Последната
актуализация
на този
раздел е от 2021
година.
6.3.2 Кеш
памет (буфериране
на данни)
А) Основни
разбирания
В
началото на
параграф §6.3,
обосновавайки
ролята и
мястото на
буферната
памет, беше
казано, че
един от
елементите в
запомнящата
система е
значително
по-производителен.
Това, както
се разбира, е
централният
процесор, или
още – всичко
онова, което
е
разположено
върху
интегралната
схема, която
наричаме микропроцесор.
След 2005 година
производствените
технологии
преминаха в
нов клас,
като
започнаха
производството
на
многоядрени
процесори.
Увеличаването
на броя на
процесорните
ядра води до
увеличаване
на честотата
на
единичните
ядра, а от там
и до увеличаване
на общата
честотна
лента.
Съвременен
процесор от
висок клас,
като
например Intel Core i7, който
има две ядра,
може да
генерира две
обръщения
към паметта
за доставка
на данни за едно
ядро за всеки
тактов цикъл.
Вариантът с
четири ядра и
честота 3,2 [GHz] може да
генерира до 25,6.109,
т.е. (25,6
милиарда),
64-битови
обръщения за
данни към
паметта за
една секунда.
Заедно с това
имаме пиково
извличане на
команди от
около 12,8 милиарда
(12,8.109), в
128-битови
блокове с
команди. Този
обмен се оценява
с пикова
честотна
лента от 409,6 [GiB/s]. Тази
невероятна
производителност
се постига
чрез мултипортиране
и
конвейеризиране
на кеш паметите
към
отделните
ядра.
За
разлика от
това,
пиковата
честотна
лента към
основната DRAM-памет е
само 6% от това,
т.е. 25 [GiB/s].
Въпреки
усилията на
конструкторите
и технолозите,
модулите,
реализиращи
оперативната
памет, все
още са с
по-ниска
производителност
и темповете
на растеж на
производителността
в тези два
елемента са с
разходящи
тенденции.
Това
твърдение е
илюстрирано на
следващата
фигура в
относителни
единици, при
положение, че
за начални са
взети съответните
стойностите
през 1980 година.
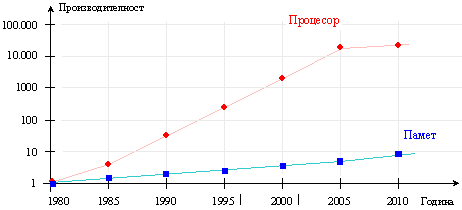
Фиг. 6.3.2.1. Относителни
темпове на
растеж на
производителността
(според
John Hennessy, David Patterson,
“Computer Architecture”, 2012. ISBN:
978-0-12-383872-8)
По
тази причина
буферирането
на трансфера
на данни
между тези
две нива за
сега остава
едно трайно
структурно решение
на проблема.
Буферирането
се постига
чрез
междинна
допълнителна
бързодействаща
памет с
неголям обем,
играеща
ролята на
посредник.
Главното
разбиране за
тази памет е,
че тя не се
намира в
адресното
пространство
на процесора
и не може да
се адресира
от машинните
команди. С
други думи,
тя е невидима
за програмата
(за
потребителя),
откъдето
произлиза и
името й – кеш памет
(cache memory) – скрита
памет. Кеш
паметта се реализира
като бърза
статична RAM-памет.
Задачите, които се възлагат на кеш паметта са следните:
·
Осигуряване
за процесора
на бърз
достъп до
интензивно
използваните
данни ;
·
Съгласуване
на
интерфейса
на процесора
и контролера
на паметта ;
·
Предварително (изпреварващо)
зареждане на
данните ;
·
Отложен
(задържан)
запис на
данните.
За
да изясним
необходимата
логическа
структура и
алгоритъма
за
функциониране
на кеш
паметта
анализираме
хода на
изчислителния
процес, като
необходимост
от
информация
за операционната
част на
процесора.
Тази
необходимост
се задоволява
чрез
непрекъснато
обръщение
към съответните
клетки на
оперативната
памет. Съсредоточаваме
вниманието
си върху това
непрекъснато
претърсване
на
оперативната
памет. Тази
гледна точка
ни позволява
да стигнем до
разбирането,
че работата
на
потребителските
програми се
характеризира
с временно задържане
на
обръщенията,
които те
извършват в
оперативната
памет, в
ограничени
по обем
адресни
области.
Това най-ясно
личи в
случаите,
когато се изпълняват
цикли или се
работи с
масиви от
данни, чиито
елементи се
преработват
многократно.
В тези
случаи,
генерираните
от процесора
адреси, в
кратък
времеви
интервал,
имат
тенденцията
да се изменят
в малък
диапазон и да
попадат в
една или друга
малка по обем
област на
адресното
пространство.
Това може да
се твърди
както за областта,
в която се
намират
командите на
програмата,
така и за
областта, в
която се намират
данните, с
които тя
работи. Ако
се осъществи
статистическо
наблюдение
на обръщенията
на процесора
към паметта,
лесно може да
се стигне до
заключението,
че вероятността
за искане на
достъп до
адрес
съседен или
близко стоящ
до току що
отвореният, е
твърде
голяма. Нещо
повече,
вероятността
това да стане
в
най-близкото
бъдеще е също
висока. Това
свойство на
описаното
наблюдение е
познато под
името принцип на локално
програмно
действие.
Принципът на
локалното
действие е
формулиран
за първи път
през 1968 година
от Питър Денинг
(Peter Denning).
Именно
поради
описаните
два аспекта
на принципа
на локалното
действие - времеви и пространствен,
е изгодно в
буферната
памет да се
съхранява
информация
от няколко
съседни
клетки на оперативната
памет. Може
да се твърди,
че принципът
на локалното
програмно
действие е
следствие от
метода за
естествено
адресиране
на машинните
команди.
Описаният
принцип се
използува
при
проектиране
на буферната
памет за
данни, която
най-често се нарича
кеш памет.
Тъй като
принципът на
локално
програмно
действие има
статистически
характер,
формално
трудно може
да се определи
числено
обемът на
областта, за
която той е в
сила.
Читателят
навярно
разбира, че
това зависи
от характера
на
компютърните
изчисления
(от текущо
изпълняваната
алгоритмична
структура) и
от
структурата
на данните,
които се
преработват,
за което ще
стане дума
тук
по-нататък в
тази глава.
Все пак битува
оценката 90/10, за
която вече
писахме в
началния раздел 6.1
на тази
глава.
Изхождайки
от принципа
за локално
действие на
програмата,
може да се
допусне, че
клетките
(областта от
паметта, към
която принадлежат),
в които е
ограничено
това
действие (или
още то е
активно в
текущия
времеви
интервал),
формират
така
наречения блок,
или още рамка
(фрейм
- frame).
При това
положение, в
интерес на
повишената
производителност,
към която се
стремим, е
лесно
разбираемо,
че е изгодно
и удобно в буферната
памет да се
съдържа
копие от
тази малка
област, в
която се
намират актуалните
за момента
данни.
Буферираните
данни са
копие на
съдържащите
се в основната
памет, при
което те се
озовават в
непосредствена
близост до
процесора, с
всички произтичащи
от това
ползи. Често под
фрейм или още
рамка, се
разбира
най-близкото
обкръжение
на текущо
активните
адреси. От
тук следва,
че рамката
всъщност е
едно копие, в
което
данните се
съдържат с
минимално
излишество.
И
така, всяко
обръщение на
процесора (и
по-точно на
адресиращото
устройство)
към
оперативната
памет, се
извършва с
цел трансфер
на данни, или
още с цел запис/четене
на данни. С
други думи,
при обръщение
е необходим
бърз достъп
до клетка, чийто
адрес е
поставен на
адресната
шина. Бързият
достъп, т.е.
бързото
манипулиране
на данните, в
условията на
присъщваща
буферна
памет, следва
да се
обезпечи
единствено
чрез
подходящо
използване
на техния адрес,
който
формира
процесора.
Ако на пътя
на излизащия
от процесора
адрес стои
кеш паметта,
в която се
съдържат
копия на
някои области
от
оперативната
памет, то е
естествено най-напред
да се провери
дали
съдържанието
на клетката,
която сочи
той, не се
намира в някое
от тези
копия. Ако
проверката
установи
такъв факт на
присъствие,
събитието се
нарича кеш-попадение
(cache hit), в противен
случай
събитието се
нарича кеш-пропуск (cache miss). Като
отчетем
факта, който
вече
споменахме, че
кеш паметта
не може да
бъде
адресируема, то
стигаме до
извода, че
достъпът до
данните в нея
може да бъде
единствено асоциативен.
В ролята на
асоциативен
признак е
възможно да
бъде
използван
единствено
адресът,
който
процесорът е
формирал и
подал. Ще
припомним
(вижте глава
4-та), че
смисълът на
асоциативния
признак е да посочи
степента на прилика
(на
съответствие)
между два
обекта. Ако
тя е голяма,
между двата
обекта се
създава асоциативна
връзка.
Тук
е необходимо
да обърнем
внимание на
още един
факт. Ако в
кеш паметта
се намират копията
на много
клетки,
единствената
прилика,
която може да
се установи
между тях е,
че техните
адреси се
различават
само в младшите
си няколко
разряда, а
старшата им
част е еднаква.
Това се дължи
на
ограничената
по обем
област, в
съответствие
с принципа на
локалното
действие.
Обединявайки
съжденията
от
последните два
абзаца и
подчинявайки
ги на
поставената
цел, лесно се
стига до следния
извод: методът
за достъп в
кеш паметта
(в буферната
памет за
данни) следва
да бъде
асоциативен,
като за
асоциативен
признак на
търсенето
трябва да се
използува
старшата
част на адреса.
Този
асоциативен
признак се
нарича още тег (от tag -
връзка).
При
това
положение
кеш паметта
усложнява своята
структура в
сравнение с
тази на асоциативното
запомнящо
устройство
представено
по-рано тук в
глава 4-та, тъй
като тя, за
разлика от
него, освен
асоциативните
признаци,
трябва да
съхранява и
съответствуващите
им данни.
Така се
получава, че
логическата
структура на
кеш паметта
се състои от
два основни
елемента - справочник
и даннов
масив, както
най-общо е
показано на
фигура 6.3.2.2.
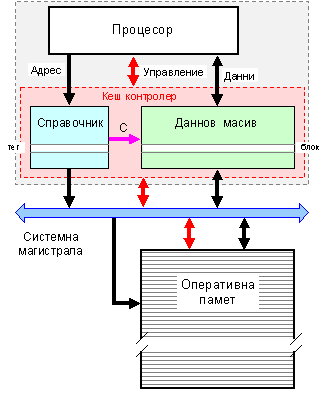
Фиг. 6.3.2.2. Обща
структура и
място на кеш
памет
Сигналите,
излизащи от
справочника
в посока на
данновия
масив са
именувани с
буква С (Съвпадение).
За да
постигне
поставената
цел, кеш паметта
се реализира
от схеми,
имащи възможно
най-високото
бързодействие.
По-късно тук
ще поясним и
други
структурни
особености
на кеш
паметите.
Сега ще
споменем само,
че системата
на буферната
памет също е
йерархична.
Говори се за
кеш памет на
първо ниво (L1), кеш
памет на
второ ниво (L2),
дори за кеш
памет на
трето ниво (L3).
Въпреки че
техническите
показатели
имат изключително
динамични
тенденции за
промяна в условията
на
съвременните
технологии,
за типичния
обем на
отделните
нива на кеш
паметта може
да се каже
следното.
Първо: приема се, че по-големият обем на блока способства за намаляване на честотата на пропуските при обръщение. В същото време обаче по-големите обеми увеличават и закъснението при пропуск. По-големите обеми на блоковете водят до намаляване на броя на таговете. Изборът на правилния размер на блока е сложен компромис, който зависи от общия обем на кеш паметта и величината на загубите от пропуски.
Второ:
очевидният
начин за
намаляване
на пропуските
в кеш паметта
е да се
увеличи
капацитетът
ѝ.
Недостатъците
при това
включват потенциално
по-дълго
време на
претърсване
в справочника
на
по-голямата
кеш памет и
по-висока
цена и
мощност.
По-големите
кешове увеличават
както
статичната,
така и динамичната
мощност.
Трето:
очевидно е,
че с
увеличаване
на
асоциативността,
в кеш паметта
намаляват и
пропуските.
По-голямата
асоциативност
също може да
доведе до
увеличаване
на времето за
претърсване.
Асоциативността
също така
увеличава
енергийната
консумация.
Четвърто:
при
многостепенните
кеш памети е
много трудно
да се вземе
решение дали
да се ускори
времето за
достъп в
кеша, за да се
върви в крак
с високата
тактова
честота на
процесорите
или да се
направи
кешът голям,
за да се
намали
разликата
между
скоростта на
процесора и
основната
памет.
Добавянето
на друго ниво
в
асоциативността
на кеш паметта
обикновено
води до
увеличаване
на времето за
достъп.
Обемът на
кеша L1 може да бъде
достатъчно
малък, за да
съответства
на високата
тактова
честота, но
кешът L2 (или L3) може
да бъде
достатъчно
голям, за да
улови много
обръщения,
които биха
отишли към
основната
памет.
Фокусът
върху
пропуските в
кешове L2 води
до по-големи
по обем на блоковете,
а от там до
по-голям общ
капацитет и
по-висока
асоциативност.
Кешовете на
няколко нива
са енергийно
по-ефективни
от единичния
агрегиран
кеш. Ако това
се отнася и до
кешовете от
първо и второ
ниво, можем
да предефинираме
средното
време за
достъп до
паметта.
Времената за
достъп
обикновено
се
увеличават с
увеличаване
размера на кеша
и на
асоциативността
ѝ.
Предположенията
относно
структурирането
на кеша и
сложните
компромиси
между
закъсненията
на междусистемните
връзки (които
зависят от размера
на кеш блока,
до който се
осъществява
достъп) и разходите
за проверка
на таговете и
мултиплексирането
водят до
резултати,
които понякога
са
изненадващи,
като
например
по-малко
време за
достъп за 64 [KiB] с
двукратна
асоциативност,
в сравнение с
директното
съответствие
(ще бъде
пояснено
по-късно тук).
По същия
начин,
резултатите
с осемкратна
асоциативност
генерират
необичайно
поведение
при
увеличаване
на размера на
кеша. Подобни
наблюдения
отбелязват
силна зависимост
от
технологиите.
Пето:
има случаи, в
които при
пропуск се
дава
предимство
на операции четене
спрямо
операции
запис. Това
се прави с
цел да се
намали
загубата,
понеже
буферът за
запис е
подходящо
място за тази
оптимизация.
Буферите за
запис обаче
създават опасност,
тъй като
съдържат
актуализираната
стойност на
местоположението,
необходимо за
пропускане
на четене – т.е.
опасност за
четене след
запис в
паметта. Едно
от решенията е
да се провери
съдържанието
на буфера за
запис след
пропуск при
четене. Ако
няма конфликт
и ако паметта
е достъпна,
изпращане на
прочетеното
преди запис,
намалява
загубите
след пропуск.
Повечето
процесори
реализират
приоритетно
операция
четене спрямо
операция
запис.
Шесто: в режим на
виртуална
памет (за
която ще говорим
по-късно тук)
следва да се
избягва транслирането
на виртуалните
адреси по
време на
индексирането
на кеша, за да
се намали
времето за
претърсване
на
справочника.
Кеш паметта
трябва да се
справя с
транслацията
на
виртуалния
адрес, подаван
от процесора,
във
физически, с
който се
осъществява
достъп в
основната
памет. Общата
оптимизация
използва
отместването
на
страницата,
т.е. онази
част, която е
идентична
както във
виртуалния,
така и във
физическия
адрес. Този
подход
въвежда
някои системни
усложнения и
ограничения
върху размера
и
структурата
на кеша L1,
но ползите от
премахването
на достъпа до
буфера за
транслация (TLB), са повече
от
недостатъците.
Типичният
обем на
отделните
нива на кеш
паметта се
намира в
границите
както е
изложено в
таблица 6.3.2.1.1.
Таблица
6.3.2.1 Типични
параметри,
характеризиращи
кеш паметта
|
Размер
на блока (кеш
линията) |
От
4 до 128 [B] |
|
Време
за достъп
при
кеш-попадение
(hit time) |
От
1 до 4 такта на
синхронизиращия
сигнал |
|
Закъснение
при
кеш-пропуск (miss penalty) (Време
за достъп - access time) (Време
за трансфер – transfer time) |
От
8 до 32 такта на
синхронизиращия
сигнал (От
6 до 10 такта) (От
2 до 22 такта) |
|
Относителна
част на
кеш-пропуските
(miss rate) |
От
1% до 20% |
|
Обем
на кеш
паметта на
първо ниво (L1) |
От
4 до
128 [KiB] |
|
Обем
на кеш
паметта на
второ ниво (L2) |
От
0,5 до 1 [MiB] |
|
Обем
на кеш
паметта на
трето ниво (L3) |
По-голям
от 1 [MiB] |
Б)
Строеж
на кеш
паметта
Най-напред
ще отбележим,
че дължината
на една
клетка (на
една
адресируема
единица) в оперативната
(основната)
памет
обикновено е един
байт (1[B]). След това
ще отбележим,
че при
съвременното
структуриране
на основната
памет (вижте
коментара
към фигура
6.2.4), данновата
шина е в
състояние да
предава паралелно
няколко
байта
(например 4, 8 и пр.).
Обикновено
порцията
данни, която
се предава по
цялата
ширина на
данновата шина
се нарича блок.
Включените в
блока
байтове имат
адреси, чиито
старши части
са еднакви,
т.е. в
еднобайтовата
последователност
това са
последователни
адресируеми
единици
(последователни
клетки) За да
се уверите в
това
разгледайте
рисунката от
фигура 6.3.2.5
по-надолу.
В
данновия
масив на кеш
паметта
(вижте по-горе
фигура 6.3.2.2) се
намират
копията на
няколко блока
от основната
памет. Всеки
блок заема една
кеш линия. На
същата линия,
но в кеш справочника,
се намира
(тегът)
асоциативният
признак на
групата
байтове в
този блок.
Един блок,
който се състои
от много
думи, се
обозначава с един
признак и
това е онази
част от
адреса, в
която отделните
адреси на
думите
влезли в
дадения блок,
са
еднакви.
Както по-горе
беше
изяснено,
общото
(приликата)
между
байтовете в
блока е, че те
са
последователно
разположени
в адресното
пространство
на оперативната
памет. Или
още -
общият
признак, с
който може да
се идентифицира
съвкупността
от думи в
блока е
еднаквата
старша част
на техните
адреси, а
именно това е
същността на асоциативния
признак.
След
всичко
казано до
момента,
достъпът до клетка
с подавания
от процесора
адрес, при наличието
на кеш памет,
се превръща в
проверка,
дали блокът
към който тя
принадлежи,
се съдържа в
нея. Това
означава, че
при желаната висока
скорост,
тази
проверка
трябва да се
осъществи
чрез асоциативно
търсене,
паралелно
(едновременно)
във всички
клетки на
справочника.
При това,
търсенето се
извършва по
признак (тег),
чийто
характер по
същество е
адрес на блок,
т.е. търсенето
е отговор на
въпроса:
Съдържа
ли се в кеш
паметта дума,
принадлежаща
на блок,
чийто
признак
съвпада с
подавания
асоциативен
признак?
Ако да, процесорът получава достъп до съответната кеш линия, където кеш контролерът извършва основната операция (четене/запис) ;
Ако не, кеш контролерът прави опит да изпълни операцията като търси достъп на по-ниските нива, включително до основната памет.
Така
изложеното
съдържа обосновката
на избрания
метод за
достъп в
справочника. В
крайна
сметка, като
цяло, кеш
паметта се характеризира
като асоциативна
памет, в
която
операцията
“асоциативно
търсене” се
изпълнява в
частта, наречена
справочник, а
основната
операция – в
данновия
масив. Освен
това в кеш
паметта,
както ще
изясним
по-късно, се
извършват и
други специфични
действия,
които я
правят различна
от
обикновената
асоциативна
памет, описана
в §4.4.
Всяка кеш линия има следната структура:
|
тег w [b] |
|
управляващо
поле q[b] |
|
данново поле Q [b] |
||||
|
|
|
|||||||
|
|
|
|
|
дума 1 |
дума 2 |
дума 3 |
…… |
дума k |
Фиг. 6.3.2.3. Структура
на кеш
линията
Ясно
се вижда, че блокът
се съдържа в
полето за
данни и се
предхожда от
общия за
всички думи в
блока асоциативен
признак.
Освен това в
кеш линията се
съдържа още
едно поле,
което се
нарича управляващо.
Необходимостта
от това поле
се обосновава
от метода за
достъп и
алгоритмите
за
изпълнение
на
операциите в
данновото
поле - четене и
запис. Както
беше
изяснено тук
в §4.4 на
тази книга,
изпълнението
на тези
операции при
такъв метод
за достъп е
свързано с
осъществяване
на избор. Именно
за
осъществяване
на една или
друга стратегия
за избор е
предназначено
управляващото
поле.
Достъпът до
даден блок
може да се
получи само
при сигнал за
съвпадение С,
генериран в
съответната
клетка на кеш
справочника.
Проблемът с
избора се
появява във
връзка с
ограничения
обем на кеш
паметта и
неговото
решение се
нарича функция
на
съответствието (mapping function).
Изпълнението
на всяка от
основните
операции
протича по
различен
начин, в
зависимост
от това, дали
обръщението
към кеш
паметта е
успешно или
неуспешно.
Обръщението
се нарича
успешно, ако
при подаване
на тега
(адресният
признак) в
кеша е
открито
съвпадение,
което се
декларира със
сигнала С
(вижте
по-горе
фигура 6.3.2.2). В
този случай
процесорът
се обслужва
от кеш
паметта.
Ако обаче търсеният блок не се съдържа в кеша (открито е несъвпадение), операцията се препраща за изпълнение в по-ниските нива на паметта. Когато обаче операцията трябва да се извърши в основната памет, това означава, че активността на програмата е излязла извън обсега на досегашните локални области, чието отражение се намира в кеш паметта. За да изпълнява тя своите функции, съдържанието й трябва да се обнови автоматично, което от своя страна води до значително усложняване на алгоритмите за управлението ѝ.
Управлението
на кеш
паметта
зависи от структурата
на основната
памет.
Например, ако
основната
памет е
организирана
в k
на брой
разслоени
банки, то
размерът на
блока е
подходящо да
бъде
определен
също на k, т.е. ще
съдържа k
думи. Този
размер е
подходящ
затова
защото прехвърлянето
на блока по
данновата
шина ще се
извършва за
един цикъл на
основната
памет. Ако в
същото време
се приеме в
кеш паметта
да се съхраняват
едновременно
В
на брой
блока, то
данновото
поле на кеш
паметта ще
може да
съхранява (В.k)
на брой думи. Задължително
е да
отбележим, че
обемът на кеш
паметта е
значително
по-малък от
този на
адресното
пространство
на процесора,
което се
определя от дължината
на адреса.
Последното
означава, че
броят на
блоковете (В) в
кеш паметта е
много
по-малък от
броя на блоковете
в адресното
пространство,
т.е.
![]()
където
отношението
в лявата част
на неравенството
(R) изразява
броя на
блоковете в
адресното пространство, структурирано
по блокове с
обем k думи.
Ако
изпълнителният
адрес Аизп,
подаван от
процесора
има дължина L
бита, то
признакът на
всеки блок ще
представлява
старшите w на брой
разряда,
определени
от разликата w=L-s,
където s
е функция от
обема на
блока, който
обикновено е
кратен на 2, т.е. 2s=k.
При такъв
избор,
изпълнителният
адрес се структурира
в две части,
както е
показано по-долу:
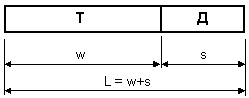
Фиг. 6.3.2.4. Структурна
интерпретация
на адреса
Старшата
w-разрядна
част на
адреса
представлява
тега на
блока, но в
същото време
съответства
и на адрес (начален)
на блок в
основната
памет. Така
се получава,
че адресното
пространство
на основната
памет може да
се
интерпретира
като
структурирана
от
![]()
блока
(рамки,
фрейма), във
всеки от
които има по
![]()
думи. В
този смисъл
младшите s
разряда на
адреса могат
да се
отклоняват към
данновия
масив на кеш
паметта и да
служат за директно
адресиране в
блока на
търсената
дума. Отново
ще обърнем
внимание на
отношението R>>B, което
е реално,
защото в
противен
случай при R=B, кеш
паметта ще
копира
цялото
адресно пространство
на
оперативната
памет, което
е безсмислено.
При този
начин на
структуриране
на адреса
(при това
определение
на тега),
границите на
всеки блок,
които могат
да бъдат
наложени
като рамка
върху
адресното
пространство,
са
ограничени в
обем от k думи.
Нещо повече,
началото на
всеки блок не
може да се постави
в произволен
адрес, а само
в такъв,
който има s
нули в
младшата си
част. Така
границите на блока
ще бъдат от
адрес ааа...аа000...0
до адрес ааа...аа111...11. Както
вече беше
казано, в кеш
паметта има
възможност
да се
съхраняват В
на брой
активни
страници. От
тук следва,
че полето Т в адреса
може да се
интерпретира
като базов
адрес на
блок, а
полето Д
-
като
отместване
на думата
спрямо
базовия адрес.
Към тези
обяснения ще
добавим, че в
съвременни
условия,
обменът с
физическата оперативна
памет е чрез пакети,
които
най-често
представляват
4 на
брой 64-битови
думи (вижте
поясненията
към фигура
4.2.2.7 и
следващите
след нея). Тъй
като
ширината на
процесорната
шина е
величина,
която еволюира
с времето
заедно
цялата
архитектура на
процесора,
дори и да има
други
стойности,
този принцип
за пакетен
обмен едва ли
ще бъде
отменен.
Както
е
илюстрирано
по-долу на
фигура 6.3.2.5, реално
активната за
програмата
област може да
не се съдържа
изцяло в нито
един от двата
съседни
блока. Това
означава, че
при копиране
и на двата
блока (i-тия
и (i+1)-вия) в
кеш паметта,
заедно с
активната
област ще се
копират и
неактивни
части от
адресното
пространство.
Ако
стойността
на старшата
част от
адреса, т.е.
стойността
на тега в рисунката
е (a…a) в
блок №i, то
стойността
на тега на
следващия
блок е (x…x)=(a…a)+1.
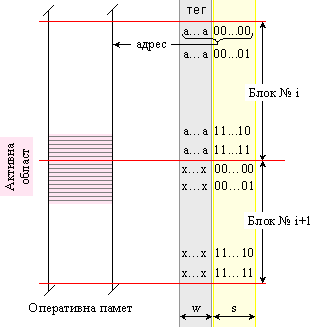
Фиг. 6.3.2.5. Разположение
на локално
активната
област
(граници на
блоковете)
В общия
случай
обаче,
рамката на
блока
(фрейма) би
трябвало да
може да се
разполага от
произволен
адрес А, с
което може да
се осигури
по-висока
вероятност в
кеш паметта
да попадне
цялата реално
активна
област, при
това само в
един блок. От
това следва,
че тегът
трябва да
бъде с
дължина
равна на пълната
дължина на
адреса, т.е. L
бита. Затова
пък, при
такъв тег,
разположението
на блока от k
думи може да
не е в
естествената
последователност
на банките,
от които е
изградена физическата
памет и
следователно
вероятността
неговото
извличане и
прехвърляне
в кеш паметта
да стане за
един цикъл на
основната
памет рязко
намалява.
Това от своя
страна
означава
спадане на
бързодействието.
Ето защо,
въпреки че от
алгоритмична
гледна точка
дългият тег може
да изглежда
по-естествен,
обикновено адресът
се
структурира
както беше
показано на
фигура 6.3.2.4.
Обобщеният
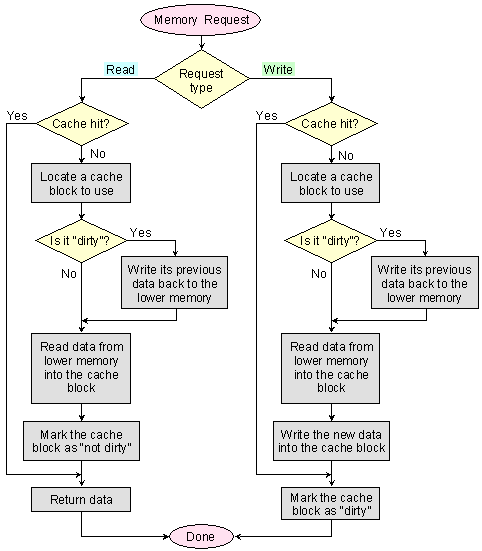
алгоритъм за функциониране
на кеш
паметта е
представен
на фигура 6.3.2.6. В
изходно
състояние
кеш
контролерът
очаква
заявка за
изпълнение
на основна
операция.
Тази заявка
трябва да е
придружена
от изпълнителен
адрес, от
който се
отделя асоциативният
признак, т.е.
тегът.
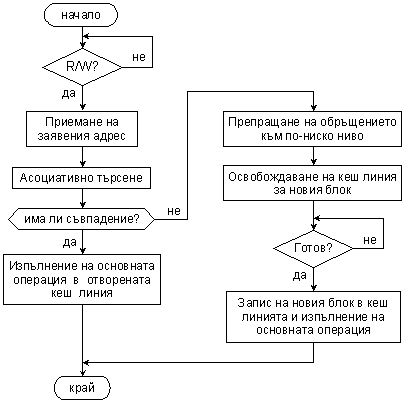
Фиг. 6.3.2.6. Обобщен
алгоритъм за
функциониране
на кеш
паметта
Представеният обобщен алгоритъм ще конкретизираме по-късно тук.
На фигура 6.3.2.7 е показана вътрешната логическа структура на кеш паметта, чийто справочник е реализиран чрез асоциативно запомнящо устройство. Показани са първата и последната кеш линии, както и някои управляващи сигнали и тяхното взаимодействие за изпълнение на алгоритъма за управление.
Както
може да се
види в
схемата,
адресът А, по
който се извършва
асоциативното
търсене, се
подава едновременно
на всички
схеми за
сравнение СхСр
заедно с
признаците
на всеки
отделен блок,
намиращи се в
съответните
тегови
регистри РгТег. Сигналите
за
съвпадение
или
несъвпадение,
генерирани
от схемите за
сравнение,
разрешават
записа на
данни и
признаци или четенето
на данни, в
зависимост
от сигналите
на
операцията –
“Четене на
данни” и
“Запис на
блок”.
Кандидатът
за
изхвърляне в
оперативната
памет се
определя по
съответната
стратегия в
управляващото
поле на кеш
паметта,
което
генерира
разрешаващ
сигнал на
един от
изходите си
ai, i = 1, 2, … , B .
Изхвърляните
данни
излизат на
данновата шина
и се записват
в
оперативната
памет по адрес
Аa,
който излиза
от адресната
шина на
справочника.
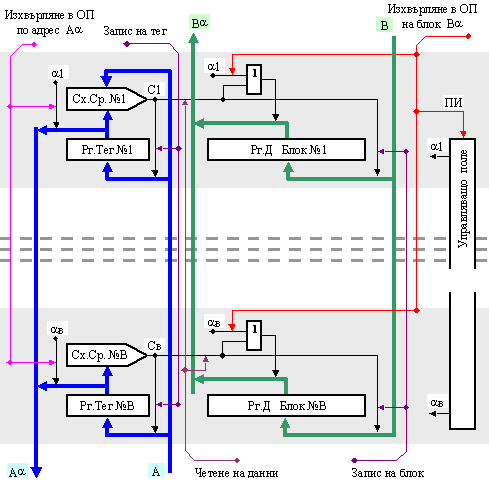
Фиг. 6.3.2.7. Опростена
логическа
структура на
кеш памет с
асоциативен
справочник
В
зависимост
от
възможностите
на кеш паметта
да изпълнява
функциите си
след кеш-пропуск,
се
различават
два вида:
·
Кеш
памет с
блокировка;
·
Кеш
памет без
блокировка.
Първият
вид кеш памет
не може да
функционира
след кеш-пропуск,
докато не
завърши
процеса по подновяване
на
изхвърления
в
оперативната
памет блок.
Това може да
се наложи,
когато непрекъснато
използваните
блокове не се
побират в кеш
паметта и за
да се зареди нов
блок, друг
следва да се
изхвърли. За
съжаление
ако зачестят
подобни
кеш-пропуски,
производителността
на кеш
паметта с
блокировка,
рязко спада.
Такава
ситуация се
нарича колизия
или още насищане.
Вторият
вид кеш памет
е в състояние
да изпълнява
функциите си
паралелно с
процесите
при
изхвърляне и
при запис. С
други думи
кеш-пропуските
не пречат на
кеш-попаденията.
Разбира се
тези
възможности
се
осигуряват с
помощта на значителни
апаратни
разходи.
Заявените
от процесора
операции "Четене
от клетка с
адрес А" и "Запис
в клетка с
адрес А" при
наличието на
кеш памет
протичат
според
обобщения
алгоритъм,
представен
по-горе на
фигура 6.3.2.7. Тук,
протичането
на тези
операции
зависи от
получените
при
асоциативното
търсене
резултати
(съвпадения
или несъвпадения),
които се
изразяват
чрез
стойностите
на функциите F0, F1 и F2 (вижте уравнения
(4.4.2), (4.4.3), (4.4.4) и
обясненията
към тях).
В) Операция
Четене
Операция Четене
се изпълнява
по алгоритъм,
който е
изложен малко
по-подробно в
следната
таблица 6.3.2.2.
Таблица
6.3.2.2 (операция
четене след
асоциативното
търсене)
|
F0 |
F1 |
F2 |
Описание |
|
1 |
0 |
0 |
Подаваният
тег не се
съдържа в
справочника
-
четенето от
кеш паметта
се отменя,
данните се
четат от
по-ниско
ниво,
включително
от основната
памет, след
актуализация
на избран в
кеш паметта
блок. |
|
0 |
1 |
0 |
Подаваният
тег се
съдържа в
справочника
-
данните се
четат от
единствения
блок в кеш паметта,
чийто
признак е
съвпаднал с
подавания
тег. |
|
0 |
0 |
1 |
Подаваният
тег се
съдържа в
справочника
-
данните се
четат от избран
блок в кеш
паметта.
Изборът се
налага
поради
многото съвпадения. |
Най-тривиален
е вторият
случай,
представен в
таблицата,
когато това
което се
търси, се
намира без
алтернативи.
В
случай, че в
кеш паметта
се съдържат
няколко
блока (трети
случай),
чиито
признаци съвпадат
с подавания
тег, се
налага да се
направи
избор.
Изборът се
извършва по
определена
стратегия,
реализирана
чрез
съответната
логическа
схема,
основаваща
се на информацията
в
управляващото
поле на кеш
паметта.
Типичен
пример за
това е
схемата за
избор от фигура
4.4.3.
И
в двата
описани
случая
процесорът
получава
необходимите
му данни от
кеш паметта без
обръщение
към
по-ниските
нива
включително
и към
основната
памет.
Най-сложен
е първият
случай,
когато в кеш
паметта не се
съдържа
търсената
информация. В
този случай
изпълнителният
адрес се генерира
от кеш
паметта, като
се подава по
адресната
шина надолу
към
по-ниските
нива и към основната
памет, към
която се
извършва
обръщение.
При това
обръщение
обаче се
извлича цялата
рамка,
съответствуваща
на подавания
признак
(адрес). Нека
за пример
приемем, че адресът
е с дължина 32
бита, а
блокът има
дължина 128
бита. От това
следва, че
имаме
следните конкретни
стойности за
параметрите w и s:
s = 7[b] , w = 32-7 = 25[b]
, Tag = xxxxxxxxxxxxxxxxxxxxxxxxx .
Така
блокът с
данни, който
ще бъде
копиран от основната
памет, ще се
разполага
между следните
адреси:
А0 = xxxxxxxxxxxxxxxxxxxxxxxxx0000000 ;
.
. . . . .
. . . . . . .
. . . . .
А127 = xxxxxxxxxxxxxxxxxxxxxxxxx1111111 .
Идвайки
от оперативната
памет, блокът
се записва в
кеш паметта,
откъдето
заявената
дума се
изпраща на
процесора.
Записът на
блока в кеша
е свързан с
предположението,
че с това
обръщение към
него той е
станал активен,
т.е. попаднал
е в
полезрението
на програмата
и следователно
е необходимо
да бъде
близко до
процесора. С
други думи,
четенето от
оперативната
памет при
наличието на
кеш памет, е
съпроводено
със запис в
нея, който
обикновено
се нарича “обратен” (write back). Ще
поясним, че
под обратен
се разбира
запис в кеш
паметта в
посока от
по-ниските
нива към
процесора, а
прав – в
посока от
процесора
към кеш паметта.
Съществуват няколко стратегии за зареждане на данни от оперативната памет в кеш паметта. Най-естествената стратегия се нарича “зареждане при поискване” (on demand). Тази стратегия се реализира чрез два алгоритъма. Първият се нарича “Look Through”, т.е. изпълнява се в отговор на кеш-пропуск (cache miss). При този алгоритъм на зареждане, в кеша попадат действително нужните на процесора данни (както и тяхното най-близко обкръжение). Но при първо зареждане (непосредствено след кеш-пропуск) очакването им е твърде дълго (приблизително 20 такта на системната шина), което е съществен недостатък.
Вторият алгоритъм, който се прилага, се нарича “Look Aside”. При този алгоритъм, паралелно с асоциативното търсене в кеш паметта, тегът (т.е. адресът) се подава към по-ниските нива в запомнящата система, където се стартира алгоритъм на изпреварващото извличане. В случай, че при асоциативното търсене се получи кеш-попадение, изпреварващото извличане се прекъсва. Така при алгоритъм Look Aside намалява латентността на данните при зареждане, но апаратните разходи за неговото реализиране са неоправдано големи.
Друг подход за намаляване на латентността (закъснението) при зареждане на данни в кеш паметта е “отложеният запис на данни”. Този подход се реализира чрез буфер от тип опашка, който вече изяснихме в предидущия пункт. Така процесорът е заблуден, че данните, които е изпратил, са вече записани в паметта, което му дава възможност да продължи да работи. Буферът за запис съхранява и адреса и данните, като по този начин позволява данните да се натрупват (разбирайте го като в склад) и там те да изчакват подходящия момент, когато системната шина ще се освободи. Тогава буферът “залпово” “разтоварва” данните в оперативната памет. Така буферът за запис увеличава производителността на кеша. Буферът може да работи паралелно с четене от кеша. Оправданието за всичко това при създаването на кеш паметите е, че ще има по-често четене отколкото запис. Буферът не може да бъде по-дълбок от кеша, за да не се задържа информацията в него, при което на процесора ще се наложи да чака, докато се освободи място в него за нов запис. Казаното се илюстрира със следните две рисунки:
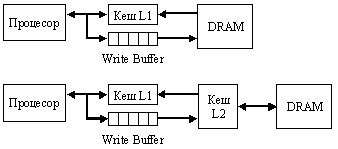
Фиг. 6.3.2.8. Опростена
логическа
структура на
кеш памет с
отложен
запис на
данни
Ще припомним на читателя, че за буфера за запис беше писано и в предходния раздел.
Втората стратегия за зареждане на данни, която ще споменем, носи наименованието “спекулативно зареждане” (speculative). Целта на тази стратегия е да осигури данните в кеш преди те евентуално да бъдат поискани от процесора. Тъй като е невъзможно да се знае кои точно данни ще бъдат необходими в бъдеще време, с тяхната необходимост се спекулира, като се прави опит това да се предскаже. Използваните алгоритми за предсказване се делят на два вида – интелектуални и неинтелектуални. Типичен пример за неинтелектуален алгоритъм е алгоритъма за предварително извличане на машинни команди, който беше разгледан в предидущия пункт 6.3.1. Тук, отнасящо се за данните, този алгоритъм се изразява във зареждане на цялата рамка, както пояснихме по-горе на фигура 6.3.2.5. Трябва да отбележим, че стратегията на изпреварващото зареждане понастоящем на практика се налага по силата на съгласуваната разрядност между оперативната памет и процесора. Става дума за това, че в съвременните системи, въпреки, че адресируемата единица (обикновено) е един байт, трансферът на данни по системната даннова шина, при горните условия, се осъществява чрез пакети, съдържащи няколко байта, запълващи цялата ширина на данновата шина.
Най-сериозният недостатък на изпреварващото (и въобще на неинтелектуалното) зареждане на данни в кеш паметта се състои в това, че избраният от програмиста алгоритъм за обработка на данните по никакъв начин не може да съвпадне с реда на последователното им предварително зареждане. Така заради многократното напразно зареждане на данните в кеша, пада общата производителност на системата.
Кеш-контролерът с интелектуален алгоритъм се старае да предскаже необходимите данни според историята на предидущите обръщения. Въз основа на няколко последователни кеш-пропуска, кеш-контролерът се опитва да установи зависимост в обръщенията. Ако при това се установи някакъв шаблон, спекулативното зареждане е в състояние напълно да отстрани закъсненията при първо зареждане на блок.
По-горе казахме, че при кеш-пропуск на операция четене, в обратната посока данните трябва да се запишат в кеш паметта. Записът на информацията при нейното движение от по-ниското ниво на паметта към по-високото ниво в запомнящата система е самостоятелен проблем, който е свързан със състоянието на кеш паметта. Тук съществуват две възможности:
· Първата възможност се характеризира с това, че в кеш паметта има свободен блок ;
· Втората възможност се характеризира с това, че свободен блок няма.
Проверката на състоянието се постига с помощта на операция “контрол на асоциацията по признака за незаетост”. Тук сме длъжни да дадем допълнителни пояснения. Както вече казахме, състоянието на всяка кеш линия се изразява чрез логическите стойности на специален набор от признаци, който се съдържа в управляващото й поле (вижте по-горе фигура 6.3.2.3). Асоциативното търсене, което се изпълнява в справочника на кеш паметта, използва за асоциативен признак съвкупността от тег и управляващо поле. Тъй като тегът не характеризира състоянието на кеш-линиите, при асоциативното търсене на свободен блок, той се изключва като се маскира. Търсенето се извършва върху съдържанието на управляващото поле. В тази именно част на кеш-линиите се съдържа споменатия по-горе еднобитов признак за незаетост. Асоциативното търсене на незаета кеш-линия може да завърши в общия случай с няколко съвпадения, при което схемата за избор в асоциативната част на паметта ще направи автоматично необходимия избор и пристигналият от по-ниското ниво блок ще се запише в така избраната линия. Освен данните, в кеш-линията се записват още тегът – старшите w бита на заявения адрес (вижте фигура 6.3.2.4), като неин асоциативен признак и признаците на нейното състояние. С това операция четене завършва – изискваният от процесора операнд е достъпен в кеш паметта.
Втората
възможност
се
характеризира
с това, че операция
контрол на
асоциацията
по признака за
незаетост не
открива свободни
блокове в кеш
паметта, т.е.
последната е
изцяло
запълнена. В
този случай
непосредственият
запис на
прочетения
блок е невъзможен.
Налага се
предварително
и принудително
да се
освободи
един от
блоковете в
кеш паметта.
Освобождаването
на кеш
паметта от
блок данни е
много
деликатна
задача. Освобождаването
обаче не може
да се извърши
чрез просто
деактивиране.
Ще припомним,
че общото
разбиране за
кеш паметта,
е като за
памет, в
която се
съхранява копието
на всеки блок
от
оперативната
памет. По време
на работата
на
програмата
обаче
съдържанието
на блока в
кеш паметта е
възможно да е
било обновявано
многократно.
Така, че към
момента на
ситуацията,
която разглеждаме,
това
съдържание
най-вероятно не е
точно копие
на блока в
основната
памет. Този
факт е важен
и той се
регистрира в
управляващото
поле на кеш-линията
чрез отделен
признак. Този
бит се нарича
(dirty bit –
мръсен бит) и
показва дали
блокът, на
който съответства,
съдържа
обновявани
данни, т.е. когато
е установен в
единица, това
означава, че
данните са били
променени
(замърсени) и
не съвпадат с
копието си в
основната
памет. Съществува
практика,
обновените
блокове да се
наричат “мръсни”
или “замърсени”
(dirty).
Ето защо,
освобождаването
на така
избрания в
кеш паметта
блок, трябва
да се изпълни
чрез запис в
по-ниско ниво
на системата,
включително
в оперативната
памет. Тези
действия
обикновено
се наричат “изхвърляне
на блок от
кеша” и
представляват
процес на
движение на
информация
от
по-високото
ниво към
по-ниското ниво
на
запомнящата
система. В
тази ситуация
съществува
частен
случай, при
който избраният
за
изхвърляне
блок не е бил
обновяван, т.е.
неговото
съдържание
не е
променяно.
Ясно е, че в
този случай
изхвърлянето
не е наложително
и новият блок
се записва на
неговото
място, т.е.
той
припокрива.
Така значително
се ускорява
края на
основната
операция.
Преди
да се
пристъпи към
каквото и да
било освобождаване
трябва да се
направи
избор. Изборът
се извършва
измежду
всичките
намиращи се в
кеша блокове,
по
стратегията
заложена в
управляващото
поле на кеш
паметта. В
този момент
всички
блокове се
разглеждат
като "кандидати"
за
изхвърляне.
Логично е,
изборът да се
"стовари"
върху онзи
"кандидат", който не би
бил
необходим за
в бъдеще на
текущата
програма. Ако
такъв блок
бъде намерен,
той се
прехвърля
надолу към
по-ниските
нива в
йерархията
на
запомнящата система,
с което в
крайна
сметка се
актуализира
съдържанието
на
оперативната
памет. След
това на
негово място
се записва,
както по-горе
вече
обяснихме,
заявения
блок. С това
завършва
операция
Четене.
Г) Операция
Запис
Операция
Запис,
заявена от
процесора,
също има
своите особености,
които обаче
са
значително
по-проблематични.
Както и при
операция
четене, адресът,
по който
следва да се
извърши
операцията,
се търси
първоначално
в кеш
паметта. Ако
настъпи
кеш-попадение,
данните
подавани от
процесора се
записват в
кеш паметта.
Тук се
предполага,
че асоциативното
търсене с
подадения от
процесора
тег (адрес),
е изявило
едно или
много
съвпадения,
от които в
крайна
сметка,
схемата за
избор в
асоциативната
част на
паметта, е
направила
достъпна
избраната
кеш линия. Записът
на данните в
избраната
кеш-линия превръща
съхранявания
блок в обновено
копие. С
други думи,
блокът в кеш
паметта с
обновено
след
операция
запис
съдържание,
не е копие на
съответния
блок в
оперативната
памет. Докато
блокът се
намира в кеш
паметта, неговото
съдържание
може да бъде
многократно обновявано
и различията
със
съответното съдържание
на
оперативната
памет могат да
се засилват.
Следва да
кажем, че
модификацията
на блока не
може да
започне,
докато се проверява
тега и
кеш-контролерът
не се убеди, че
е получил
кеш-попадение.
Тъй като
сравнението
на теговете
не може да се
изпълнява паралелно
с други
действия, то
операция
запис е
по-продължителна
от операция
четене.
За съжаление, благодарение на многобройните паралелно протичащи във времето процеси, използващи оперативната памет, различията, за които споменахме по-горе, могат да станат още по-силни, а това е доста опасно. За да бъдем конкретни ще спомене поне една независима от процесора причина за изменения на съдържанието в оперативната памет – запис на данни при входни-изходен обмен чрез каналите за пряк достъп до паметта. Този обмен може да се поиска например от бързо външно устройство. Обратно, при извеждане на данни, прочетените от оперативната памет данни и изпратени към външното устройство ще бъдат “остарели” в сравнение с тяхното обновено копие в кеш паметта. Същността на този проблем се състои в несъответствието на данните в различни точки и в различни моменти. Този проблем налага спазването спрямо данните на специална политика (поведение, стратегия) – политика за запис и поддържане на кохерентността на кеш паметта (coherence – съгласуваност). Осигуряване на съответствието (кохерентността) във времето и по място на данните за програмите е сериозна задача и ние ще я разгледаме тук в отделен раздел.
Ще се върнем отново на операция запис, при която е възможно и другото събитие – да настъпи кеш-пропуск. Това означава, че формираният от адреса тег не се намира в кеш паметта. С други думи данните, които процесора иска да запише, принадлежат на блок, който е неактивен и все още се намира в оперативната памет или е бил вече изхвърлен. Необходимо е да обърнем внимание на това, че ответните действия след кеш-пропуск при операция запис, се различават от тези след кеш-пропуск при операция четене.
Така или иначе, блокът, в който попада адресът, трябва да се копира в кеш паметта, тъй като той вече е активиран от програмата. След като се установи фактът за несъвпадение, изпълнението на операцията продължава най-напред с изпълнение на операция контрол на асоциацията по признака за незаетост, както описахме при операция четене. След това къде и как ще бъде прехвърлен активираният блок кратко е изразено чрез таблица 6.3.2.3.
Таблица
6.3.2.3 (операция
запис след
асоциативното
търсене)
|
F0 |
F1 |
F2 |
Описание |
|
1 |
0 |
0 |
Всички
блокове в
кеш паметта
са заети. Запис
се извършва
след
освобождаване
на избран в
кеш паметта
блок. |
|
0 |
1 |
0 |
Има само
един
свободен
блок и запис
на данните
се извършва
в него. |
|
0 |
0 |
1 |
Има
много
свободни
блокове. Запис
се извършва
в избран
свободен
блок. |
За
осигуряване
на
кохерентността
на данните по
време и място
се
практикуват
два алгоритъма
за
изпълнение
на операция
запис. Първият
се нарича “едновременен
запис” (write through). Логиката
на този
алгоритъм се
изразява в
решението за
незабавен
запис на данните
както в кеш
паметта така
и в оперативната
памет. В
резултат на
това сме
сигурни, че в
оперативната
памет се
съхранява
във всеки
един момент
най-достоверната
информация.
Естествено
всички
елементи на
компютърната
система,
които
съхраняват
копия тази
информация
следва да
следят за
нейното обновление,
за да могат
своевременно
да актуализират
своите копия.
Последното е
особено
важно за
мултипроцесорните
системи. Този
алгоритъм е
лесен за
реализация.
При него се работи
направо с
основната
памет, все
едно че
липсва кеш
памет.
Логиката на
едновременния
запис обаче
води до
повишаване
на интензивността
на обмена
между
оперативната
памет и
всички
елементи на
системата,
които
следейки
актуалността
на нейното
съдържание, в
отговор
незабавно
трябва да
актуализират
своите копия.
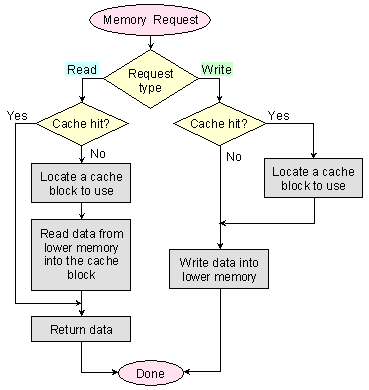
Фиг. 6.3.2.9. Алгоритъм
на кеш памет
с
едновременен
запис на
данни (write-through)
Вторият
алгоритъм се
нарича “обратен
запис” (write back) и
беше вече
споменат
по-горе при
операция
четене. Според
този
алгоритъм,
запис на
данните се извършва
само в кеш
паметта, но
състоянието
на кеш-блока
се отбелязва
като
обновено в управляващото
поле с
признак,
наречен “update” или
както по-горе
бе споменато
– като “dirty” (мръсен). Ако
външно
устройство
поиска данни
от оперативната
памет,
кеш-контролерът
трябва да
провери дали
копие от тези
данни не се
намира в кеш
паметта и
дали то не е
обновено. Ако
данните са
обновявани,
входно-изходният
обмен се
блокира,
докато
данните в
оперативната
памет не се
актуализират.
За целта, съответният
блок в кеш
паметта се
записва в оперативната
памет, а
неговото
състояние се отбелязва
като “чисто” (clear). Ще
вметнем, че
при
определяне
на кандидатите
за
изхвърляне,
кеш-контролерът
се стреми
най-напред да
използва “чистите”
кеш-линии,
тъй като те
могат да
бъдат подменени
с ново
съдържание
веднага, без
да е необходимо
да бъдат
изхвърляни
със запис в
оперативната
памет.
Следователно
началното
състояние на
всеки
новопостъпил
в кеш паметта
блок трябва
да е “чисто”.
Фиг. 6.3.2.10. Алгоритъм
на кеш памет
с обратен
запис на данни
(write-back)
В компютърни системи с няколко процесора, имащи собствени кеш памети и работещи с обща оперативна памет, задачата за поддържане на кохерентността на отделните кеш памети е от изключително значение. Проблемът е в това, че когато даден процесор обнови данните в своя кеш, дори той да прилага алгоритъма на едновременния запис (write through), не може да се гарантира достоверността (съответствието) на данните в другите кеш памети.
В най-сложната ситуация – кеш-пропуск при запис, а може да се каже въобще при кеш-пропуск и пълна кеш памет, се налага да се освободи един блок от кеш паметта, за да може процесорът да продължи работата си. Освобождаването на блок от кеш паметта е свързано отново със схемата за избор на "кандидата за изхвърляне", при което се използува същата стратегия, както при аналогичната ситуация в операция четене.
За подобряване на производителността може да се включи буфер за запис за временно съхранение на заявки за запис. Процесорът поставя всяка заявка за запис в този буфер и продължава изпълнението на следващата инструкция. Заявките за запис, съхранени в буфера за запис, се изпращат в основната памет, когато паметта не отговаря на заявки за четене. Важно е заявките за четене да се обслужват бързо, тъй като процесорът обикновено не може да продължи, преди да получи четените данни от паметта. Следователно тези заявки имат приоритет пред заявки за запис.
Буферът за запис може да съдържа няколко заявки за запис. По този начин е възможно последваща заявка за четене да се отнася до данни, които все още са в буфера за запис. За да се осигури коректна работа, адресите на данните, които трябва да се четат от паметта, винаги се сравняват с адресите на данните в буфера за запис. В случай на съвпадение се използват данните в буфера за запис.
Подобна ситуация се случва с протокола за обратен запис. В този случай командите за запис, издадени от процесора, се изпълняват върху думата в кеша. Когато трябва да се въведе нов блок с данни в кеша в резултат на пропуск при четене, той може да замени съществуващ блок, който има някои “мръсни” данни. Замърсеният блок трябва да бъде записан в основната памет. Ако първо се извърши необходимото обратно записване, тогава процесорът трябва да изчака тази операция да приключи, преди новият блок да бъде прочетен от кеша. По-разумно е първо да прочетете новия блок. Мръсният блок, който се изважда от кеша, временно се съхранява в буфера за запис и се съхранява там, докато се прочете новият блок. След това съдържанието на буфера се записва в основната памет. По този начин буферът за запис работи добре и с протокола за обратен запис.
Практикува се още предварително извличане. В предходното обсъждане на механизма за кеширане предположихме, че новите данни се внасят в кеша, когато са необходими за първи път. След пропускане на четенето, процесорът трябва да направи пауза, докато новите данни пристигнат, като по този начин се дължи наказание за пропуск. За да се избегне забавяне на процесора, е възможно да се извлекат данните в кеша, преди да са необходими. Най-простият начин да направите това е чрез софтуер. В набора от инструкции на процесора може да се предостави специална инструкция за предварително извличане. Изпълнението на тази инструкция води до зареждане на адресираните данни в кеша, както в случай на пропуск при четене. Командата Aprefetch се вмъква в програмата, за да заповяда данните да бъдат заредени в кеша малко преди да са необходими на програмата. Тогава процесорът няма да трябва да чака референтните данни, както в случай на пропуск при четене. Надеждата е, че предварителното извличане ще се осъществи, докато процесорът е зает с изпълнение на команди, които не водят до пропускане на четене, като по този начин позволява достъпът до основната памет да се припокрива с изчисленията в процесора.
Командите за предварително извличане могат да бъдат вмъкнати в програмата или от програмиста, или от компилатора. Компилаторите могат да вмъкват тези команди с добър успех за много приложения. Предварителното извличане на софтуер включва определени режийни разходи, защото включването на предварителното извличане на команди увеличава продължителността на програмите. Освен това някои предварителни извлечения могат да се заредят в кеша за данни, които няма да бъдат използвани от следващите команди. Това може да се случи, ако предварително извлечените данни се изхвърлят от кеша от пропуск при четене, включващ други данни. Общият ефект от предварителното извличане на софтуер върху производителността обаче е положителен и много процесори имат машинни команди, които поддържат тази функция. Предварителното извличане може да се извърши и с хардуер, като се използват схеми, които се опитват да открият шаблон в препратките към паметта, като предварително извличат данни според този модел.
Ще коментираме още и кеш паметта без блокировка. Предварителното извличане на софтуер за кеширане без заключване не работи добре, ако пречи значително на нормалното изпълнение на командите. Това е така, ако действието на предварителното извличане спира други достъпи до кеша, докато предварителното извличане не приключи. Докато обслужва пропуск, кешът се заключва. Този проблем може да бъде решен чрез модифициране на основната структура на кеша, за да позволи на процесора достъп до кеша, докато се обслужва пропуск. В този случай е възможно да има повече от една забележителна грешка и хардуерът трябва да открива и обслужва такива случаи.
Кешът, който може да поддържа множество неизпълнени пропуски, се нарича с блокиране. Такъв кеш трябва да включва верига, която проследява всички неизпълнени пропуски. Това може да се направи със специални регистри, които съдържат съответната информация за тези пропуски. Кешовете без заключване (блокировка) се използват за първи път в началото на 80-те години в серията компютри Cyber, произведени от компанията Control Data.
Използвали сме предварително извличане на софтуер, за да мотивираме нуждата от кеш, който не е заключен от пропуск при четене. Много по-важна причина е, че в конвейерния процесор, в който се припокрива с изпълнението на няколко команди, пропуск при четене, причинен от дадена команда, може да спре изпълнението на други команди. Кешът без заключване намалява вероятността от такива случаи.
Д) Стратегии
за
изхвърляне
На практика вижданията на конструкторите върху организацията на операциите четене и запис в условията на кеш памет не са единни. В голяма степен от това зависи онази част от алгоритмите на тези операции, която е свързана с процедурата за заместване на блокове, при която в кеш паметта се извършва запис (обратен).
Съществуват множество алгоритми за управление на процеса на изхвърляне, при който има движение на информация от по-високото ниво към по-ниското ниво в йерархията на запомнящата система. Паралелно със "слизането" се осъществява "изкачване" на информация от по-ниското ниво към по-високото ниво.
Оптимизацията
на този процес
на
заместване
се състои по
същество в най-правилния
избор на
кандидата за
изхвърляне.
Задачата за
избор може да
се реши само
ако са
известни
вероятностите
за използуване
на отделните
блокове в бъдеще
време. Тогава
е ясно, че
първият блок,
който трябва
да напусне
буферната
памет (в
общия случай
по-високото
ниво), е онзи
блок, който ще
се използува
най-малко
(най-рядко) за
в бъдеще.
Трудността
за
реализация
на тази
логика се
състои в
това, че при
изпълнение
на програмата
не
съществува
възможност
за оценка на
вероятността
за използуване
на всеки
отделен блок в бъдеще
време. Но
може да се
натрупа
такава
оценка за
използуването
му до
момента.
Алгоритмите
за
управление
на
заместването,
които се
основават на
оценка на
вероятността
за обръщение
към блока в
бъдеще време
се наричат физически
нереализуеми.
Тези, които
се основават
на оценка на
вероятността
за обръщение
в минало време
се наричат физически
реализуеми.
Най-известни са следните алгоритми:
а)
Алгоритъм на
случайния
избор RC (random choice),
при който се
изхожда от
предположението,
че всички
блокове имат еднакъв
шанс в бъдеще
време ;
б)
Алгоритъм LFU (Least Frequently Used),
при който се
изхвърля
онзи блок,
който е бил
използуван
най-малко до
момента ;
в)
Алгоритъм LRU (Least
Recently Used), при който
се изхвърля
онзи блок,
който е бил най-отдавна
не
използуван ;
г)
Алгоритъм FIFO, при
който се
изхвърля
онзи блок,
който се е
намирал най-дълго
време в
по-високото
ниво.
Механизмът на всяка една от възможните за избор стратегия се реализира апаратно, като резултатите от неговата работа се използуват от управляващото устройство на кеш паметта (контролер на кеш паметта), реализиращо алгоритмите при операциите четене и запис.
Д1) Изхвърляне
на случаен
блок (RC)
Най-лесно
се реализира
алгоритъмът
на случайния
избор RC.
За целта в
управляващото
поле се
поставя един
циклически
изместващ
регистър с
дължина
равна на
обема на справочника,
т.е. на броя
блокове в кеш
паметта – както
е показано на
фигура 6.3.2.11.
Изместващият
регистър
реализира
модела на
“бягащата единица”,
чието
случайно
местоположение
сочи
кандидата за
изхвърляне.
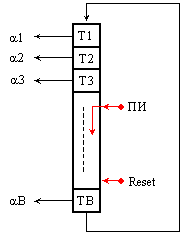
Фиг.
6.3.2.11. Схема за
реализация
на алгоритъм
RC
След
всяко
изхвърляне
от кеш
паметта, в
управляващото
поле УП се
изпраща
сигнал ПИ
(признак за
изхвърляне)
(вижте
сигнала на фигура
6.3.2.7 по-горе).
Сигналът ПИ
възбужда
микрооперация
изместване,
при което
намиращата
се в i-тия
разряд
единица, се
премества в (i+1)-я разряд.
Така той сочи
като
кандидат за
изхвърляне
при
следващия
кеш-пропуск,
блок със
същия номер.
При тази
организация
всеки блок
престоява в
кеш паметта
определено
време и след В на
брой
замествания
идва неговият
ред.
Очевидно е, че този алгоритъм за управление на заместването често води до изхвърляне на активни блокове и в същото време до съхраняване на блокове, които са загубили активност. В резултат на това се повишава интензивността на обмена с основната памет и следователно се снижава производителността на системата.
Д2) Изхвърляне
на най-малко
използвания
до момента
блок (LFU)
По-прецизен
(по-логичен) в
сравнение с
предходния
се явява
алгоритъма
за
управление LFU.
За да се
реализира
логиката на
алгоритъма
(съдържаща се
в самото
наименование)
трябва да
бъде
оценявана
активността
на всеки
блок, намиращ
се в кеш
паметта.
Активността
е функция на
обръщенията
от страна на процесора
и в този
смисъл
състоянието
на всеки блок
се отбелязва
в
управляващото
поле. Предвид
на масовото
използване
на този алгоритъм
ще
разгледаме
възможните
апаратни
схеми за
оценка на
активността
на всеки отделен
блок.
1. Възможно
най-тривиалната
схема е
представена
на фигура 6.3.2.12.
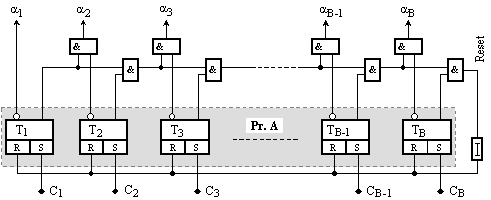
Фиг.
6.3.2.12. Схема за
реализация
на алгоритъм
LFU
Тригерите (Тi, i=1, 2, ... , B) в
представената
схема са
предназначени
да показват
активността
на
съответния
блок. Ако
състоянието Qi=1,
то блокът с
номер i се
приема за
активен, а
активен
става даден
блок винаги,
когато към
него има
успешно
обръщение
(кеш-попадение),
т.е. появява
се сигнал за
съвпадение Сi от
схемите за
сравнение на
признаците в
асоциативната
част на кеша.
Ако тригерът Тi е
бил активен (т.е. Qi=1),
то всеки
следващо
появил се
сигнал Ci само
потвърждава
неговото
състояние.
Онези
разряди в
регистъра на
активността РгА,
които са в
състояние
нула,
представляват
кандидатите
за
изхвърляне.
Всеки
път, когато
всички
разряди на РгА се
установят в
единично
състояние, се
формира
сигналът Reset=(Q1ÇQ2ÇQ3Ç ... ÇQB), който
се използува
за нулиране
на регистъра,
с което
схемата се
самовъзстановява
(излиза от
наситено
състояние).
Изборът
на кандидат
за
изхвърляне
се осъществява
от схемата за
избор, по
правилото на кандидата
с най-малък
номер,
означен като
неактивен. С “най-малък
номер"
означава
първия
срещнат.
2. Една още по-прецизна реализация на описаната стратегия изисква на мястото на тригерите от фигура 6.3.2.12 да бъдат поставени броячи. По този начин преброените в отделните броячи сигнали за успешно (или неуспешно) обръщение, по-прецизно ще градират степента на активност на всеки отделен блок. Функцията за избор в този случай ще използува като аргументи съдържанията на броячите, интерпретирайки ги като цели числа. Изборът по същество се осъществява чрез операция асоциативно намиране на най-малкото (най-голямото) съдържание в съответния брояч (за този алгоритъм вижте пункт 4.4.1). От тук следва, че съвкупността от броячи, измерващи активността (респективно неактивността) на блоковете, следва да представлява запомнящо устройство с асоциативен метод за достъп. За постигане на висока скорост на избора, устройството трябва да е с пълна асоциация.
Друг
смисъл на
тези броячни
оценки може
да бъде
постигнат
при следното
поведение. Нека
при всяко
успешно обръщение
(кеш-попадение)
към даден
блок, сигналът
за
съвпадение Ci да
се използва
за нулиране
на
съответстващият
му i-ти
брояч, докато
в същото
време към
всички останали
броячи (на
които
съответства
кеш-пропуск)
се прибавя
единица. Така
в този случай
броячите ще
измерват
"възрастта"
или времето
за престой
на всеки от
блоковете в
кеш паметта
след последното
успешно
обръщения
към съответния
им блок.
Представените по-горе две схемни решения за оценка на активността на отделните блокове имат недостатъка да се “препълват”. Моментът на най-добрата оценка може да се размине със ситуацията, когато тя може да бъде необходима. Препълването като крайно състояние или чистото начално състояние, също може да попадне така да се каже в неподходящ момент.
Д3) Изхвърляне
на най-отдавна
не
използвания
блок (LRU)
Схемното
решение на
логиката LRU, според
която
изборът на
кандидат за
изхвърляне
се изразява в
изказването “най-отдавна
неизползвания”
блок, което с
други думи
може да се
изрази още
така – “най-дълбоко
забравения”
блок, е силно
различно от
горе
представените.
Като се
замислим, би
следвало да
доловим съществена
разлика от
преди
изказаните в
точка 1 и 2
логики, които
оценяват
честотата на използване
на блоковете.
За разлика от
тях, току що
предложената
логика
предполага оценяване
на времето за
престой на
всеки блок в
кеш паметта.
Непосредствено
оценяване на
времето
обаче не се
реализира.
Логиката “най-отдавна
неизползвания”
се постига
чрез
своеобразна
опашка от тип
LIFO, в
която се
нареждат
номерата на
записаните
блокове и
която се
нарича LRA-стек.
Ще поясним
поведението
на тази опашка
чрез следния
пример: в кеш
паметта
последователно
са постъпили
4 блока,
съответно номерирани
1-ви, 2-ри, 3-ти и 4-ти.
При
кеш-попадение,
номерът на
блок
“изскача” на
върха на
опашката.
Нека да
приемем, че е
имало
обръщение
към 3-ти блок.
Тогава редът
ще стане 3,4,2,1. Ще
представим
това чрез
следната
рисунка:
Нека сега се изпълнят следните последователни обръщения: към 1-ви, после към 2-ри, после към 4-ти и после пак към 1-ви блок. Съответното подреждане след всяко обръщение (рисунки а,б,в,г) е представено на следващата рисунка:
Вижда се, че след последното обръщение, най-отгоре е блок номер 1, най-отдолу – блок номер 3. Именно блок номер 3 е най-отдавна неизползваният. Останалите блокове са подредени в посока към върховата позиция в съответствие с изминалото време. Следователно ако при следващото обръщение се получи кеш-пропуск и е необходимо място за нов блок, то опашката ще посочи за изхвърляне блок номер 3.
Логиката
на описания
избор може да
се реализира
технически с
помощта на
логическа схема,
чийто
достатъчно
общ вид е
представен
по-долу. За
конкретност
е показана
схема, която
обслужва
само 4 блока. В
общ случай нейният
вид следва да
се разшири
пирамидално
така, че да може
да обслужва
необходимия
брой блокове.
Представената
схема има 4
входа, на
които постъпват
импулсните
сигнали С1, С2, С3
и С4, формирани
при всяко
отделно
обръщение
към съответните
блокове в кеш
паметта. Във
вертикално
направление
са подредени
асинхронни RS-тригери,
предназначени
да запомнят
извършеното
към
съответния
блок
обръщение,
постъпващо
на S
входовете на
тригерите от
съответния
ред. В общия
случай
подредените
тригери
образуват
дясна
триъгълна
матрица с размери
(n-1)x(n-1),
ако се
приеме, че с n е означен
общият брой
на блоковете
в кеш паметта.
Ако
приемем, че в
даден момент
е осъществено
успешно
обръщение
към блок №1, в
резултат на
което се
формира
импулс С1, то
този импулс
ще установи в
единично
състояние
всички
тригери в
първия ред.
Това означава,
че С1 е
изпреварило
във времето
всички останали
сигнали С2, С3 и
С4.
Логическата
схема, която
определя
победилия в
състезанието
във времето
сигнал, е
показана
по-долу.
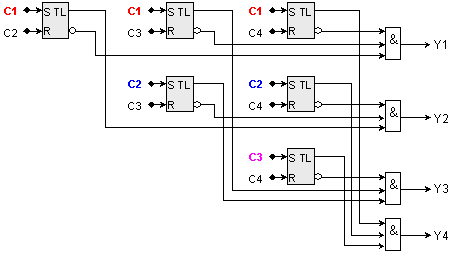
Фиг. 6.3.2.13. Логическа
схема за
избор в
алгоритъм LRU
Изходите
на схемата (Y1, Y2, Y3, Y4) са
толкова,
колкото са и
входовете
(блоковете).
Действието
на схемата е
такова, че
във всеки
момент на
всички тези
изходи има
само нули, с
изключение
само на един,
на който има
единица. След
всяко ново
обръщение тази
единица е
възможно да
се премести
по съответния
начин нагоре
или надолу
(на друг изход),
показвайки
по този начин
избрания за изхвърляне
кандидат.
Така
например,
когато Y4=1,
това
означава, че
след появата
на импулса С4
са се появили
импулсите С3,
С2, и С1 (в произволен
ред). Само
след такава
последователност
тригерите в
най-дясната
колонка ще
бъдат
едновременно
в единично
състояние,
събирайки се
по този начин
на входовете
на
най-долната
схема И, и
формирайки
изходната
единица за Y4. Последната
указва на
блок №4, като
на най-отдавна
не
използвания
(измежду
дадените 4), което
точно
съответства
на дадената
примерна
последователност
(С4®С3®С2®С1).
Д4) Изхвърляне на
блок според
реда му на
записване в
кеша (FIFO)
Според
логиката на
този
алгоритъм, за
неговата
реализация е
необходима
опашка, в която,
при
първоначално
постъпване
на блок в кеш
паметта, се
записва
неговият
номер. Така съдържанието
на тази
опашка (за
разлика от по-горе
описаната) не
се
преподрежда,
докато
блоковете се
намират в кеш
паметта. Ако се
наложи,
кандидатът
за
изхвърляне
се сочи от
номера на
блока, стоящ
на изхода на FIFO-опашката.
Д5) Други
стратегии за
изхвърляне (Replacement
Policy)
По-долу
са изброени
стратегии за
изхвърляне
на блок от
кеш паметта,
които в
добавка към
по-горе разгледаните,
също се
прилагат
често. Множеството
допълнителни
стратегии
няма да изчерпваме.
Някои кратко
ще поясним
тук, а тези
които ще
пропуснем,
оставяме на
любознателния
читател:
·
Pseudo-LRU (PLRU) ;
В тази разновидност (най-отдавна неизползвания блок) става дума за свързани с логиката на стратегията алгоритми, които целят да я усъвършенстват. Вместо да поддържа точна оценка за времето, през което съответният блок не е бил използван, псевдо-алгоритъмът използва приблизителна оценка за това време. Стратегията PLRU има две основни разновидности в своите реализации. Първата от тях се нарича Tree-PLRU (Дърво-PLRU), а втората Bit-LPRLU (Бит-PLRU). Псевдо алгоритмите се основават на флагове или указатели за всеки блок при обхождането им с цел избор. Разходите за внедряване на стратегиите PLRU значително нарастват, когато степента на асоциативност на кеша надхвърли числото 4.
·
Most recently used (MRU) – последно
използван блок ;
Според логиката на тази стратегия на изхвърляне подлежи последно използваният блок. Основания за това се намират в предположението, че колкото по-стар е даден блок, толкова по-вероятно е той да бъде потърсен.
·
Least frequent recently used (LFRU)
– от
най-актуалните,
най-малко
използвания ;
Стратегията
LFRU разделя
кеша на два
дяла,
наречени привилегирован
и
непривилегирован.
Привилегированият
дял може да
бъде
дефиниран като
защитен дял.
Ако
съдържанието
е много актуално,
т.е. много
популярно, то
се премества
и поддържа в
привилегирования
дял. Заместването
на блок от
привилегирования
дял се
извършва по
следния
начин: Първо -
изважда
(изхвърля) се
блок от
непривилегирования
дял. Второ - на
негово място
се записва избран
блок от
привилегирования
дял. Трето - в
освободения
блок на
привилегирования
дял се
записва ново
съдържание,
прочетено от
паметта. Това
е логика,
според която
актуалността
на блоковете
се степенува
и се поддържа
на две нива.
·
Not Least Recently Used (NLRU) – не
най-малко
наскоро
използван ;
Странно наименование – стратегията използва брояч за всеки блок, в който се отброяват успешните обръщения. Така тези броячи отразяват честотата на използването на отделните блокове. За изхвърляне се избира блокът, който е отбелязан с минимална честота. През определен времеви интервал броячите се нулират.
Както вече споменахме, пояснените по-горе стратегии за изхвърляне все още не са всички, за които може да се разкаже, но тук ние считаме, че проблемът на илюстрираната тема е достатъчно подробно изяснен. Читателят е този, който при желание може да продължи своето изследване.
Е) Функция с
пълно
асоциативно
съответствие
Както
вече беше
казано в
точка Б),
проблемът с
избора на
блок в кеш
паметта, се
появява във
връзка с
ограниченият
ѝ обем
(B<<R).
Изборът
в
асоциативната
памет, както
беше изяснено
в глава 4, се
предхожда от
асоциативно
търсене, с
цел
откриване на
съвпаденията.
Специална
логическа
схема
реализира
самия избор измежду
изявените
съвпадения.
Ако справочникът
е реализиран
като напълно
асоциативно
запомнящо
устройство,
той би
съответствал
на схемата от
фигура 6.3.2.7, а
адресът,
подаван от процесора
се
интерпретира
структурно
според
фигура 6.3.2.4.
Такава кеш
памет се
нарича “с пълна
асоциация”.
Нейната
функция на
съответствие
носи същото
наименование.
Съответствието
между подавания
от процесора
адрес на
данни и
тяхното
местоположение в
адресното
пространство
на паметта
според тази
функция се
изразява
чрез схемата
от фигура 6.3.2.14.
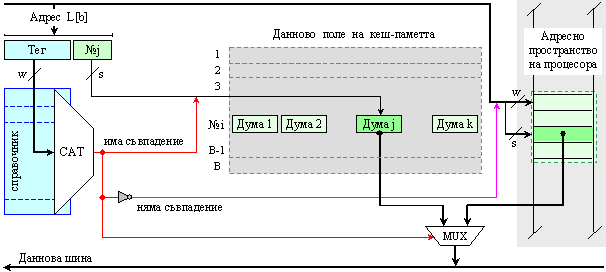
Фиг. 6.3.2.14. Логическа
структура на
кеш памет с
пълно асоциативно
съответствие
между адрес и
данни
Както
се вижда
младшата s-битова
част от
адреса се
използва за
адресиране
на думата в
кеш-линията,
а със старшата,
в качеството
ѝ на тег, се
извършва
асоциативното
търсене в
справочника.
Резултатът,
като
кеш-попадение
или
кеш-пропуск,
се формира от
схемата за
асоциативно
търсене САТ.
В схемата,
ако при
кеш-попадение
се осигури
достъп до
блок №i, ще бъде
прочетена
дума №j.
Силно опростената логическа структура на кеш памет с пълна асоциация е представена на фигура 6.3.2.15.
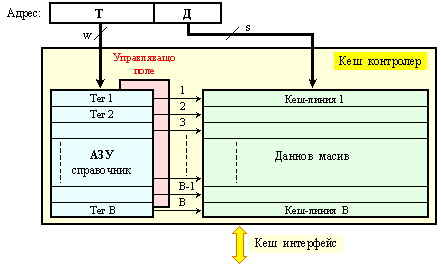
Фиг. 6.3.2.15. Структура
с пълно
асоциативно
съответствие
Всички функции на кеш паметта са заложени в кеш-контролера. За тяхното реализиране се използва информацията, съдържаща се в асоциативната част, от която излизат сигналите, осигуряващи достъп до данните. Контролерът поддържа интерфейсната връзка от една страна с процесора, а от друга страна с по-ниските нива в буферната памет. Както вече обяснихме, контролерът изпълнява различни асоциативни търсения и управлява трансфера на данните, при което използва информацията в справочника и в управляващото поле. Както вече отбелязахме, процесите в тази апаратна част не подлежат на контрол от страна на програмиста.
Тъй
като напълно
асоциативният
справочник с
голям обем
представлява
определено
затруднение,
конструкторите
търсят различни други
структурни
схеми с
облекчена
реализация. Най-често
асоциативното
запомнящо
устройство
(справочника)
се заменя с адресируемо
(с произволен
метод на
достъп), а
асоциативното
търсене се
реализира с
минимални допълнителни
средства.
Възможно
най-икономичната
реализация
се постига
чрез последователния
метод на
търсене с
помощта на един
външен
компаратор.
Опростената
логическа
структура на
такава кеш
памет е показана
на фигура 6.3.2.16.
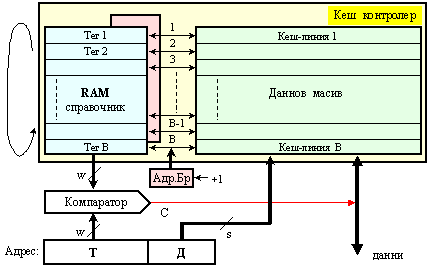
Фиг. 6.3.2.16. RAM-справочник
с
асоциативно
съответствие
(последователно
претърсване)
Както
се вижда,
справочникът
е RAM-памет
с
организация (размери) (B.w) и
неговите
клетки се
четат
последователно.
Адресът им се
формира от
адресния
брояч Адр.Бр
и съдържанието
му се подава
както в
справочника
така и в
данновия
масив.
Първото
срещнато
съвпадение,
открито от
компаратора,
преустановява
търсенето.
Кеш линията,
която бъде
отворена по
фиксирания
адрес,
изпълнява
основната
операция.
Представената
реализация се
нарича още
кеш памет с
еднократна
асоциация.
Ако след
претърсването
на всички
адреси (от 1 до
В) не се
получи
сигнал за
съвпадение,
това
означава, че
подаденият
тег не се
съдържа в
справочника,
т.е. че е
получен
кеш-пропуск.
Ще приведем някои типични стойности на параметрите на този тип кеш памет.
·
Размерът
на блока е 4
думи (16 [B]
или 128 [b]) ;
·
Обемът
на кеша е 16 [KiB],
така че
съдържа 1024
блока ;
·
Адресите
са 32-битови ;
·
Кешът
включва
валиден бит и
мръсен бит за
всеки блок ;
·
Индексът
на кеша е 10 [b] ;
·
За
адресиране
на байтовете
в блока се
използват 4[b] ;
·
Дължината
на тага е {32-(10+4)} = 18 [b] ;
Между
процесора и
кеша са
изградени
следните
връзки:
·
1-битов
сигнал за
четене или
запис ;
·
1-битов
сигнал за
валидност.
Показва дали
има кеш
операция или
не ;
·
32-битов
адрес ;
·
32-битови
данни от
процесора в
кеша ;
·
32-битови
данни от кеша
към
процесора ;
·
1-битов
сигнал за
готовност.
Показва, че
операцията с
кеширане е
завършена.
Интерфейсът
между
основната
памет и кеша има
същите
полета, както
между процесора
и кеша, с
изключение
на това, че
полетата за
данни тук са
широки 128 [b].
Допълнителната
ширина на
паметта
обикновено
се среща в
микропроцесорите
днес, които
трансферират
32-битови,
64-битови и
повече думи в
процесора,
докато DRAM
контролерът
често е 128 [b].
Съответствието
на дължината
на кеш блока спрямо
ширината на DRAM
шината, може
да опрости
дизайна.
Необходимите
сигнали са
следните:
·
1-битов
сигнал за
основна
операция
(четене или
запис) ;
·
1-битов
сигнал за
валидност,
който
показва дали
има операция
с памет или
не ;
·
32-битов
адрес ;
·
128-битови
данни от кеша
в паметта ;
·
128-битови
данни от
паметта в
кеша ;
·
1-битов
сигнал за
готовност,
показващ, че
операцията с
паметта е
завършена.
Имайте предвид, че интерфейсът към паметта не е с фиксиран брой цикли. Предполагаме че контролерът на паметта ще уведоми кеша чрез сигнала за готовност, когато четенето или записването в паметта е завършено.
По-долу
е представен
граф на
преходите на
кеш
контролера,
който
управлява
описаната структура.
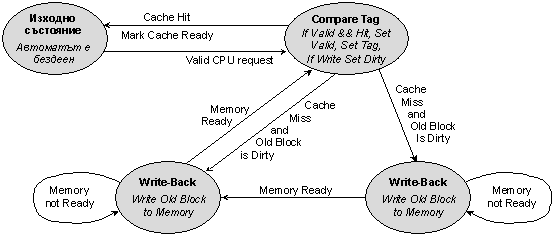
Фиг. 6.3.2.17. Граф
на преходите
на
управляващия
автомат
Изходно
състояние: в това
състояние
автоматът
очаква валидна
заявка за
четене или
запис от процесора,
което
премества FSM в
състояние за
сравняване
на таговете.
Сравняване
на таговете: в това
състояние се
извършва
последователното
сравнение, за
да се
установи
какъв сигнал
ще генерира
всеки блок
(съвпадение
или пропуск)
при исканото
четене или
запис. Индексната
част на
адреса
избира
съответния таг,
който ще се
сравнява. Ако
данните в кеш
блока,
посочени от
индексната
част на адреса,
са валидни и
тагът на
адреса
съответства на
тага на
блока, тогава
това е
съвпадение. Данните
се четат от
избрания
блок, или се
записват в
избрания
блок. След
това се вдига
сигналът за
готовност на
кеша. Ако
става въпрос
за запис,
мръсният бит
се установява
в 1. Имайте
предвид, че
записът също
така установява
валидния бит
и полето на
тага; макар
това да
изглежда
ненужно. Ако
има съвпадение
и блокът е
валиден, FSM се
връща в
неактивно
състояние.
Първият
пропуск актуализира
кеша и след
това
преминава
към състояние
на обратно
връщане, ако
блокът на това
място е
маркиран
като мръсен 1,
или към състояние
на
разпределение,
ако е 0.
Write-Back
(Обратен
запис):
в това
състояние
128-битовия
блок се
записва в
паметта, използвайки
адреса,
съставен от
индекса на
тага и кеша.
Оставаме в
това
състояние в
очакване на
сигнала за
готовност от
паметта. Когато
записът в
паметта
завърши, FSM
преминава в състояние
Allocate.
Allocate
(Разпределение): При
това
състояние новият
блок се
извлича от
паметта.
Оставаме в
това състояние
в очакване на
сигнала за
готовност на
паметта.
Когато
четенето на
паметта
приключи, FSM
преминава в
състояние за
сравняване на
етикета.
Въпреки че
бихме могли
да отидем в
ново
състояние, за
да завършим
операцията,
вместо да
използваме
повторно
състоянието
за сравнение
на етикета,
има доста припокриване,
включително
актуализиране
на
съответната
дума в блока,
ако достъпът
е бил запис.
Показаният простичък модел може лесно да бъде разширен с повече състояния, в опит да се подобри производителността. Например, състоянието за сравняване на етикета прави както сравнението, така и четенето или записването на кеш данни в един тактов цикъл. Докато сравнението и достъпът до кеша се извършват в отделни състояния, това може да позволи да се подобри времето на цикъла на тактовата честота. При друга оптимизация би могло да се добави буфер за запис, за да можем да запазим мръсния блок и след това да прочетем първо новия блок, така че процесорът да не трябва да чака два достъпа до паметта след мръсния пропуск. След това кешът ще записва мръсния блок от буфера за запис, докато процесорът работи с исканите данни.
Времето
за достъп в
тази
описваната
структура е
средно
пропорционално
на стойността
0,5*В.
Структурата
с пълна
асоциация е
възможно най-бързата,
а тази с
еднократна
асоциация, е
възможно най-бавната.
Ж) Функция с
директно
съответствие
Увеличаване
на скоростта
за търсене в
справочника
спрямо горе
описаната
структура,
може да се
постигне
чрез
използуване
на младшите
няколко
разряда от тега,
в качеството
им на
директен
адрес към
негова
клетка. Тази
идея се
реализира,
когато адресът,
подаван от
процесора, се
интерпретира
по
структурата
показана на
фигура 6.3.2.18.
Фиг. 6.3.2.18. Структурна
интерпретация
на адреса в
кеш с
директно
съответствие
Отделяйки
младшите r
бита от тега
и решавайки
те да бъдат
използвани
като директен
адрес на блок
в кеш
паметта, това
означава, че
последната
трябва задължително
да има
капацитет минимум
за
![]()
на брой
блока
(кеш-линии).
Засега ще
приемаме, че F<B (вижте уравнения
(6.3.2.1), (6.3.2.2), смисълът
на В
и
отношението B<<R).
Ще припомним,
че броят на
блоковете В в
кеш памети с
напълно
асоциативно
съответствие
няма
никаква
връзка със
структурирането
на адреса и
се избира от
конструктора.
В този случай
обаче
съществува
пряка връзка
между обема
на кеш
паметта и
структурата
на адреса,
която е
изразена
по-горе с (6.3.2.4).
Съответствието
между
подавания от
процесора
адрес на
данни и
тяхното
местоположение в
адресното
пространство
на паметта,
според
директната
функция, се
изразява
чрез схемата,
представена
по-долу на
фигура 6.3.2.19.
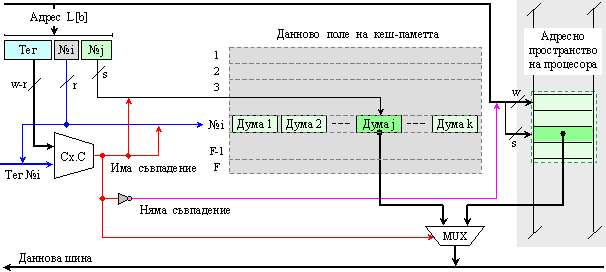
Фиг. 6.3.2.19. Логическа
структура на
кеш памет с
директно
съответствие
между адрес и
данни
При
показаната
структура на
адреса не се
извършва
асоциативно
търсене в целия
справочник
(било то
последователно
или
паралелно), а
директно се
отваря кеш линия
№i,
адресирана
чрез полето Б
на адреса. По
този начин се
извършва
едно
единствено
сравнение
между
старшата (w-r)-битова
част на
адреса, със
съответната
част на
съхраняващият
се в
кеш-линията тег.
Функцията за
съответствие
на кеш паметта
се нарича с
директно
съответствие.
Що се отнася
до основната
памет,
структурната
интерпретация
на адреса остава
тази, която
първоначално
бе определена
чрез фигура
6.3.2.4.
При
тази функция
на
съответствие,
схемата за
асоциативно
търсене САТ
от фигура 6.3.2.14,
се изражда в
един цифров
компаратор
(схема за сравнение
– Сх.С). При това
той е схемно
по-икономичен,
тъй като тук
се сравняват
две по-къси
комбинации – (w-r)-битови.
Практическата
реализация
на схемата с
директно
съответствие
е аналогична
на представената
на фигура 6.3.2.16,
само че тук
(фигура 6.3.2.18), благодарение
на
директното
адресиране на
кеш-линията,
последователното
асоциативно
търсене е
заменено с
многократно
по-бързото еднотактно
сравнение. По
този
показател
кеш паметта с
директно
съответствие
е сравнима
единствено с
кеш паметта с
пълна асоциация.
По-долу на
фигура 6.3.2.20 е
представена
структурната
схема на кеш
памет с
директна
еднократна
асоциация.
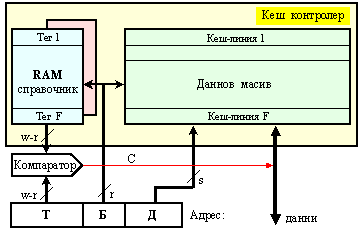
Фиг. 6.3.2.20. RAM-справочник
с директно
съответствие
За съжаление структурирането на адреса с цел въвеждане на директното адресиране, доведе до силно ограничаване на обема на кеш паметта – само F на брой кеш линии. Така влезе в сила неравенството F<B. Ето защо се търсят нови структурни решения, които ще позволят увеличаване на обема, при запазване на апаратната простота и високото бързодействие. Простото добавяне на кеш линии обаче не е решение, защото не е възможно – не го позволява директното адресиране. Именно заради това адресиране в справочника, увеличаването на обема на кеш паметта е възможно само на порции, кратни на числото (F.k). Визуално, казаното може да се илюстрира най-ясно със следната фигура 6.3.2.21:
Фиг. 6.3.2.21. Схема
за
увеличаване
обема на кеш
с директно
съответствие
Порциите,
с които се
увеличава
обема на кеш паметта
обикновено
се наричат секции
или още рамки,
набори.
Максималният
брой секции,
които могат
да се
реализират,
се определя
от дължината
на тега,
която е равна
на (w-r)
бита:
![]()
Разбира
се,
максималният
брой секции
не би могъл
да бъде
реализиран.
Това
означава кеш
паметта да
бъде с обема
на адресното
пространство,
т.е. да бъде пълно
копие на
цялата
оперативна
памет.
При
структуриране
на кеш
паметта
според горната
фигура 6.3.2.21,
след
подаване на
директния r-битов
адрес (№i)
на блок Б
към
справочника,
във всяка
секция ще се
отвори една
и съща
кеш-линия,
имаща този
номер. Естествено
това е
недостатък,
тъй като се губи
единствеността
от чистото
директно адресиране
и ако при
него се
изпълняваше
едно
единствено
сравнение на
два тега
(вижте по-горе
фигура 6.3.2.20),
сега в случая
на няколко
секции
(рамки)
трябва да се
избира
асоциативно
измежду
всички
отворени
кеш-линии.
Този тип кеш
памет в
литературата
има различни
имена. Според
нас,
най-подходящото
й наименование
на български
език, което
ние възприемаме
тук, следва
да бъде наборно-асоциативна или още секционно-асоциативна.
На
следващата
фигура 6.3.2.22 е
представена
опростената
логическа
структура на
наборно-асоциативна
кеш памет.
Когато
секциите, или
още рамките,
са две,
кеш паметта
се нарича още
с
двукратна
асоциация,
т.е. кеш памет
с два
паралелни
набора.
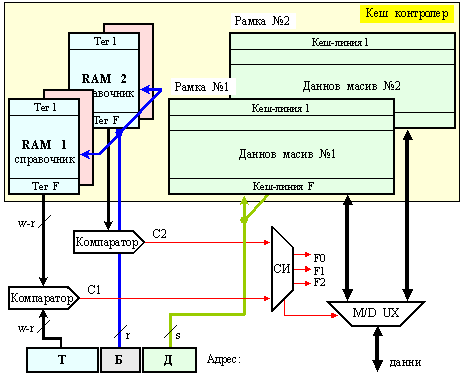
Фиг. 6.3.2.22. Логическа
структура на
кеш памет с
директно
съответствие
и с двукратна
асоциация (2-way)
За
да не се
загуби
основното
достойнство
на кеш
паметта с
директно
адресиране –
бързодействието,
едновременно
отворените
кеш-линии са
оборудвани
със
собствени
компаратори.
Във горната
фигура те са
два и
сравняват
прочетените
тегове
едновременно,
т.е.
извършват
пълно
асоциативно
търсене в
тази част. По
тази причина
структурата
се нарича
наборно-асоциативна.
Асоциативността
на този тип
структури в исторически
план е била
еднократна,
двукратна,
четирикратна,
осемкратна, а
към настоящия
момент е 16-кратна –
въпрос на
възможности
на
производствените
технологии.
Твърде е
възможно
този параметър
дори в близко
бъдеще да
претърпи
съществени
изменения.
От
казаното до
момента
става ясно,
че построяването
на
справочника
в кеш паметта
въз основа на
адресируемо
запомнящо
устройство (RAM
памет), ще
причини
изменения в
алгоритмите
за
изпълнение
на
операциите
четене и запис.
Тези
алгоритми
трябва да
бъдат съобразени
с механизма
за
адресиране в
справочника.
Така
например,
когато се
използува
директно
адресиране,
съществува само
един блок в
кеш паметта,
където може
да се помести
извлечената
от основната
памет
информация (имаме
предвид
показаната на фигура
6.3.2.20
структура).
Ако директно
адресираният
блок се окаже
зает, което
се
установява
от схемата за
сравнение, то
той следва да
бъде "изхвърлен"
в по-ниско
ниво или в
оперативната
памет. С
други думи,
проблемът
свързан с избора
на блок,
кандидат за
изхвърляне, тук
не
съществува.
Когато
обаче
справочникът
има по-висока
степен на
асоциация
(двукратна,
четирикратна
и т.н. до пълна),
то появата на
проблема за избор
е неизбежна и
той се решава
с помощта някоя
от вече
описаните стратегии
(вижте
по-горе букви
Д1,Д2,Д3,Д4,Д5). В
следващата
таблица са
показани
сравнителни
данни за
честотата на
кеш-пропуск
за два от
алгоритмите
за
изхвърляне:
Таблица
6.3.2.4 Относителна
част на
кеш-пропуските
при кеш-блок
с дължина 16 [B]
|
Асоциативност |
2-кратна |
4-кратна |
8-кратна |
|||
|
Обем на
кеша |
LRU |
RC |
LRU |
RC |
LRU |
RC |
|
16 [KiB] |
5,18% |
5,69% |
4,67% |
5,29% |
4,39% |
4,96% |
|
64 [KiB] |
1,88% |
2,01% |
1,54% |
1,66% |
1,39% |
1,53% |
|
256 [KiB] |
1,15% |
1,17% |
1,13% |
1,13% |
1,12% |
1,12% |
На следващата фигура е показана графично честотата на кеш пропуските в зависимост от нейния обем и степента на асоциативност. Така по-лесно могат да бъдат възприети текстовите пояснения.
Фиг. 6.3.2.23. Честота
на
пропуските в
кеш паметта
според обема
и кратността
на асоциация
С
нарастването
на обема на
кеш паметта,
относителното
подобрение
от
покачването
на асоциативността
се увеличава
леко. С повишаване
на обема на
кеш паметта
честотата на
пропуските
намалява.
Заедно с това
честотата на
пропуските
също
намалява, но
по-нататъшното
подобрение е
незначително
с увеличаване
на степента
на
асоциативност.
Потенциалните
недостатъци
на
асоциативността,
както
споменахме
по-рано, са
увеличените
разходи и
по-бавното
време за
достъп.
Методът за достъп в справочника допълнително е свързан и с метода за запис (едновременен или с прехвърляне), описан преди това.
Тук
ние приемаме,
че темата на
този раздел е
изчерпана.
Подробности,
свързани със
съвременните
фирмени
реализации,
техните предпочитания
и параметри
ние няма да
разглеждаме.
За тях
читателят
следва да
търси и
използва специализираните
фирмени
публикации
или фирмени
сайтове.
Следващият
раздел е:
6.3.2.1.
Архитектура
на кеш
паметта