от
обясненията,
свързани с
тях. Най-общо
се приема, че
под ядро
следва да се
разбира
определена
част от микропроцесорния
кристал,
която има
реална
апаратна
реализация,
предназначена
да изпълнява
основните
функции на
цифровата
изчислителна
машина, както
вече ние я
определихме.
Прието е ядрото
да се
именува. Така
един тип
микропроцесор
може да се
произвежда с
различен вид
ядра, като
разликата се
отнася до
самата им
логическа
структура, до
набора
обслужвани
групи от
машинни
команди, до
алгоритмите
за
комуникация
и пр.
Следващото изложение ще проследи развитието в това архитектурно направление малко по-отрано.
Конвейер
– първата и
най-практикувана
форма на
паралелизъм
За начало ще поясним разбирането за скаларен процесор. Скален е този процесор, който притежава единично операционно устройство, в което може да изпълнява една произволна (поредна) машинна команда (операция) от системата машинни команди. При структурирането на процесора въз основа на командния цикъл, започват да се обособяват отделни функционални устройства, такива като АЛУ за работа с фиксирана запетая, АЛУ за работа с плаваща запетая, устройство за обработка на данни със специални формати (видео или аудио), устройство за управление на шинния интерфейс, устройство за формиране на изпълнителните адреси, устройство извличане на команди, устройство за извличане на операнди и пр. устройства.
Ще припомним, че раздел 5.3.3 беше посветен изцяло само на конвейерната организация на обработката на машинните команди, по тази причина тук изложението под обявеното заглавие, следва да се разбира само като необходимо въведение към следващите пунктове.
Наименованието суперскаларен процесор за първи път е употребено през 1987 година. Това се наложило, тъй като технологиите вече са били в състояние да вградят върху кристалната подложка повече от едно функционално устройство от един и същи тип. В началото това били АЛУ за работа с фиксирана запетая. За ефективно използване на многото функционални устройства, по естествен път се стига до идеята за конвейерна организация на хода на изчислителния процес на ниво машинни команди. Става дума за потока от машинни команди, които по силата на първичния организационен алгоритъм (командния цикъл) се образува при непрекъснатото им извличане и подаване за изпълнение. В командния цикъл изпълнението на една команда преминава най-общо казано през следните няколко стадия:
1. Извличане на командата от паметта (ИК). Всяка машинна команда се адресира от съдържанието на програмния брояч. Този адрес се подава по адресната шина, който постъпва в йерархичната система на паметта, от която, след не особено прости алгоритми, се извлича и доставя съответното съдържание. Съдържанието на така прочетената клетка представлява заявената команда ;
2. Декодиране на извлечената команда (ДК). След попадане на командата в регистъра на командата, кодът на операцията се изпраща към управляващото устройство, където от него се формира преход към началото на онзи микропрограма, която съответства на заповяданата операция ;
3. Формиране (изчисляване) на адресите на операндите (ФА). След идентификация на микропрограмата, същата пристъпва към изчисляване на абсолютните адреси на исканите от командата операнди. За целта, използвайки адресната информация от адресната част на командата, според съответния метод за адресиране, се формира всеки от абсолютните адреси на операндите ;
4. Доставка на операндите от паметта (ДО). Всеки от така формираните абсолютни адреси постъпва в йерархичната система на паметта, от която, след не особено прости алгоритми, се извлича и доставя съответното съдържание. Съдържанието на така прочетените клетки представлява заявените операнди, които се съхраняват в съответните даннови регистри ;
5. Изпълнение на декодираната операция в съответното операционно устройство (ИО). Избраната микропрограма управлява съответното операционно устройство според алгоритъма на заповяданата операция, в резултат на което се изчислява резултатът от операцията ;
6. Запис (съхранение) на изчисления резултат (ЗР). Така както и операндите, резултатът се записва в съответния регистър на операционното устройство, според правилата, които са заложени в микропрограмата на изпълняваната команда.
Така
например, в
процесорите Pentium
са били
реализирани
две АЛУ за
работа с фиксирана
запетая и
едно АЛУ за
работа с
плаваща
запетая. В следващи
модели
клонирането
на
устройствата
се засилва.
Ще приведем
базовата
логическа
структура на
популярния Pentium.
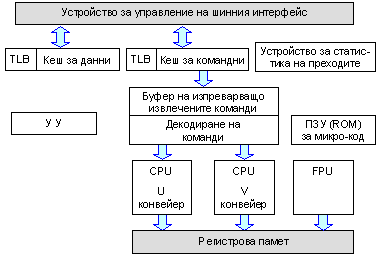
Фиг. 5.3.9.1. Обобщена
структура на
процесор Pentium
Устройството на шинния интерфейс (BIU) управлява 64 битова даннова шина както и 32 битова адресна шина. Кешовете за данни и за команди ускоряват обработката. Преобразуването на ефективния адрес (ЕА) в линеен (LA) и в последствие във физически (PA) извършват TLB-буферите (Transfer Location Block). Всеки кеш има такъв блок, който променя подаваният им адрес в такъв, с който може да се адресира в самия кеш. Този вид памет и свързаните с нея проблеми ще дискутираме в следващата глава на тази книга.
ВТВ-устройството (Branch Trace Block (Buffers)) води на отчет всеки адрес за преход на команда за условен преход дали е бил изпълнен или не е бил изпълнен. Устройството води тази статистика за последните до 256 команди. Статистиката се използва от управляващото устройство (УУ) за да спекулира с залозите за преход или не. Ако залогът (предсказанието) не е било изпълнено, се спира работата на конвейера и той се изчиства. Това се прави в устройството за допълнително декодиране. Тази логика е много полезна при условни преходи за програмни цикли.
Изпреварващото извличане на машинни команди и подреждането им за последващо изпълнение е много характерен архитектурен елемент, на който специално се спираме в следващата 6-та глава на тази книга. Буферът поема всяка нова команда и я анализира дали е команда за безусловен преход или е команда за условен преход. Ако е команда за безусловен преход, командата не се записва в буфера и изпреварващото извличане на машинни команди продължава от адреса на прехода. Ако командата е за условен преход, тя се записва в буфера (FIFO-опашка).
Декодирането на командите става, когато те се извличат от опашката и следва да се заредят за изпълнение. Тук, тъй като в структурата на този примерен процесор има 2 конвейера, командите се декодират по двойки. Има 10 правила, според които УУ решава дали и как да ги зареди в двата паралелни конвейера U и V. Конвейерът V е за прости аритметически операции. В U-конвейера се зареждат всички останали операции, включително и тези върху данни с плаваща запетая. В този смисъл U-конвейерът се определя като основен. В самото FPU се зареждат подготвените операнди и то изпълнява само фазата, наречена Execution. Така двата конвейера работят паралелно по всички степени, показани на следващата фигура.
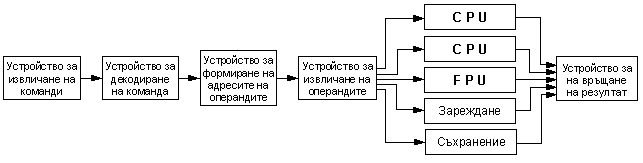
Фиг. 5.3.9.2. Степени на суперскаларeн конвейер
Показаното на фигура 5.3.9.1 постоянно запомнящо устройство ROM съдържа микропрограмите за управление на изпълнението на всяка CISC команда.
С това този процесор се характеризира като суперскаларен и конвейерен. Тъй като структурата на процесора съдържа обособени функционални (операционни) устройства, то с тяхната конвейерна организация скаларният процесор придобива най-ранната форма на паралелизъм и става по-производителен.
Общото
време, което
е необходимо
за изброените
по-горе
стадии,
формират латентността
на
съответната
машинна
команда.
Латентността
не е
константа,
тъй като
протичането
на отделните
стадии
зависи от
много и различни
фактори,
зависещи от
устройствата,
с които всеки
от тях си
взаимодейства.
Изпълнението на идеализирана последователност от машинни команди върху конвейер, който има 6 степени е показано на следващата фигура.
|
Конвейерна
обработка |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 такт |
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
|
|
|
|||||||
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
|
|
||||||
|
|
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
||||||
|
|
|
|
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Суперконвейерна обработка |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Суперскаларна
обработка |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
|
|
|
|
||||||
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
|
|
|
|||||||
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
|
|
||||||
|
|
|
ИК |
ДК |
ФА |
ДО |
ИО |
ЗР |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Суперскаларна Суперконвейерна
обработка |
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
ИК1 |
ИК2 |
ДК1 |
ДК2 |
ФА1 |
ФА2 |
ДО1 |
ДО2 |
ИО1 |
ИО2 |
ЗР1 |
ЗР2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Идеализираното изпълнение на последователност от команди е показана на първата графика. На всеки 2 такта в конвейера се зарежда нова команда. Разделяйки всеки стадий, съответно всяка степен на две, времето за изпълнение на последователността от команди се съкращава.
На третата графика е показано изпълнението в суперскаларен процесор, който може да изпълнява повече от една команда в един такт. Това се постига чрез включване в структурата на процесора на няколко паралелно работещи устройства. Вижда се ново съкращаване на времето за изпълнение на групата команди. Съвместяването на двата подхода, показано на последната графика, води до най-краткото изпълнение на групата команди.
Суперскаларност
В съвременните процесори суперскаларността се осигурява с апаратни средства, а разпаралелването и ефективното натоварване на паралелно работещите устройства с команди се осигурява с приложението на специални оптимизирани компилатори.
Добрите практики обаче са съпроводени от своите проблеми, коренящи се в нелинейните алгоритми. Машинните команди за условен преход, които съставят около 10% от кода на програмите, нарушават ритмичната работа на конвейера. Известно подобрение на това положение се постига с внедряването на алгоритмите за предсказване на преходите и използване на алтернативни клонове в кода на програмите.
Повишаването на производителността чрез повишаване на тактовите честоти водят до по-интензивния обмен на процесора с оперативната памет. За съжаление бързодействието на оперативната памет не расте пропорционално с тази на процесора. В литературата се е наложило виждането, че разрива в производителността между процесора и паметта ежегодно се удвоява. В същото време непрекъснатият “глад" за памет води до структурни изменения в паметта. Налага се разделянето й на по-малки блокове, което пък от своя страна води до затруднения при интензивната обработка на информацията около границите на отделните блокове памет. Така всяко нововъведение идва със своите проблеми. Множество от тези проблеми конструкторите се опитват да разрешат с цял комплекс от архитектурни похвати, които обобщено ще представим.
·
Спекулативно
извличане на
данни и
предсказване
на условните
преходи.
Идеята и на
двата
похвата се
състои в изпреварващото
определяне
на извличане
на необходимите
данни и
команди от
оперативната
памет, които
предстои да
бъдат
обработвани
от процесора.
Спекулативното
извличане, което
е инициирано
от самия
процесор въз
основа на
анализ на
постъпващия
поток от команди,
се определя
като апаратно
изпреварващо
извличане ;
·
Използване
на машинни
команди за
управление
на отделните
нива на
запомнящата
система.
Командите за
принудително
зареждане на
данни в кеш
паметта,
както и
буферите за
четене и
запис
позволяват
да се
оптимизира
изчислителния
процес в
конкретния
процесор.
Спекулативното
извличане,
което е инициирано
от специални
команди, се
определя като
програмно
изпреварващо
извличане ;
·
Непоследователно
изпълнение
на машинни команди. Този
подход се
основава на
алгоритмите
за откриване
на
зависимости
по данни.
Благодарение
на анализа и
определянето
на данновите
зависимости,
процесорът
може да
промени реда
за
изпълнение
на командите
в текущата
област на
програмния
код ;
·
Апаратна
реализация
на косвената
адресация. С този
подход се ускорява
изчисляването
на
абсолютните
адреси на
операндите ;
·
Виртуализация
на адресното
пространство. Специален
вид
интерпретация
на адресното
пространство,
който ще бъде
разгледан в глава
6 на тази
книга.
Абсолютният
адрес в оперативната
памет се
изчислява от
логическия
(виртуалния)
адрес, който е
указан в
машинната
команда, с
помощта на
специални
буферни
памети (TLB-таблици, Transfer Location
Block) ;
·
Използване
на блоково
(пакетно)
предаване на
данни.
Реализацията
на този
подход за
обмен се основава
на принципа
на локалното
действие,
който е в основата
на
йерархичния
строеж на
запомнящата
система. От
друга страна
той се налага
от
увеличената
ширина на
системната
шина, както и
на
съвременния
строеж на
динамичните
памети, който
беше
разгледан в глава 4 на тази
книга ;
·
Изграждане
на
йерархична
запомняща
система.
Този подход
се изразява в
многостепенно
буфериране
на връзката
процесор -
оперативна
памет.
Включва
използването
на няколко нива
от буферни
(кеш) памети,
уширяване на
свързващите
шини и
специални
алгоритми,
съответно
специална
апаратура, за
бърз обмен
между
отделните
нива на
запомнящата
система ;
·
Принудително
разделяне на
потоците от
команди и
данни.
Подходът
цели
оптимизиране
на обработката
на
разнородната
информация,
обменяща се
между
процесора и
паметта.
На следващата фигура е показана обобщена структура на процесор, реализиращ горе изброените архитектурни подходи. Виждат се няколко функционално различни подсистеми, осигуряващи конвейерната и суперскаларната обработка на потока от машинни команди.
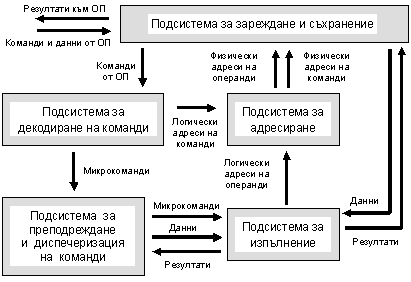
Фиг. 5.3.9.3. Обобщена суперскаларна логическа структура
Подсистемата за зареждане и съхранение на команди и на данни осигурява връзката на процесора с оперативната памет, а така също осигурява временно съхранение на командите, на данните и на резултатите, необходими на останалите подсистеми.
Подсистемата за декодиране е необходима за определяне на последователността от микрокоманди в алгоритъма на изпълнение на командата. Обикновено подсистемата съдържа микропрограмна памет, устройства за дешифриране и преобразуване, както и апаратура за преименуване на регистри.
Подсистемата за преподреждане и диспечеризация реализира функции за съхраняване на декодираните микрокоманди в очакване на постъпването на техните операнди; разпределя микрокомандите, когато те са готови, към свободните операционни устройства; съхранява резултатите от обработката на микрокомандите и се грижи за своевременното отстраняване на вече изпълнените микрокоманди. Последователността за изпълнение на микрокомандите може да се различава от последователността, съответстваща на първоначалния програмен код. В подсистемата влизат таблица с регистровите псевдоними, буфери на преподредените микрокоманди, устройства за отстраняване и възстановяване, регистри за заместване, буфери за готовите микрокоманди, както и портове за стартиране.
Подсистемата за изпълнение съдържа устройствата за обработка на операндите в съответствие с подготвените кодове на микрокомандите. Това са устройства за обработка на числа с фиксиране запетая, устройства за обработка на числа с плаваща запетая, устройства за контрол и обмен на данни с ОП, както и устройство за проверка верността на предсказаните условни преходи.
На практика развитието на изложената по-горе обобщена архитектурна база е в процес на непрекъснато усъвършенстване и конкретизация, която конструкторите на водещите компании провеждат в търсенето на различни пътища за повишаване на производителността. По-долу ще приведем като пример за суперскаларна архитектура Р6 на Intel, еволюирала в моделите Core.
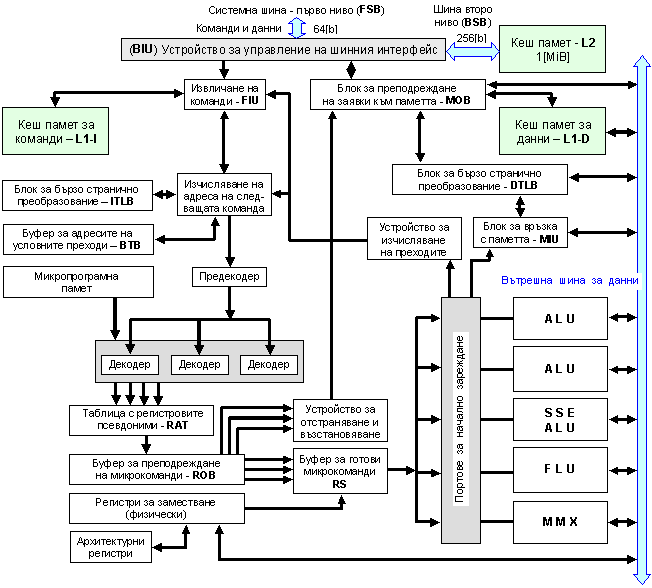
Фиг. 5.3.9.4. Суперскаларна структура на фамилия P6
В рисунката са употребени следните съкращения:
FIU - Fetch Instruction Unit ; BTB - Branch Target
Buffer ;
FSB - First Side Bus ; DTLB
- Data Transfer Location Block ;
BSB - Back Side Bus ; ITLB
- Instruction Transfer Location Block ;
BIU - Bus Interface Unit ; RAT - Register Alias Table ;
MIU - Memory Interface Unit ; ROB - Reorder Buffer ;
MOB - Memory Ordering Block ; RS - Reservation Station.
Скаларният конвейерен процесор изпълнява повече от една машинна команда, но винаги завършва само една от тях.
Суперскаларният конвейерен процесор изпълнява повече от една машинна команда и е способен да завърши две и повече команди за един такт.
Суперскаларните процесори могат да бъдат класифицирани така:
· Статичен.
Изпълнява машинните команди подред (in-order) ;
· Динамичен.
Може да изпълнява машинни команди извън програмния ред (out of order). От тази възможност са лишени командите за условен преход ;
· Спекулативен.
Може да изпълнява всякакви команди извън програмния ред (out of order). Спекулира изпълнението на команди за условен преход, както и команди за зареждане и запис.
Статичният суперскаларен процесор:
· Е сходен с класическия скаларен конвейерен процесор ;
· Всички команди изпълнява в рамките на един конвейер ;
· Има допълнително вградена апаратура за планиране и групиране на командите. Проверява се група от k на брой последователни команди за наличие на конфликти между командите в групата и командите вече заредени за изпълнение. Ако се открие конфликт вътре в групата, то за изпълнение се зареждат само командите, които предхождат първата конфликтна команда в програмния ред, а останалите команди се блокират докато се разреши конфликта. Освен това тази апаратура отговаря за разпределението на командите между отделните устройства ;
· Конвейерите за фиксирана и за плаваща запетаи са изравнени по дължина чрез въвеждане на празни степени.
Статичният суперскаларен процесор има относително проста апаратура. Има висока пикова производителност и за него са възможни високи работни честоти. За достигане на реално висока производителност обаче изисква прекомпилиране на програмния код. Типични за този вид процесори са моделите Ultra Sparc III и IV на компания SUN, а така също моделът POWER 6 на компания IBM.
Динамичният суперскаларен процесор:
· За планиране на изпълнението на командите използва алгоритъма на Томасуло, който описахме в предходните раздели ;
· Притежава усъвършенствани алгоритми за планиране на изпълнението на повече от 2 команди за един такт ;
· Командите, стоящи след команда за условен преход се планират, но не се изпълняват, докато не се изпълни условния преход.
Динамичният суперскаларен процесор реализира паралелизма на командите само в един базов блок.
Спекулативен суперскаларен процесор (ССП):
· Спекулацията се изразява в изпълнението на някои операции, необходимостта от което има вероятностен характер ;
· Е способен да изпълни команди, които са в клона “лъжа" на командата за условен преход, основавайки се на данни от предсказването. Ако последното се окаже невярно, се изпълнява връщане.
Етапи при изпълнение на машинните команди
|
Алгоритъма
на Томасуло |
ССП |
|
1. Извличане на команда |
1. Извличане на команда |
|
2. Планиране на командата |
2. Планиране на командата |
|
3. Очакване готовността на операндите |
3. Очакване готовността на операндите |
|
4. Изпълнение на операцията |
4. Изпълнение на операцията |
|
5. Съхранение на резултата |
5. Запис на резултата |
|
|
6. Завършване (Commit) |
Процесор
с дълга
команда (VLIW)
Ефективността на суперскаларната схема обаче беше изчерпана. Основният й недостатък се състоеше в това, че разпаралелването на командите ставаше предимно с усилията на самия процесор. Планировчикът на командите определя кои команди към кое функционално устройство ще бъдат насочени и в кой момент ще бъдат заредени за изпълнение. Ние показахме вече, че задачата за анализ на командния поток е достатъчно сложна, изисква значителни допълнителни апаратни разходи и в резултат устройството за планиране се получава изключително сложно. По тези причини задачата за оптимално планиране не винаги може да бъде решена ефективно. По тази причина се прилага организацията VLIW, която ние пояснихме в раздел 5.3.5. Постъпилите в процесора машинни команди се групират и се организират в няколко независими един от друг потока, при което могат да бъдат изпълнявани паралелно и без провеждане на специален анализ. Предварителният анализ и разпаралелване се възлага на компилатора и не участва при изпълнението на програмата. VLIW-архитектурата е подобна на суперскаларната архитектура, с изключение на това, че вместо да се използва хардуер за планиране на командите към наличните функционални устройства за изпълнение същото се извършва от компилатора по време на компилиране. Ако всяка машинна команда е 32 битова, а процесорът има 4 ядра за изпълнение, тогава общата дължина на дългата команда е 128 бита! Процесор с VLIW-архитектура, имащ няколко ядра, ще издава нефиксиран брой команди на цикъл и всяка от тях ще се изпълнява едновременно.
Процесорите с такава организация имат VLIW-архитектура, схематично показана на следващата фигура, където дългите команди обединяват по 3 машинни команди, всяка от които попада за изпълнение в своя конвейер.
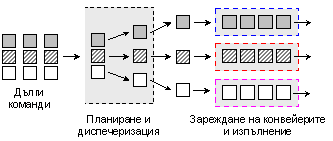
Фиг. 5.3.9.5. Опростена структура на VLIW-архитектура
Именно тази архитектура е реализирана в процесорите Intel Itanium. Още по време на компилиране процесорните команди се анализират относно възможността за паралелно изпълнение, след което се опаковат според съответните правила в така наречените дълги команди. Процесорът не губи време за анализ и за преподреждане, тъй като предварително разполага с цялата необходима информация за паралелната обработка. За съжаление VLIW процесорите изискват специални команди, някои от които не се съдържат в командната система х86. За платформите на персоналните компютри, задачата за прекомпилация на цялото програмно осигуряване, е просто невъзможна. Тези процесори компанията Intel прилагаше най-вече в сървъри.
Споменатият процесор Itanium ще поясним по-подробно. Това е VLIW-процесор с архитектура IA-64 и се характеризира със следните особености:
·
Мащабируемост
на
архитектурата. Изразява
се в
изменение на
броя на
функционалните
операционни
устройства
(главно АЛУ) с
развитието
на
производствените
технологии
без да се
налага
преработка
на софтуера ;
·
Явно
описание на
паралелизма в машинния
код (EPIC - Explicitly Parallel Instruction Computing).
Откриването
на
междукомандните
зависимости
е възложено
на
компилатора ;
·
Предикация
(Pridication).
Командите в
различните
клонове на
условните
преходи се
допълват с
предикатни
полета и се
запускат
паралелно ;
·
Изпреварващо
извличане на
команди
според
предсказване
на преходите (Speculative Loading).
Данните от
бавната
основна
памет се
зареждат
изпреварващо
с предположение
за бъдещата
им
необходимост.
Логическата структура на процесора съдържа голям набор от регистри с общо и със специално предназначение (РОП и РСП). РОП са 128 на брой и имат дължина от 64[b] + 1[b]. Допълнителният бит NaT (Not a Thing) показва дали съдържанието на регистъра е достоверно (актуално). Само командите изпълнени по предположение имат право да установяват бит NaT. Обобщена логическа структура на процесора има вида, показан на следващата фигура.
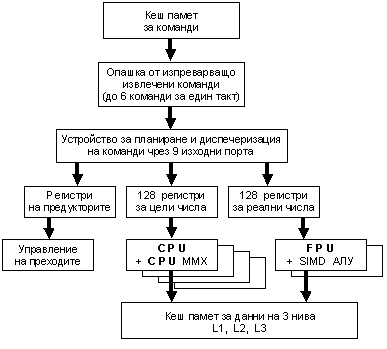
Фиг. 5.3.9.6. Обобщена логическа структура на процесор Itanium
Конвейерът на изчислителното ядро има 10 степени и включва следните блокове:
· Блокът за изпреварващо извличане осигурява в опашката до 6 машинни команди за такт. При това той извършва предварителния анализ на командите за необходимостта да бъдат заредени в опашката. Блокът има 3 степени ;
· Блокът за планиране осигурява диспечеризацията на до 6 команди за 9 изходни порта, управлява преименоването на регистрите, управлява регистровия стек. Блокът има 2 степени ;
· Блок за доставка на операнди. Осигурява връзка на регистрите с паметта и с АЛУ. Наблюдава и управлява състоянието на регистрите, предсказва зависимостите. Блокът има 2 степени ;
· Блок на изпълнението. Управлява работата на няколко комплекта еднотактни АЛУ, както и устройства за достъп до паметта. Един комплект съдържа АЛУ за цели числа, АЛУ за работа с реални числа, АЛУ за ММХ команди за целочислени числа и SIMD АЛУ за реални изчисления. Комплектите могат да бъдат до 4 броя. Блокът осигурява още изпреварващото извличане на данни, обработката на предикатите, изпълнението на условните преходи. Блокът има 3 степени.
Апаратурата за изпълнение на операции с плаваща запетая съдържа 82 битово АЛУ. Съдържа още два конвейерни блока за умножение с натрупване FMAC с повишена точност, които изпълняват до 4 операции с плаваща запетая за такт. За целите на 3D графиката са изградени още два FMAC с единична точност, които могат да изпълнят до 8 операции за такт. Има кеш памет на ниво L3 с обем 4[MiB]. Структурата има 128 регистъра с общо предназначение с дължина 82 бита. Обменът между ниво L2 и ниво L3 е на по 2 операнда с двойна точност за такт, а между ниво L2 и регистрите – 4 операнда за такт.
В архитектурата IA-64 компилаторите създават в асемблерски програми групи от команди, които са предвидени за паралелно изпълнение. Така явният паралелизъм представлява ключова характеристика на тази архитектура. Всяка така формирана група от команди в асемблерския код се разделя с признак stop (s-разряд). Командите се групират от компилатора в групи с дължина 128 бита. Групата съдържа 3 команди и шаблон, в който са посочени зависимостите между командите (възможно ли е да се стартира команда К1 паралелно с команда К2, или команда трябва да се изпълни след команда К1), както и зависимостите между другите връзки.
Архитектура SMP
Вграждането на две и повече изчислителни ядра в рамките на един процесор представлява нов значителен етап в развитието на програмно-апаратната архитектура на компютърните системи. И отново ще започнем с пояснения на понятията. Стремежът към по-висока производителност води проектантите към следващото ниво на паралелизъм – от няколко еднакви функционални устройства, каквото беше положението при суперскаларната архитектура, към няколко еднакви микропроцесора (можем да разбираме и процесорни ядра). Тази група микропроцесори е свързана с обща оперативна памет и с общ набор от входно-изходи устройства. Тъй като членовете в групата на процесорите могат да изпълняват еднакви функции, тази архитектура е наименована симетрична (Symmetric Multiprocessing - SMP). Отделните структурни елементи на такива системи са свързани с една обща системна шина, както е илюстрирано на следващата фигура.
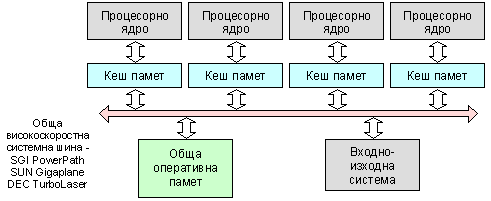
Фиг. 5.3.9.7. Обобщена логическа структура на SMP-архитектура
Този вид свързаност на елементите в структурата не е единствен. Практикува се още комутируема свързаност (crossbar switching). Проблемите на свързаността (разпределена шина; обща шина; дървовидна шина; шина тип пръстен; шина тип звезда; напълно свързана шина и пр.) ще бъдат разгледани отделно в следващата глава на тази книга. Отива се дори до йерархична комуникационна организация, която ние тук няма да разглеждаме. Архитектурата SMP позволява на всеки от процесорите да работи върху отделно и самостоятелно задание, независимо къде в паметта се съдържат неговите данни (UMA-архитектура – Uniform Memory Access, еднороден достъп до паметта). Операционната система на тези системи има за задача да зарежда задания, да ги премества като при това се стреми ефективно да натоварва отделните процесори. Основното достойнство на SMP-архитектурата е простота и универсалност в програмирането, което при тях се основава на парадигмата shared memory. Като недостатък се изявява най-вече лошата мащабируемост, което означава че при голям брой процесори системата губи ефективност. Това от своя страна по-късно води към така наречената NUMA-архитектура (Non-Uniform Memory Access, нееднороден достъп до паметта).
В началото на този етап принципът за симетрична многопроцесорна обработка (SMP, Symmetrical Multi Processors) е прилаган само в мощни работни станции и сървъри. Практически, това е един скок от суперскаларност към SMP-архитектура, заобикаляйки VLIW-архитектурата. Паралелното изпълнение на програмния код е един от най-ефективните начини за увеличаване на производителността на компютърната система. В един или друг вид паралелизмът, за който продължаваме да говорим, се прилага във всички класове компютърни системи. В частност, всички съвременни процесори реализират принципа за суперскаларна обработка. Ще припомним, че същността на този принцип се състои в това, че процесорът анализира самостоятелно потока от команди, търсейки в него възможности за пренареждане и разпаралелване. Командите, които не са свързани помежду си, могат да се изпълняват едновременно, за което в процесора има няколко конвейера.
Наличието на повече от един процесор в системата определя такива системи като MIMD-системи (много команди - много данни). В MIMD-системите всеки процесорен елемент изпълнява присвоената му програма достатъчно независимо от другите процесорни елементи. На последните обаче им се налага да си взаимодействат. Принципите на това взаимодействие условно делят MIMD-системите на:
· Системи със споделена памет. Тези системи се определят като силно свързани (tightly coupled), тъй като те използват единно адресно пространство и осъществяват достъп с оперативната памет чрез обща системна шина или чрез комутируема шина. Всеки процесорен елемент има достъп до цялото адресно пространство. Такива системи се наричат още многопроцесорни ;
· Системи с разпределена памет. Тези системи се определят като слабо свързани (loosely coupled). Адресното пространство на паметта е разделено и “присвоено” на отделните процесорни елементи. Така всеки един от тях извършва обмен само със своята област в паметта.
MIMD-системите със споделена памет е прието да се класифицират в три групи – симетрични многопроцесорни системи (SMP), паралелни векторни системи (PVP) и системи с нееднороден достъп до паметта (NUMA). Тези три разновидности на MIMD-системите кратко ще представим по-долу.
1. Симетрични
многопроцесорни
системи
Както беше посочено по-горе, всеки отделен процесорен елемент в SMP-системата има равноправен достъп до логически единната оперативна памет, т.е. използва единното адресно пространство. По този начин в системата е реализиран принципа на еднородния достъп до паметта (UMA). Процесорните елементи обикновено са еднакви, но се допуска да има и различни. Това е напълно съответстващо на наименованието “симетрични”.
Всички процесорни елементи в SMP-структурата се управляват от единствен екземпляр на операционната система (ОС), заредена в съвместно използваната памет. ОС планира разпределението на изпълняваните задания между процесорните елементи. За целта ОС отделя в процесите фрагменти (нишки) като формира от тях обща опашка. След освобождаване на даден процесор той се зарежда с поредния фрагмент от опашката. ОС са проектирани да организират работата на 16 или 32 процесора, но съществуват и ОС, които могат да поддържат до 64 процесора. При зареждане на системата един от процесорните елементи получава правата на водещ (master, този с най-голям номер), след което всички те са равноправни. На следващата фигура са показан два типични вида организация на SMP-системи.
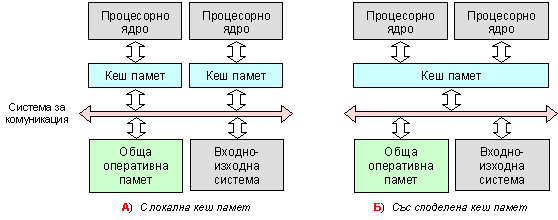
Фиг. 5.3.9.8. Два вида организация на SMP-системи
Процесорните елементи в тези системи обикновено са или CISC-процесори, или RISC-процесори. Съгласуваността на съдържанието на кеш паметите се осигурява с апаратни средства. Системите със споделена кеш памет трудно осигуряват кохерентност при повече от 4 процесора, стават по-бавни и по-скъпи.
Съществен аспект на SMP-архитектурата е начинът на взаимодействие на процесорите с общите ресурси – основна памет и В/И система. В този план архитектурата може да се изяви в следните няколко вида:
· Система с обща системна шина. Физическият интерфейс, логиката на адресиране, арбитраж, разделяне на времето на системната шина остават такива, каквито са в еднопроцесорните системи. Общата шина позволява лесно мащабиране на системата и тъй като е пасивен елемент, от една повреда в подключено устройство системата няма да пострада. Като недостатък на тези системи се изявява не високата производителност, причина за което времевия цикъл на системната шина ;
· Система с комутатор (кросбар). Тази организация е ориентирана към блокова организация на паметта, с което се цели да се повиши пропускателната способност на шината. Комутаторът предоставя много различни пътища, което от своя страна пък позволява да бъде увеличен броя на процесорите. Идеалният случай е, когато различните процесори се обръщат към различни банки на паметта ;
· Система с многопортова памет. В тези системи за сметка по-сложния многопортов достъп се осигурява непосредствен достъп до банките в основната памет. Многопортовото ЗУ дава възможност да се присвояват отделни банки на определен процесор, при което се постига по-добра защита на данните от несанкционирани опити за достъп от други процесори ;
· Система с централизирано устройство за управление. ЦУУ изпълнява следните функции: трасира данновите потоци между процесорите, паметта и В/И устройства; буферизира заявките за достъп; синхронизира и арбитрира; следи за състоянието на процесорите и кеш паметите. В резултат ЦУУ става достатъчно сложно, което може да повлияе на производителността. Може да приемем, че този вид архитектура вече е изживяла своята актуалност.
2. Паралелни
векторни
системи
Този вид MIMD-системи е с еднороден споделен достъп до паметта. PVP-системите (Parallel Vector Processor) се изграждат с не голям брой (8 – 16) векторно-конвейерни процесорни елементи. За връзка с общите ресурси най-често се изгражда комутируема кросбар система. Векторните системи използват езикови компилатори, които притежават ефективни средства за автоматична векторизация и разпаралелване на програмния код. Работата на PVP-системите се осигурява от специализирана операционна система. Процесорните елементи съдържат както векторно, така и скаларно операционно устройство.
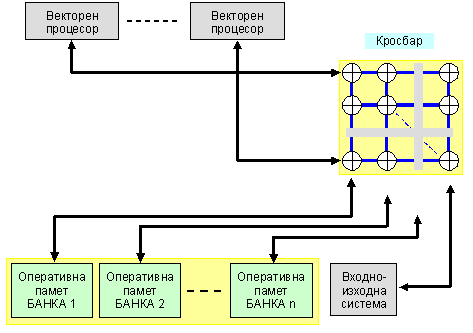
Фиг. 5.3.9.9. Обща логическа структура на PVP-системи
3. Системи
с
нееднороден
достъп до
паметта (системи
NUMA)
Тази архитектура се приема за обещаваща, когато се изграждат крупномащабни изчислителни среди. Основната памет е физически разпределена, но логически е общодостъпна. Така се запазват преимуществата, които предлага архитектурата с единно (линейно) адресно пространство и се увеличават възможностите за мащабиране на системата.
За NUMN-системите, както и за SMP-системите, е характерна несъгласуваност на данните на ниво кеш памет. За решаването на този проблем е разработена специална модификация, означена ccNUMA (cache coherent NUMA). Функционирането й се осигурява от множество протоколи, съгласуващи съдържанието на всички кеш памети. В структурата на една NUMA-система има множество изчислителни възли, които са обединени от някакъв вид комуникационна мрежа (кросбар, обща шина (кръг) или др.). Всеки изчислителен възел включва 1 или 2 процесора, кеш памет, модул локална памет (като част от глобалната основна памет), контролер на паметта, В/И интерфейс, които са свързани с локална комуникационна шина.
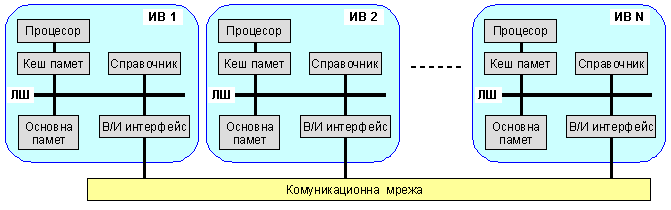
Фиг. 5.3.9.10. Обща логическа структура на ccNUMA-системи
Съгласно технологията на нееднородния достъп всеки възел в структурата съдържа локална памет, но от гледна точка цялостната система адресното пространство е глобално, в което всяка клетка в основната памет на отделните възли, има уникален системен адрес. Когато даден процесор заяви достъп към паметта и исканата клетка не се съдържа в собствената му кеш памет, се организира операция извличане. Ако заявената клетка се намира в локалната основна памет, то обменът се извършва чрез локалната шина. Ако търсената клетка се намира в отдалечен сектор на глобалната памет (локалната основна памет на друг изчислителен възел), то автоматически се формира заявка, която се изпраща чрез комуникационната мрежа до локалната шина на възела, където се съдържа исканата клетка, докато достигне обратно кеш паметта на възела заявител на адреса.
Както
във всяка
изчислителна
система със
споделена
памет, така и
в този вид
системи
особено внимание
се отделя на кохерентността
(съгласуваност
по време
протичането
на два или
повече
случайни
процеса, като
в случая
става въпрос
за
достоверността
на данните,
които са в
непрекъсната
обработка) на
данните в кеш
паметта. Най
често
поддръжката
на
кохерентността
на кеш
паметите се осигурява
с апаратни
средства. Тъй
като взаимодействието
между
изчислителните
възли се
реализира от
сложна по
топология комуникационна
мрежа,
кохерентността
се постига
чрез
специални
протоколи и
разпределените
във възлите
справочници.
Взаимното
взаимодействие
на
справочниците
позволява да
бъде
определено
физическото
разположение
на всяка
информационна
единица в
глобалното
адресно
пространство.
Логиката
на функциониране
на
ccNUMA-системите
ще поясним с
помощта на
следващия
пример. Нека
приемем, че процесорът
във възел 2
заявява
върху локалната
си шина адрес
789, който е
разположен в
паметта на
възел 1. След
това ще
наблюдаваме
следните
действия:
1. Процесорът П2 от възел 2 заявява на локалната шина достъп до адрес 789.
2. Справочникът на този възел наблюдава подадения адрес и разпознава, че той не се намира в адресното пространство на възел 2, а така също, че той се намира във възел 1.
3. Справочникът на възел 2 изпраща заявка за достъп към справочника на възел 1.
4. Справочникът на възел 1, действайки като заместител на процесор П2, заявява от свое име клетката с адрес 789.
5. Кеш паметта на възел 1 реагира на заявката като извежда исканите данни на локалната шина. Ако копието на клетката не се съдържа в кеш паметта на възела, то се инициира обмен с основната памет на възела 1.
6. Справочникът на възел 1 прихваща данните от локалната шина.
7. Прочетеното съдържание на клетка 789 се прехвърля с помощта на комуникационната мрежа обратно в справочника на възел 2.
8. Справочникът на възел 2 подава доставените данни на локалната шина на възел 2, действайки при това в качеството си на онази памет, която е съдържала данните.
9. Данните постъпват в кеш паметта на възел 2, откъдето се подават към процесор 2.
NUMA-системите работят под управлението на една операционна система. Изчислителните възли в тези системи обикновено представляват не единични процесори, а SMP-системи.
Технология Hyper-Threading
Първата крачка към SMP архитектурата беше технологията Hyper Threading. Положението с приложния софтуер се оказва такова, че програмите в болшинството случаи работят “линейно”, и даже теоретично не са в състояние да се ускорят в условията на многопроцесорна система. Ето защо от компанията Intel беше предложна технологията Hyper Threading. Симетричната многопоточна обработка (SMT, Symmetrical Multi Threading) представлява междинно решение на проблема за многопроцесорност в персоналните системи. Идеята за превключване на процесора върху различни командни потоци не е нова – тя отдавана се експлоатира в операционните системи. “Вътрешно” SMT-процесорът (ядрото) работи практически така, както и суперскаларният: свободните функционални блокове, за които на дадения етап не се е намерила работа, се зареждат с команди, които са предназначени за втория логически процесор. Така се постига по-ефективно натоварване на процесора, като се намаляват интервалите на неговия престой. В същото време “отвън”, за операционната система и за приложенията, се създава пълната илюзия за двупроцесорно изпълнение – използват се два процесора и всеки от тях е способен да обработва свой поток от данни, което е изразено на следващата фигура:
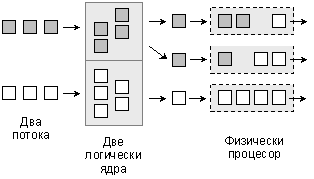
Фиг. 5.3.9.11. Архитектура SMT (HyperThreading)
Технологията
HyperThreading беше
внедрена
през 2002 година
с ясното
разбиране, че
тя
удовлетворява
желанието за
висока
производителност
частично. В
същност тя
позволява
оптимално
натоварване
на суперскаларния
процесор,
допълвайки
неговите
механизми с
механизъм за
формиране на
различни
командни
потоци.
Процесор с
тази
технология
съхранява
състоянието
на два
командни
потока, за
което
съдържа по
един набор от
регистри и по
един
контролер на
прекъсвания
за всеки
логически
процесор. Останалите
елементи на
физическия
процесор са
общ ресурс за
всички
логически
процесори. Така
или иначе
двата
логически
процесора не са
реално
независими:
те
последователно
използват
общи ресурси,
могат
взаимно да се
блокират по
причина на
конфликти
при достъп,
поради което
работят
неравномерно.
Въпреки това
именно тази
технология
беше първият опит
за
внедряване
на
многопроцесорната
обработка в
персоналните
системи.
Производителите
на
потребителски
софтуер и потребителите
приемаха
добре тази
технология.
Следващата
стъпка беше
неизбежна –
появата на
реални
многоядрени
процесори - Intel
Pentium Extreme Edition, Pentium D и AMD Athlon 64
X2.
В
процесорите
от серията Core-2
(Core-2 Duo, Core-2 Quad)
технологията
не се
прилага.
По-късно
обаче в
процесорите Core
i3, Core i5 и Core i7 (както
и в други
модели), подобна
технология
присъства. В
такива системи
за
операционната
система
всяко ядро се
определя
като два
логически
процесора.
Изпълнението
на даден
поток от
команди, подавани
към
определен
логически
процесор, може
да бъде
спряно по
следните
причини:
1.
Неуспешно
обръщение
към кеш
паметта ;
2.
Неправилно
предсказване
на условен
преход ;
3.
Не
е завършило
изпълнението
на предидущата
команда.
При
такова
събитие
физическият
процесор ще
бъде насочен
към потока
команди,
който обслужва
на втория
логически
процесор. Например,
ако дадена
команда се
забави тъй
като очаква
данни от
паметта,
физическият
процесор ще
бъде
присвоен от
втория
логически
процесор.
На
читателя
предоставяме
още една
възможност
да обогати
познанието
си, като се
запознае със
статията:
в която са
разгледани
различни
логически структури
много-нишкови
техники за
организация
на
процесорите,
както и с
резултати от
научните
изследвания
и сравнения
на
много-нишковите
процесори с много-процесорните
такива.
Първо
поколение
процесори – Pentium D,
Pentium EE
С
пускането в
производство
на
двуядрените
процесори
компанията Intel
прекъсна
номерацията
в
наименованията
на моделите.
Процесорите
остават с
наименованието
Pentium, а в
допълнение
се
обозначава
сферата за приложение
или
съответния
модел.
Универсалният
процесор
беше наречен Pentium
D (D, desktop), a Pentium EE беше
предназначен
за високо
производителни
системи. Тези
двуядрени
процесори се
произвеждат
от 2005 до 2008
година. На
следващата фотография
е показана
топологията
на кристала.

Фиг. 5.3.9.12. Процесорно
ядро Smithfield
И
двата
процесора са
построени по
една и съща
архитектура -
х86-64,
което
означава 64
битови
регистри и 64
бита на
външната
шина..
Двете
процесорни
ядра имат
вградена кеш
памет L2 с обем
1[MB] и са съединени
чрез
системната
шина. Тези
процесори могат
да изграждат
системи само
с чипсети от
модел Intel-945
нагоре. В
процесор Pentium EE
се прилага
технологията
HyperThreading, което
означава, че
за командния
поток машината
ще се
възприема
като
съставена от
4 отделни
логически
процесора.
Имайки
предвид
завишената
консумация
на енергия от
този тип
кристали (130[W]),
новите системи
изискват
нови
съединения,
ново охлаждане,
ново
захранване с
мощност не
по-малка от 400[W].
Производителност
Това
е изначалния
въпрос. Всяко
ядро има производителността
на отделен
процесор от типа
на Pentium 4, но
производителността
на
двуядрения
процесор
зависи и от
ефективното
им натоварване.
Съществуват
обективни
препятствия
за 100%
зареждане,
при това
както
програмни
така и
апаратни.
Например,
процесорната
шина и каналът
за връзка с
оперативната
памет се
натоварват
двойно и като следствие
от това се
превръща в
тясно място.
Това налага
увеличаване
на тактовата
честота на
паметта и
FSB-шината.
Второто
препятствие възниква
по причина на
това, че
зареждането
на двата
процесора е
възможно
само в два случая:
1.
Приложението
специално
разделя
сложните
изчисления
на четен брой
потоци ;
2.
Едновременно
се
изпълняват
няколко приложения.
Когато
системата
изпълнява
еднопотокови
приложения,
към които се
отнасят да
кажем съвременните
компютърни
игри, вторият
логически процесор
ще играе
помощна роля,
което няма да
даде желания
ефект.
Типичният
модел за използване
на
персоналния
компютър не
предполага
активно
използване
на
архитектура
SMP –
потребителят
не е в
състояние
едновременно
да извършва
текстообработка
да гледа видео
и да слуша
музика, да си
чете пощата и
т.н. Ето защо
тук се
предлага
технологията
за виртуализация
на
компютърната
система, така
щото тя да
бъде
мултиплицирана
за няколко
потребителя.
Предложени
бяха
например Microsoft Virtual PC и VМware.
Така
виртуализацията
на
физическата
машина
реализира ползата
от
многоядрения
процесор и
многопроцесорната
обработка.
Появата на
няколко ядра
в
структурата
на процесора
поражда
много нови и
изключително
съществени
проблеми,
свързани с
управлението
на този хардуер,
така щото в
максимална
степен да
бъде
оползотворена
възможността
за по-висока
производителност,
която се
предполага
от наличието
на
операционната
логика. Тези
проблеми се
решават
както с
апаратни,
така и с
програмни
средства и
ние няма да
ги
дискутираме
тук.
Ще
напомним, че
всичко
разказано в
последните
раздели е
правено и ще
бъде
развивано и за
в бъдеще с
една
единствена
цел –
повишаване
на
производителността
на
изчислителните
системи. Тъй
технологиите,
както видяхме
са различни,
сравнението
между тях е
неизбежно,
ето защо ни
се налага да
поясним
кратко този
проблем и
неговото
място като че
ли е тук.
Ще
въведем
някои
параметри,
необходими
по хода на
следващото
изложение.
Следва да предупредим
читателя, че
критериите
за оценка са
много.
Тяхното
изясняване
тук няма да
бъде
възможно, тъй
като това
излиза далеч
извън
интересите
на тази
книга. Ще се спрем
само на един
критерий - ускорение
на
изпълнението
на една
задача върху
някакъв
паралелен
процесор в
сравнение с
изпълнението
върху един
процесор.
·
С буква n ще
бъде
означаван
броят на
процесорите
в общия случай,
участващи в
паралелните
изчисления ;
·
T(n) ще
означава
общото време
за
изпълнение
на задачата с
използване
на n
процесора. T(1)
ще означава
времето за
изпълнение
на задачата с
използване
на един (1) процесор.
Тъй като се
предполага,
че
изпълнението
на задачата с
помощта на
един
процесор, т.е.
последователно
без
използване
на паралелизми,
е винаги
по-голямо, то
обикновено
се приема за
вярно
отношението
T(1) > T(n) (5.3.9.1) ;
·
Ускорение (Speedup)
на
изпълнението
на една
задача при
използване
на паралелна
изчислителна
система по
сравнение с
изпълнението
й върху един
процесор.
Ускорението
ще
означаваме
така S(n)
и то ще бъде
определено
чрез
отношението
![]()
·
Относителната
част на
изпълняваните
последователно
от един
процесор
операции ще
означаваме с
буква f, т.е. 0
≤ f ≤ 1. Следва, че
онази част от
програмата,
която е
подложена на
разпаралелване
ще бъде
(1-f) ;
Ще
представим
съвсем
лаконично
най-известните
теоретични
резултати,
целящи да
дадат
някаква оценка
на
ускорението,
както то беше
определено
по-горе
1. Закон
на Джин Амдал
(Gene Amdal)
Джин
Амдал (от
компания IBM)
през 1967 година
публикувал
статия, в
която за
първи път се
предлага
формула за
оценка на
ускорението.
Изведената в
статията
формула има
следния вид:
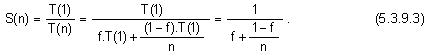
При
увеличаване
на броя на
процесорите
горният
израз клони
към следната
стойност:
![]()
Полученият
резултат
означава
следното: ако
приемем, че в
изпълняваната
програма има
една четвърт
последователни
операции, т.е. 25%
от всичките,
а останалите
могат по
някакъв
начин да се
изпълняват
паралелно, то
с никакво
увеличаване
на броя на процесорите
в
изчислителната
система няма
да бъде
възможно да
се постигне
по-високо от
4-кратно
ускорение на
изпълнението
на програмата.
С други думи,
пределната
стойност на
теоретичната
оценката е S=4.
Полученият
резултат
показва, че
грубата сила,
т.е.
неразумното
увеличаване
на процесорите
в
изчислителната
система, няма
да доведе до
пропорционално
ускоряване
на
изпълняваните
задачи. Нещо
повече, като
се има
предвид
ръстът на
апаратните
разходи при
този подход,
следва да се
очаква
обратен
ефект.
2. Закон
на Густафсон
Известен
оптимизъм
спрямо
оценката на
ускорението
според Амдал,
внасят изследванията
на Джон
Густафсон.
Густафсон
изследвал
решението на
големи
изчислителни
задачи в
изчислителна
система с 1024
процесора.
Според
негови
оценки,
частта на последователния
код в
програмите
се намиралa в
границите от
0,4% до 0,8%. При това
съотношение,
според
формулата на
Амдал, не
можело да се
очаква
ускорение
повече от
около 200 пъти. Ускорението,
което обаче
реално
получавал,
било от
порядъка на 1020.
Анализирайки
получаваните
резултати,
Густафсон
стигнал до извода,
че причината
за отличието
се крие в
изходното
предположение,
лежащо в основата
на закона на
Амдал, че
увеличението
на броя на
процесорите
не се
съпътства от
увеличаване
на обема на
решаваната
задача. В
същност
поведението
на
ползвателите
не съответства
на тази
хипотеза.
В
действителност,
получавайки
на
разположение
по-мощна система,
ползвателят
не се стреми
да съкрати
времето за
изчисляване,
то
обикновено
остава
постоянно. В
същото време
потребителят
желае да
увеличава
обема на
решаваната задача,
пропорционално
с
увеличаването
на мощността
на
изчислителната
система.
Например, при
решаване на
диференциално
уравнение в
частни
производни,
ако частта на
последователния
код за
изчисления в
1000 възлови точки
е 10% (f=0,1), то при 100 000
точки частта
на
последователния
код се
снижава до 0,1%.
По този
начин
повишена
стойност на
оценката на
ускорението
се обяснява с
намаляването
на
относителния
дял на
последователната
част в кода
на
програмата. В
резултат Густафсон
предложил да
се използва
една формула,
дадена от Ед
Барсис (Ed Barsis):
![]()
Формулата
е известна
като закон за
мащабируемото
ускорение,
или като
закон на
Густафсон.
Изразът
констатира,
че
ускорението
представлява
линейна
функция от
броя на процесорите,
при условие,
че работното
натоварване
на системата
се поддържа
такова, че
времето за
изпълнение
на задачата
да бъде
постоянно.
При това
закона на Густафсон
не
противоречи
на закона на
Амдал.
3. Закон
на Сан-Най
Третото
определение,
което ще
разгледаме, е
дадено от
Ксиан-Хе Сан (Xian-He
Sun) и Лайонел
Най (Lionel M. Ni) и се
нарича закон
за
ускорението,
ограничено
от паметта.
В
многопроцесорните
изчислителни
системи
всеки
процесор има
независима
локална памет
с неголям
обем. Общата
памет на
изчислителната
система се
образува при
обединяване
на тези
локални
памети. Когато
се решава
една задача,
същата се
декомпозира
на подзадачи,
които се
разпределят
върху
отделните
процесори.
Така кодът на
подзадачата
попада в
локалната
памет на съответния
процесор.
Както и в
предходния
случай, с
увеличаване
броя на
процесорите,
нараства и
размерът на
решаваната
задача, но до
предела на
обема на
достъпната
локална
памет.
Нека с М е
означен
обемът на
локалната
памет на процесора.
Тогава при n на
брой
процесора,
сумарната
памет на изчислителната
система ще
бъде равна на
n.M.
Предполага
се, че
рапзралелването
на задачата е
такова, че
отделните
нейни части
заемат
всичките процесорни
възли, т.е.
задачата е
мащабирана G(n)
пъти. Току що
въведеното
означение
изразява
нарастването
на работното
натоварване,
като функция
от броя на
процесорите,
което
означава
като
следствие, че
нараства и обема
на паметта n
пъти. Така
ускорението
се описва с
израза:
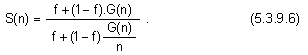
Така
предложената
формула
представлява
едно
обобщение на
законите на
Амдал и Густафсон.
В случай,
когато
G(n)=1,
размерът на
задачата е
фиксиран,
което
съответства
на закона на
Амдал, който
се извежда
след преобразуване:
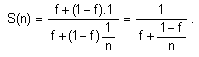
Случаят,
когато
G(n)=n,
съответства
на
нарастването
на работното
натоварване n
пъти, при n
кратно
увеличаване
на обема на
локалната памет.
Това пък е
идентично с
постановката
на Густафсон:
![]()
Ако
работното
натоварване
расте
по-бързо, отколкото
изискванията
към паметта { G(n)>n }, моделът с
ограничение
на паметта
може да даде
и по-добри
оценки за
ускорението.
Заключение
Изминалите
години
показаха, че
като се започне
от
виртуализацията
на броя на
процесорите,
мине се през
първите
физически
двуядрени
процесори и
се стигне до
днешната реалност
с
най-разнообразни
многоядрени
микропроцесори
и системи,
различните
форми на
паралелизъм
са станали
основна
форма на
тяхната
организация.
Многоядрените
системи са
масово
пазарно
явление – те
са в персоналните
системи, в
мобилните
системи и пр.
и пр.
Производителността
им се
осигурява и
поддържа от
нови
софтуерни
системи, които
също
претърпяха
своята
еволюция.
Така се положи
началото на
нова спирала
в развитието
на
персоналните
системи.
Естествено
възниква
въпросът: в
каква
пропорционалност
е
производителността
от броя на
ядрата на
процесора? И
още въпроси:
В
условията на
много ядра е
очевиден
въпросът:
какво да
правим с тези
ядра? Колко
ядра все пак
са ни нужни?
Как да
преценяваме
тази
необходимост?
И още един
въпрос: какво
да правим с
излишните
ядра? Ако
имаме
популярен в
мрежата
сървър, който
обработва
хиляди
клиентски
заявки в
секунда, то
възможно е да
отделим по
едно ядро на
всяка заявка.
Ако
предположим,
че ситуациите
с блокиране
на сървъра
няма да възникват
често, то
това може да
е добро решение.
Но какво ще
правим с
всички тези
ядра на обикновен
лаптоп? И още
един въпрос: какъв
тип ядро ни е
необходим?
Суперскаларните
ядра с
дълбока
конвейеризация
с предполагаема
суперпроизводителност
върху спекулативни
изчисления и
на високи
тактови
честоти ще се
изявят
великолепно
при изпълнение
на
последователен
програмен код.
Но те няма да
бъдат
подходящи в
условия на
голям обем паралелни
изчисления.
Много
приложения работят
прекрасно с
неголеми и
обикновени ядра,
ако ги имат в
по-голямо
количество.
Много
специалисти
мечтаят за
хетерогенни
мултиядра, но
възниква
същия въпрос:
какви именно
ядра, в какво
количество и
с какви
скорости те
ще работят?
При това още
не сме
споменали за
въпросите,
отнасящи се
до работата
на ОС и на
нейните
приложения.
Ще работи ли
ОС на всички
ядра или само
на някои от
тях? В един
комплект ли
да бъде
мрежовото оборудване
или в
няколко?
Какъв ще бъде
необходимият
обем на
общите
ресурси? Ще
бъдат ли заделяни
конкретни
ядра за
конкретни
функции на ОС
(например, за
комплекта
мрежово оборудване
или за
комплекта за
съхранение на
данни)? Ако се
вземе такова
решение, ще се
тиражират ли
тези функции
за по-добра
мащабируемост?
Цялата армия
от
изследователи
е изправена
пред всички
тези
проблеми и тя
е достатъчно
разномислеща
относно избора
на
подходящите
решения...
Ние
обаче няма да
се
отклоняваме
в тази дискусия.
Читателят може
да намери
множество
публикации в
мрежата,
опитващи се
да отговорят
на тези въпроси,
особено
когато
целите са
комерсиални.
Следващият
раздел е:
§ 5.4
Система за
прекъсване –
общи
разбирания и
положения