Последната
актуализация
на този
раздел е от 2021
година.
6.3.2.1
Архитектура
на кеш
паметта
Проблемите със структурирането на паметта са занимавали конструкторите още в зората на компютърното производство. Става дума за това, за което вече говорихме – информационните потоци между паметта и процесора имат различен характер и те неминуемо се отразяват на архитектурния дизайн на кеш паметта. В съвременни условия се използват две структури:
·
Архитектура
с разделни
буферни
памети, известна
като “архитектура
Харвард” ;
·
Архитектура
с обща
буферна
памет,
известна
като “архитектура
Принстън”.
Наименованията "Харвард" и "Принстън" произлизат от научните колективи, които първоначално са ги разработвали. Така например, за първи път в машината MARK III (1950 година), разработена в Харвардския институт, е реализирана разделна буферна памет на два отделни високооборотни магнитни барабана с неподвижни магнитни глави. В същия период Принстънската научна група е разработвала буферна памет с общо предназначение, за което се е ръководила от препоръките на Джон фон Нойман.
В структурата на архитектура Харвард са реализирани две разделни кеш памети – за данни и за машинни команди, както илюстрира лявата рисунка във фигура 6.3.2.1.1. Разделното изграждане на буферната памет позволява да се извърши независимо оптимизиране на параметрите (обем и степен на асоциация). Разделните кеш памети позволяват лесно реализиране на паралелен (едновременен) достъп (за данни и за команди). В същото време, разделните кеш-памети внедряват своите недостатъци. Първият недостатък се изразява в това, че обмен между двата кеша е възможен само през оперативната памет. Вторият недостатък се състои в това, че не е възможно динамично изменение на обема на едната кеш-памет за сметка на другата, което е нещо естествено в кеш паметта с общо предназначение.
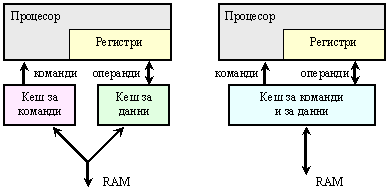
Фиг. 6.3.2.1.1. Видове
кеш
структури
Освен това дву-портовата статична кеш памет с голям обем е твърде скъпа, а едно-портовата не е в състояние да осигури паралелната обработка на няколко клетки, което води до досадни закъснения. Като достойнство на кеш паметта с общо предназначение (архитектура Принстън) може да се посочи високата ефективност на използване на целия обем. Балансировката на количеството команди в кеша спрямо това на данните се постига автоматично в хода на програмата. Във времето, когато процесорът извлича по-често команди, тяхната част се увеличава за сметка на данните, а когато се завърти цикъл и се работи с масиви, тогава делът на данните в кеша е по-голям. Този вид кеш силно облекчава реализацията на кеш-контролера, на кеш-интерфейса, от което се повишава бързодействието на алгоритмите за управление.
Така в крайна сметка съвременната кеш архитектура се е развила във вид на йерархична буферна система, в която влизат множество елементи като:
·
Кеш
памет от
първо ниво (L1 – Level
1) за машинни
команди ;
·
Кеш
памет от
първо ниво (L1)
за данни
(операнди) ;
·
Обща кеш
памет от
второ ниво (L2 – Level
2) ;
·
Обща кеш
памет от
трето ниво (L3 – Level
3) ;
·
Кеш
таблица за
преобразуване
адресите на
страници с
данни – TLB(1)-кеш
за данни ;
·
Кеш
таблица за
преобразуване
адресите на страници
с команди –
TLB-кеш за код ;
·
Буфери
за
подреждане – MOB(2)-read,
MOB-write, (Memory Order Buffer)
;
·
Буфери
за запис.
TLB(1)
- (Translation
Lookaside Buffer)
– таблица за
преобразуване
на адресите ;
MOB(2) - (Memory Order Buffer) –
буфер за
подреждане
на записите
(при четене и
при запис).
Тук в този
пункт, във
връзка с
горните, а
така също и с
някои от
следващите
по-долу
обяснения,
дължим извинение
на уважаемия
читател,
защото бяха използвани
и ще бъдат
използвани,
все още недефинирани
понятия. Това
разбира се ще
направим
малко
по-късно.
Предвид
на
изключителната
динамика в
развитието
на
описваните
тук
структури и
тяхната не
особено
подробна
фирмена
документация,
голяма част
от конкретиката,
която желаем,
остава
неизвестна. Цялата
съвкупност
от
елементите
на кеш системата
може да бъде
изразена в
обобщената
структура,
представена
по-долу, в
която са
употребени
още следните
означения:
- BIU (Bus Interfaces Unit) –
блок
интерфейси
със
системната
шина ;
- MIU (Memory Interfaces Unit)
– блок
интерфейси с
паметта.
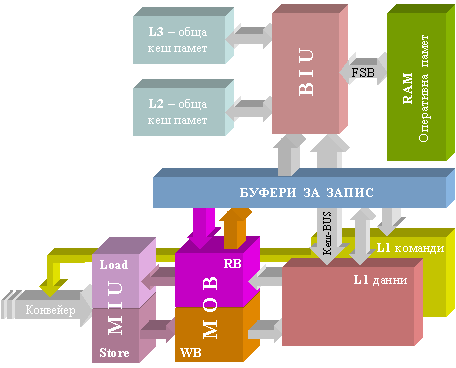
Фиг. 6.3.2.1.2. Обобщена
представа за
йерархична
кеш система
Буфери
за
подреждане
Вече беше изяснено в предидущия пункт, че буферите за подреждане (МОВ) на данните към/от оперативната памет са от тип опашки и че тяхната основна задача е да поемат излизащите от конвейерите готови резултати. Метафорично казано, тези буфери могат да се оприличат на чакалните на летищата, където данните се събират постепенно, групират се по съответното направление, указано в билетите им и когато настъпи удобният момент, вкупом отлитат по предназначението си.
Данните, намиращи се в МОВ са винаги достъпни за процесора. Обемът на тези буфери обаче не е голям и всяко тяхно запълване води до блокиране на конвейерите. По тази причина МОВ трябва да се разтоварва (дори и да не е запълнен напълно) при всяка създадена възможност. Тези буфери разполагат с необходимите схеми, които ги предупреждават при запълване на половина. Незабавното разтоварване може да протече по някой от следните три начина:
а) Ако обновената клетка се намира в кеш L1, тя се отправя директно към съответната кеш-линия, за което е необходим само един такт, през което време могат да бъдат обновени и други кеш-линии, чийто брой зависи от степента на асоциативност на кеш-паметта ;
б)
Ако
обновената
клетка не се
намира в кеш L1, при
наличие поне
на един
свободен
буфер за запис,
тя попада в
него. За това
е необходим
само един
такт, през
което време
могат да
бъдат
записани
няколко
клетки. Максималният
брой
едновременно
записвани клетки
се определя
от броя на
портовете
към буферите
за запис,
които има
съответният
модел
процесор ;
в)
Ако
обновената
клетка не се намира
в кеш L1, и няма
свободни
буфери за запис,
започва
процедура по
асоциативно
търсене на
кандидат за
изхвърляне
(която вече изяснихме
в предидущия
пункт) и след
като тя завърши
данните се
записват в
избрана кеш-линия
на L1. Ясно е, че
тази
ситуация е най-тежката,
тъй като при
нея
закъснението
може да бъде
стотици, дори
хиляди,
тактове.
Кеш на
първо ниво (L1)
1. L1 кеш за
данни
Кеш
паметта на
първо ниво (L1),
във връзка с
архитектурата от
тип Харвард,
се реализира
върху
кристалната
подложка на
процесора
като
дву-портова
статична
памет. Тя представлява
две отделни
банки
свръхоперативна
памет, всяка
от които има
свой собствен
кеш-контролер.
Обикновено в
техническото
описание на
процесора е
указан
сумарният
обем на тази
кеш памет, но
той се дели
на две части –
за данни и за
команди, при
това тези две
части не са
равни. В
процесорите Pentium
4, на Intel кешът
за данни е 8[KB]. С
този малък
обем конструкторите
постигат
много ниска
латентност (закъснение)
– не повече от 2
такта. Кеш-линията
е с дължина 32[B]=256[b].
Тъй като кеш
паметта за
данни е
2-портова, това
означава, че
целият обем е
разделен на 2 масива
от по 4[KB], което
позволява
едновременното
изпълнение
на две
обръщения. От
казаното
току що
следва, че
тази кеш
памет има 128 реда.
Кеш паметта
за данни в
процесор Pentium 4
е с 4-кратна
асоциация,
което
означава, че
броят на
асоциативните
редове във
всяка секция
е 32 на брой.
2. L1 кеш за
команди
В
процесор Pentium 4
на Intel, кеш
паметта за
команди е
реализирана
по нова
концепция. В
същност тя не
съдържа
самите
машинни
команди, а
техните микропрограми.
Всичко това
произтича от
факта, че кеш
паметта за
команди
трябва да
съдържа
предварително
извлечени от
оперативната
памет команди
на текущата
програма,
които да бъдат
буферирани и
подредени в
опашката, с
която се
захранват
изчислителните
конвейери на
процесора.
При това
буфериране
следва да се
осъществяват
онези
алгоритми, които
бяха
подробно
описани в
предидущия пункт 6.3.1
“Опашки и
буфериране
на машинни
команди”.
Тук ще
припомним, че
процесор Pentium 4
например, има
20 стъпкова
конвейерна
организация
и тази
дълбока
конвейеризация
създава
голямо
закъснение
при грешно
предсказване
на
алгоритмичен
преход.
Вероятността
този
недостатък
да се
реализира на
практика се
намалява
според Intel по
два начина. Първият
е свързан с
възможно
най-оптимизирания
алгоритъм за
предсказване
на преходите.
Вторият е
свързан с
новата
концепция за
кеширане на
машинните
команди,
която Intel
нарича “кеширане
с
проследяване”
– “Execution Trace Cache” (ETC).
Характерното
за нея е това,
че
кеширането е
непосредствено
обвързано с
предварителното
извличане и
дешифриране
на машинните
команди. В
този процесор,
още с
пристигането
на машинните
команди от
по-ниските
нива те се
“дешифрират”,
т.е. се
заместват
(подменят) с
техните
микропрограми,
които в
крайна
сметка се
записват
фактически в
кеша L1 за
команди
Микропрограмите
(четете глава
7-ма,
“Организация
на
управлението”)
се
характеризират
с това, че за
разлика от машинните
програми,
техният
“текст” е
съставен от
микрокоманди,
чиято дължина
е
еднаква (вижте книга [1],
глава 8,
таблица 8.2),
което е едно
много
улесняващо
реализацията
на тази кеш
памет
обстоятелство.
Едно
от главните
достойнства
на тази технология
(Trace Cache) се състои
още в това, че
отстранява
повторното
дешифриране
на машинните
команди. Ще
припомним, че
първото е на
етапа на
предварителния
анализ, който
се прави при
предварителното
извличане на
командите.
Така като
цяло се
постига изключително
равномерен
темп на
захранване на
конвейерите
и
вероятността
от блокиране
се намалява.
За съжаление
логическата
структура и
алгоритмите
за
функциониране
на тази кеш
памет не са
публикувани.
Известно е
само, че тя
побира около
12000 mOP’s
(както се
изразява Intel).
Според нас
това са не
микрооперации,
а по-скоро микрокоманди.
Ще припомним
дадените тук
в глава 2
определения,
според които
под микрооперация
разбираме
микродействие
от тип превключване
на логическа
схема
(логически
възел),
причинявано
в даден такт
от
управляващ
сигнал, а под микрокоманда
разбираме
съвкупността
от едновременно
подаваните в
даден такт,
към
структурата
на дадено
устройство,
управляващи
сигнали. Следвайки
тази логика и
това
познание, не
е толкова
трудно да се
прозре какъв
е строежът на
тази кеш
памет и как
тя се запълва
със съдържание.
В
логическата
структура на
всяка от кеш
паметите L1 се
съдържат още
TLB-буфери за
асоциативно
преобразуване
на адресите
на
страниците с
данни и на
страниците с
команди. За
тези буфери
са отделени
фиксирани
кеш-линии и
техният обем
“официално” е
изключен от
обема на кеш
паметта. С други
думи
реалният
обем на кеш
паметите е по-голям
от обявения.
За тези
буфери ще
стане дума
отново в
следващите
пунктове.
Буфери
за запис
Наборът буфери за запис е част от интерфейсната система, свързваща кристала на интегралната схема с външната апаратура. Много от характеристиките на тези буфери вече бяха изяснени. Така или иначе те отлагат за известно време фактическото записване в кеш паметта и/или в основната памет, осъществявайки тази операция във връзка с освобождаването на кеш-контролера, на вътрешната или на системната шини. Така тези буфери ликвидират цяла поредица ситуационни задръжки, като по този начин способстват за повишаване на общата производителност. В процесор Pentium се съдържат 3 такива 32 байтови буфери за запис, всеки от които поддържа пълна кеш-линия, като подпомага (подсигурява) записите не кеш-линиите във кеша L1 за данни. За всяка една от причините за запис в кеш паметта L1 е предвиден един такъв 32 байтов буфер. Първият от тези буфери поема кеш-линията, която трябва да бъде изхвърлена след настъпване на кеш-пропуск, или когато се налага обновена кеш-линия да актуализира копието в оперативната памет. Вторият буфер съхранява модифицираната кеш-линия, която е достигната в цикъла от външни запитвания (заявки). Третият буфер прави същото, но за вътрешния цикъл на запитване (заявки). Вътрешните и външните запитвания са част от протокола MESI, който ще разгледаме в следващия пункт. Ако няколко буфера за запис съдържат данни за запис, тогава те се разтоварват при следния приоритетен ред:
· Буфер за запис за външни запитвания ;
· Буфер за запис за вътрешни запитвания ;
· Буфер за запис при размяна на кеш-линии.
Интерфейси
към паметта
Блокът на интерфейсите с паметта (MIU) представлява едно от изпълнителните устройства на процесора. Функционално се състои от две устройства:
1. Устройство
за четене от
паметта ;
2. Устройство
за запис в
паметта.
Устройството
за четене от
паметта е
свързано с
буферите за
запис и с кеш
паметта на първо
ниво. Ако
заявената
клетка
присъства поне
в едно от
тези
устройства, нейното
прочитане
отнема само
един такт. Устройството
за запис в
паметта е
свързано с буфера
за
подреждане
на записите (Reorder
Buffer - ROB Wb),
разгледан
по-горе.
Интерфейси
към шината
Блокът на интерфейсите със системната шина (BIU) представлява единственото звено, свързващо процесорът с външния свят. Тук се стича цялата информация избутвана от буферите за запис, от кеш паметта на първо ниво, тук пристигат заявките за изпреварващото извличане на данни и машинни команди. От другата страна са кешовете L2 и L3, както и оперативната памет. Ясно е, че от повратливостта на BIU зависи бързодействието на системата като цяло. Поради голямата ширина на данновата кеш-шина (256 бита) зареждането на кеш-линиите се подсигурява с буфери за пълнене (зареждане). Тези буфери са два и имат дължина 32 байта. Единият е предназначен за данновия кеш, другият – за командния кеш. Пълненето на тези буфери става чрез последователно мултиплексиране на порции от по 8 байта (64 бита), а разтоварването им в кеша става за един такт. Читателят следва да разбира, както по много поводи в тази книга сме отбелязвали, че тези технически параметри, както и много други, които по принуда цитираме, еволюират с времето.
Кеш
на второ ниво
(L2)
Кеш
паметта на
второ ниво (L2)
конструкторите
реализират
вече върху
кристалната
подложка на
процесора.
Еднокристалната
реализация (On
Die) притежава
максимално
бързодействие
– разстоянията
са малки,
връзката с BIU е
непосредствена
и кеша работи
с тактовата
честота на
процесора, а
ширината на
шината
достига до 256
бита. В
процесор Pentium 4
тази кеш
памет има 8-кратна
асоциация,
достига обем
от 2[MB].
Интегрираната
върху
кристалната
подложка кеш
памет от
второ ниво
увеличава
значително
площта на
кристала,
което води до
рязко
снижение на
процента на
годните схеми
и увеличава
цената, но
конкуренцията
е жестока и
всички
съвременни
процесори
имат тази
реализация.
На
следващата
картинка е показана
незакрит
кристал на
процесор Pentium 4
на Intel с кеш
памет на
второ ниво L2 с
обем 2 [MB] -
в дясната
половина на
фотографията.
Вижда се
ясно, че този
обем заема почти
50% от площта на
кристала.

Широката даннова шина на кеша L2 също не е безпроблемно решение. Налага се въвеждане на мултиплексори, тъй като основната дължина на думата в процесора е по-малка. Внасяното закъснение от мултиплексирането се компенсира до известна степен, когато се прави между по-горните нива в кеш системата. И не на последно място, съществуват проблеми с организацията на корекцията на грешки при предаване на данни в системи с широка памет.
Кеш
паметта от
второ ниво се
реализира
като
едно-портова
конвейерна
статична
памет (BSRAM) (вижте
§4.2.1). Тъй като
едно-портовата
памет е
значително
по-евтина, обемът
на L2 кеша е
относително
голям – от няколко
стотин
килобайта до
няколко
мегабайта.
Скоростта на
достъп в тази
памет е по-ниска
от тази на L1, но
е значително
по-висока от тази
на
оперативната
памет.
Високата
производителност
се дължи още
на “широкия”
обмен –
минималният
обем данни,
който се предава
между
кешовете L1 и L2 е
съдържанието
на цяла
кеш-линия, за
четенето на
която от кеша
L2 са
необходими
средно 5
такта
(формулата на
BSRAM паметта е 2-1-1-1).
Така, ако
синхронизацията
на кеш
паметта на
второ ниво е
с честота ½ от
тази на
процесора, то
обръщението
към една
клетка във
нея ще отнеме
10 такта.
Разбира се
тази
стойност
може да се
съкрати.
Например в
процесори,
предназначени
за
изграждане
на сървърни
станции, кеш
паметта на
второ ниво
работи с честотата
на ядрото на
процесора и
обикновено
нейната
кеш-шина е с
учетворена
ширина (4.64=256[b]),
благодарение
на което
пакетният
цикъл на
обмен
завършва
само за един
такт. Разбира
се цената на
такива
системи
съответно е
висока.
Локална
кеш-шина
С
цел увеличение
на
производителността
на системата,
кеш L2
комуникира с
BIU чрез своя
собствена локална
кеш-шина – DIB (Dual Independent
Bus) (двойна
независима
шина).
Предвид на
оптималните
си
геометрични
параметри,
тази локална
шина работи
на по-висока
честота в
сравнение с
тази на
системната
шина. Ширината
на локалната
кеш-шина
еволюира
заедно с
процесорите
от 64 бита до 256
бита. Така
прехвърлянето
на 32 байтова
кеш-линия от L2
в L1 може да стане
за един такт.
Производителността
достига 48[GB/s].
Архитектурата
с двойна
независима
кеш-шина
снижава значително
натоварването
на
системната
шина FSB (Front Side Bus),
тъй като
голяма част
от
обръщенията
към паметта
се
обработват
локално.
Според някои
изследвания,
в
едно-процесорни
системи, системната
шина поема 10%
от натоварването,
а останалите
90% се поемат от локалната
шина. Дори в
4-процесорни
системи натоварването
на
системната
шина не превишава
60% от
пропускателната
й възможност.
Тези факти
обаче трябва
да се
интерпретират
правилно. Не
бива да се
забравя за
голямата
латентност
на
оперативната
памет, т.е. голяма
част от
времето на
системната
шина (повече
от
половината)
се изразява в
очакване
изпълнението
на заявките
за обръщение.
Ето защо тук
в схемите на
паметта също
вече се
прилагат
техниките за
изпреварващо
извличане,
което
позволява
максималното
“изцеждане”
на
пропускателните
възможности
на системната
шина.
Системната
шина FSB (Front Side Bus)
свърза
процесора с
чипсета. За
процесора са
характерни
две тактови
честоти –
вътрешна и
външна.
Вътрешната е
тази, която е
основна
негова
характеристика.
Външната
честота е
тази, с която
се
синхронизира
системната
шина.
Честотите,
които все още
са “работни”,
са 100, 133[MHz]. Все
по-новите
системи
процесор-чипсет
използват
честитите 200, 266[MHz].
В литературата
се споменава
още термина “ефективна
FSB честота”.
Наименованието
идва от това,
че процесорната
шина на Pentium 4
предава 4
бита за един
тактов импулс.
Това
предаване се
нарича Quad Pumped.
Ефективната
честота е
равна на
4-кратното увеличение
на основната
честота. Така
например, ако
основната
честота е 266[MHz],
то ефективната
FSB честота ще
бъде 266.4=1066[MHz]. Нека
си припомним
принципа за
удвояване на
честотата
при
динамичните
памети DDR2
(вижте фигури
4.2.2.21, 4.2.2.22, 4.2.2.27 и
коментарите,
свързани с
тях). Удвояването
(умножаването)
на тактовите
честоти,
което се
нарича
технология Xn-Prefetch, е
подробно
изяснено в продължението
на раздел 4.2.2 от
глава 4-та в
тази книга.
Ефективната
честота 1066[MHz] по
този начин
съответства
на тактовата
честота 266[MHz] на
интерфейса
на
динамичната
памет DDR2-533
(вижте таблица
4.2.2.1). Счита се,
че
отношението
1:1 на
физическите
синхронизиращи
честоти на
системната
шина и на
динамичната
памет е
идеалното за
работата на
системата.
Кеш на
трето ниво (L3)
И
накрая
няколко думи
за кеш
паметта на
трето ниво (L3).
Това ниво не
е типично,
може да се
каже даже
спорно. Такава
памет
производителите
слагат обикновено
на дънните
платки.
Обемът на
тази кеш
памет за
някои
процесори
достига до 8[MB].
Управлява се
от чипсета на
системата.
Архитектурата,
типична за AMD,
е от тип
изключваща (exclusive).
В
процесор Itanium
(архитектура
IA-64) кеш паметта
на трето ниво
е опакована
заедно с
процесора
върху долната
страна на
картриджа.
Кеша L3 на този
процесор е с 4-кратна
асоциация и
има обем 4[MB]. В
най-новите
процесори на Intel
и на AMD обаче и
кеш паметта
на това ниво
е реализирана
върху
кристалната
подложка на
самия процесор.
Обемът й е 2[MB].
Процесорът
Pentium 4 Extreme Edition (P4-EE) на Intel има
кеш памет на
трето ниво (L3) с
обем 2[MB], която е
реализирана
върху
кристалната
подложка и се
синхронизира
с пълната
честота на
процесора. За
кеш паметта
на този модел
е известно,
че тя е с
включваща (inclusive)
архитектура,
с 8-кратна
асоциация и
има 64-битова
шина.
Употребената
част от кристала
на
интегралната
схема за
реализация
на L3 кеша при
този
процесор е
изключително
скъпа. Ако
стандартният
Pentium 4 Northwood съдържа
около 55
милиона
транзистори,
добавяйки
още 2048[KB] като
кеш L3, Intel е
увеличил
броя на
транзисторите
до впечатляващите
167 милиона!
Това разбира
се е само едно
начало.
Съвременните
технологии
днес ни правят
свидетели на
още
по-впечатляващи
стойности на
тези
параметри, но
не това е същественото
тук.
Архитектурата на кеш паметта от второ и трето ниво може да бъде характеризирана още така:
А) Включваща
(inclusive)
архитектура
Кеш
паметта на
второ ниво,
построена по inclusive-архитектурата,
винаги
дублира
съдържанието
на кеш
паметта на
първо ниво и
поради това
съвместният
ефективен
обем на двете
нива е равен
на съответната
разлика L2-L1.
Ще разгледаме следната ситуация: кеш паметта на второ ниво е изцяло запълнена и процесорът прави опит да зареди още една клетка. След като стане ясно, че кешът е пълен (събитие кеш-пропуск), кеш-контролерът изпълнява алгоритъма за избор на кандидат за изхвърляне. При това най-напред се търси кеш-линия, която не е била обновявана, тъй като в противен случай ще се наложи изхвърляне в оперативната памет, за което е необходимо много време. Да припомним, че необновяваната кеш-линия при кеш-пропуск просто се припокрива от новата кеш-линия.
След
запълване на
избраната
кеш-линия,
кешът L2
предава
получените
от
оперативната
памет данни
към кеш L1. Ако
кешът L1 също е
запълнен, в
отговор на
подадената
заявка той
изпълнява
аналогичния
алгоритъм, за
да се
освободи от
избрана
кеш-линия.
Така,
в резултат на
тези
действия,
трансферираните
данни
присъстват
във всички
йерархични
нива на
запомнящата
система,
което не се
преценява
като
достойнство.
Между впрочем,
практически
типичните
съвременни процесори
са построени
именно по
включващата
архитектура.
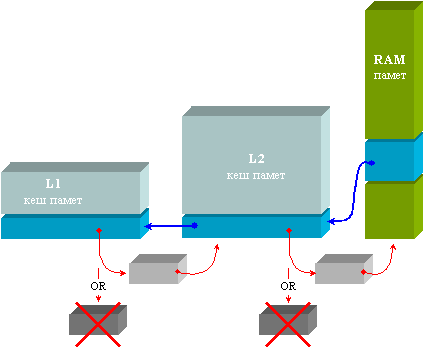
Фиг. 6.3.2.1.3. Схема
на движение
при
включваща
(отляво) и при
изключваща
(отдясно)
архитектура
на кеш паметта
Б) Изключваща
(exclusive)
архитектура
Подсистемата
на кеш паметта,
чийто строеж
се определя
като изключваща
архитектура,
не съхранява
излишни
копия на
блокове, поради
което
ефективният
обем е равен
на сумата от
капацитетите
по цялата
йерархия.
Кеш
паметта на
първо ниво
никога не
унищожава
кеш-линиите
ако не
достига място.
Даже ако
данните не са
били
обновявани –
те се
препращат в
нужния ред в
кеш паметта
на второ
ниво, в
мястото от
което е извадена
кеш-линията,
която се
зарежда на
тяхно място в
кеш паметта
на първо
ниво.
По-просто изказано
кеш-контролерите
на двете нива
разменят
местата на
две кеш-линии
– едната
слиза
по-надолу, а
другата се
изкачва по-нагоре
в йерархията.
Така
използването
на кеш
паметта е
много
ефективно.
Към настоящия
момент само
фирмата AMD
прилага тази
архитектура
и то само в
някои модели.
Схемите за движение на данните при двете архитектури са показани по-горе на фигура 6.3.2.1.3.
Intel Core i7
По-долу
ще
представим
тази масова
към този момент
архитектура.
Процесорът i7
съдържа 4 ядра
и поддържа
архитектура
с набор от
команди x86-64,
което е 64-битово
разширение
на
архитектурата
80x86. В този
раздел ще се
фокусираме
върху
дизайна на
запомнящата
система от
гледна точка
на едно ядро.
За
ефективност
на
многопроцесорните
системи,
включително
и
многоядрените
вече писахме
в
предходните
глави на тази
книга.
Всяко
ядро в i7 може
да изпълнява
до четири инструкции
i80x86 за
тактов цикъл,
използвайки
многопроблемен,
динамично
планиран,
16-степенен
конвейер. i7
може също
така да
поддържа
едновременно
до две нишки
на процесор ,
използвайки
техниката за
многозадачност
(multithreading). През 2010
година
най-бързият i7
имаше
тактова честота
3,3 [GHz], което дава
пикова
скорост за
изпълнение
на команди от
13,2 милиарда в
секунда или
над 50
милиарда
команди в
секунда за
четириядрената
структура.
i7
може да поддържа
до три канала
с паметта,
всеки от
които се
състои от
отделен
набор от DIMM
модули с всеки
от които може
да изпълнява
паралелен обмен.
Използвайки
например
динамична
памет от тип
DDR3-1066 (DIMM PC8500), i7 има
максимална
честотна
лента на
паметта от малко
над 25 [GiB/s].
i7
използва
48-битови
виртуални
адреси и
36-битови
физически
адреси, което
позволява
максимална
физическа
памет от 36 [GiB]. В
управлението
на паметта се
използва с
двустепенен
TLB, чиито
обобщени
параметри са
следните.
|
Параметри |
TLB - команди |
TLB - данни |
TLB
второ ниво |
|
Капацитет |
128 |
64 |
512 |
|
Асоциативност |
4-степенна |
4-степенна |
4-степенна |
|
Алгоритъм
за
заместване |
Псевдо
LRU |
Псевдо
LRU |
Псевдо
LRU |
|
Латентност |
1 цикъл |
1
цикъл |
6
цикъла |
|
Несъвпадение |
7
цикъла |
7
цикъла |
Стотици
цикли за
достъп до
таблицата
на
страниците |
Структурата
на i7 има
отделни TLB за
команди и за
данни от
първо ниво, и
двете
подкрепени
от общ TLB на
второ ниво. TLB
от първо ниво
поддържат
стандартния
размер на
страниците
от 4 [KiB],
както и имат
ограничен
брой записи на
големи
страници от
по 2 до 4 [MiB],
като само 4 [KiB] страници
се поддържат
във TLB на второ
ниво. Ще
припомним, че
функциите на
тези буфери отговарят
на
справочник,
който има
всяка кеш
памет според
структурата
от фигура
6.3.2.2, която
може да
видите в предидущия
раздел.
Следващата
таблица
обобщава
йерархията на
кеш паметта
на i7. Кешовете
от първо ниво
са виртуално
индексирани
и маркирани
физически, докато
кешовете L2 и L3
са физически
индексирани.
И в трите
нива на кеша
се използва
алгоритъмът
за обратно
записване (write-back) при
размер на
блока от 64
байта.
Кешовете L1 и L2 са
налични и
отделни за
всяко ядро,
докато кешът
L3 се споделя
между ядрата
на целия чип
и е общо 2 [MiB].
Кешовете и на
трите нива са
без
блокировка и
позволяват
множество
неизпълнени
записи. За кеш L1 се
използва
обединяващ
буфер за
запис, който
съхранява
данни в
случай, че
линията (блокът)
не присъства
в L1, когато е
записан. (т.е.
пропуск при
запис в L1 не
води до
разпределяне
на реда.). Кеш L3
включва L1 и L2 -
изследваме
това
свойство
по-подробно,
когато
обясняваме многопроцесорните
кешове.
Заместването
е с вариант
на псевдо LRU. В L3
блокът за
заместване
винаги се
избира с
най-малкия
номер, чийто
бит за достъп
е изключен.
Това не е
съвсем случаен
избор, но е
лесно за
реализация.
|
Параметри |
L1 |
L2 |
L3 |
|
Капацитет |
32 [KiB] за
команди 32 [KiB] за
данни |
256
[KiB] |
2 [MiB] на
ядро |
|
Асоциативност |
4-степенна |
8-степенна |
16-степенна |
|
Алгоритъм
за
заместване |
Псевдо
LRU |
Псевдо
LRU |
Псевдо
LRU, но с
алгоритъм
за
подреждане
на избора |
|
Закъснение
при достъп |
4 конвейеризирани
цикъла |
10
цикъла |
35
цикъла |
Във фигура 6.3.2.1.4 по-долу с жълти номера е означена последователността на достъп до йерархичните нива на паметта. Първо процесорът извиква команда от кеша с командите. Индексът на кеша се изчислява както следва
![]()
или
той е 7 бита.
Страничната
рамка на
адреса на
инструкцията
(36=48-12 бита) се
изпраща към TLB за
команди
(стъпка 1 в
чертежа от
фигура 6.3.2.1.4). В
същото време,
7 битовият
индекс от
виртуалния
адрес, се
изпраща в
кеша на
командите
(стъпка 2).
7-битовият
индекс плюс
допълнителни
2 бита за
отместването
на блока (за
да се изберат
подходящите
16 байта)
формира
адреса за
извличане на
командата.
Забележете,
че за кеша с команди,
който има
четири
степенна
асоциативност,
са
необходими 13
бита за кеш
адреса: 7 бита за
индексиране
на кеша плюс 6
бита блоково
отместване
за 64-байтовия
блок.
Размерът на страницата
е 4 [KiB]=212,
което
означава, че 1
бит от
индекса на
кеша трябва
да идва от
виртуалния
адрес. Това
използване
на 1 бит
виртуален
адрес
означава, че
съответният
блок
всъщност
може да бъде
на две различни
места в кеша,
тъй като
съответният физически
адрес може да
има 0 или 1 в
това местоположение.
За командите
това не е
проблем, тъй
като дори ако
командата се
появи в кеша
на две
различни
места, двете
версии
трябва да са
еднакви. Ако
такова
дублиране или
псевдоними
на данни е
разрешено,
кешът трябва
да бъде
проверен при
подмяна на
страницата,
което е рядко
събитие.
Рядкото използване
на замърсени
страници
може да премахне
възможността
за тези
псевдоними. Ако
виртуалните
страници с
четен адрес
са съпоставени
с физически
страници с
четен адрес
(и същото за
нечетните
страници),
тогава тези
псевдоними
никога не
могат да
възникнат,
защото битът
с нисък ред
във виртуалния
и физическия
номер на
страницата
ще бъде идентичен.
Достъпът до TLB за команди е за намиране на съвпадение между адреса и валиден запис в таблицата на страниците (PTE) (стъпки 3 и 4). В допълнение към преобразованието на адреса, TLB проверява дали PTE изисква този достъп да доведе до изключение поради нарушение на достъпа.
При пропуск в TLB за команди следва обръщение към TLB на L2 кеша. Той съдържа 512 PTE с размер на страниците от 4 [KiB] и е с 4-степенна асоциативност. Необходими са два тактови цикъла, за да заредите TLB на кеша L1 от TLB на кеша L2. Ако в TLB-L2 се получи пропуск, се използва хардуерен алгоритъм за преглед на таблицата на страниците и актуализиране на TLB записа. В най-лошия случай страницата не е в паметта и операционната система я получава от диска. Тъй като милиони команди могат да се изпълнят по време на грешка при обръщение към страницата, операционната система ще замени процеса с друг процес, ако такъв чака да стартира. В противен случай, ако TLB не генерира изключение, достъпът до кеша на командите продължава.
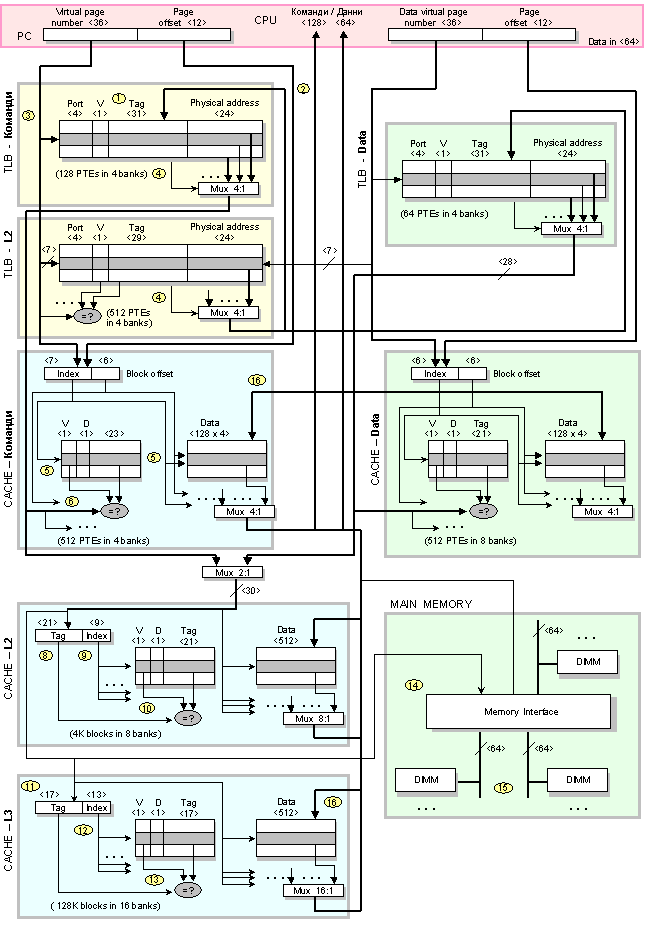
Фиг. 6.3.2.1.4. Архитектура
на
запомнящата
система на Intel Core i7
Индексното поле на адреса се изпраща до всичките четири банки на кеша за команди (стъпка 5). Маркерът за кеш на командите е с дължина 36-7-6=23 бита. 7 бита индекс и 6 бита отместване на блока, или се получава 23 бита. Четирите маркера и битовете за валидност се сравняват с физическия кадър на страница в TLB за команди (стъпка 6). Тъй като процесорът i7 очаква 16 байта при всяко извличане на команди, допълнителните 2 бита се използват от 6-битовото отместване на блока, за да изберат подходящите 16 байта. Следователно 7+2 или 9 бита се използват за изпращане на 16 байта команди към процесора. Кешът L1 се конвейеризира, а латентността на посещението е 4 тактови цикъла (стъпка 7). Ако се получи пропуск, той отива в кеша от второ ниво.
Както бе споменато по-рано, кешът с команди е виртуално адресиран и физически посочен. Тъй като кешовете от второ ниво са физически адресирани, адресът на физическата страница от TLB се съставя с отместването на страницата, за да се формира адрес за достъп до кеша L2. Индексът за L2 е
![]()
Така
30-битовият
блоков адрес
(36-битов
физически
адрес минус
6-битово
отместване
на блока) е разделен
на 21-битов таг
(етикет) и
9-битов индекс
(стъпка 8). За
пореден път
индексът и
етикетът се
изпращат до
всичките
осем банки от
обединения L2
кеш (стъпка 9),
които се
претърсват
паралелно.
Ако някой етикет
съвпадне и е
валиден
(стъпка 10), той
връща блока в
последователен
ред след
първоначалната
латентност
от 10 цикъла,
със скорост
от 8 байта за
тактов цикъл.
Ако кешът L2
пропусне,
кешът L3 е
достъпен. За
четири-ядрен
i7, в който
кешът L3
има обем
от 8 [MiB],
размерът на
индекса е
![]()
13-битовият
индекс
(стъпка 11) се
изпраща до
всички 16
банки на кеш L3
(стъпка 12). Тагът
за кеш L3, който
е с дължина 36-(13+6)=17
бита, се сравнява
с физическия
адрес от TLB
(стъпка 13). Ако се
получи
съвпадение,
блокът се
връща след
първоначално
закъснение
със скорост
от 16 байта на
такт и се
поставя в L1 и L3.
Ако в кеша L3 се
получи
пропуск, се
стартира
достъп до
основната
памет.
Ако
командата не
е намерена в
кеш L3, контролерът
на паметта на
чипа трябва
да получи блока
от основната
памет. i7
има три
64-битови
канала към
паметта,
които могат
да действат
като един
192-битов канал.
Тъй като има
само един
контролер на
паметта, то един
и същ адрес
се изпраща и
на двата
канала
(стъпка 14). Широки
трансфери се
случват,
когато и двата
канала имат
идентични DIMM
модули. Всеки
канал
поддържа до
четири DDR DIMM
(стъпка 15). Когато
данните се
върнат, те се
поставят в кеш
L3 и кеш L1 (стъпка
16),
защото кеш L3 е
в
архитектура
inclusive, т.е.
включваща
(вижте фигура
6.3.2.1.3 по-горе).
Общата
латентност
на пропуска
на командите,
който се
обслужва от основната
памет, е
приблизително
35 цикъла на
процесора,
плюс
латентността
на DRAM за критичните
команди. За
едно-банкова
DDR1600 SDRAM и процесор с
честота 3.3 [GHz]
латентността
на DRAM е около 35 [ns] или 100 тактови
цикъла до
първите 16
байта, което
води до общa загуба от
135 тактови
цикъла. Контролерът
на паметта
запълва
останалата
част от
64-байтовия
кеш блок със
скорост от 16
байта за
тактовия
цикъл на
паметта, което
отнема още 15 [ns], или
общо 45
тактови цикъла.
Тъй
като кешът от
второ ниво е
кеш с обратно
записване (write-back),
всеки
пропуск може
да доведе до
запис на стар
блок обратно
в паметта. i7
има буфер за
до 10 записа, в
който се
записват
обратно
мръсните кеш
редове,
когато
следващото
ниво в кеша не
се използва
за четене.
Буферът за
запис се
следи при
всеки
пропуск, за
да се открие
дали в него
съществува
търсеният
ред на кеша.
Ако е така,
пропускът се
попълва от
буфера.
Подобен
буфер се
използва
между
кешовете L1 и L2.
Ако
тази
първоначална
команда е
заредена,
адресът на
данните се
изпраща към
кеша за данни
и TLB данни,
което
прилича много
на достъп до
кеша за
команди с
една ключова
разлика.
Кешът за
данни от
първо ниво е с
8-степенна
асоциативност,
което
означава, че
индексът е с
дължина 6
бита (срещу 7
за кеша с
команди) и
адресът,
използван за
достъп до
кеша, е
същият като
отместването
на
страницата.
Следователно
псевдонимите
в кеша за
данни не са
притеснителни.
Да
предположим,
че командата
е за запис (Store) вместо
зареждане (Load). Когато
командата е
за запис, се
извършва
търсене в
кеша на данни
точно както
при команда
зареждане.
Пропускът
води до
поставяне на
блока в буфера
за запис, тъй
като кешът L1
не разпределя
блока при
пропуск при
запис. При
съвпадение
записът не
актуализира
кеша L1 (или L2) и
се отлага за
по-късно, тъй
като се знае,
че е
неспекулативен.
През това
време
записът се
нарежда в
опашката,
което е част
от механизма
за
подреждане и
управление
на процесора.
i7
също така
поддържа
предварително
извличане за
L1 и L2 от
следващото ниво
в йерархията.
В повечето
случаи
предварително
извлечената
линия е
просто следващият
блок в кеша.
Чрез
предварително
извличане
само за L1 и L2 се
избягват
скъпо
струващи
излишни
извличания
от паметта.
Следващият
раздел е:
6.3.2.1.1.
Изчистване
на кеш
паметите