Този
раздел е нов.
Създаден е
през 2022 година.
6.3.2.1.1.
Изчистване
на кеш
паметите
Съществува
мнение, че
определени
операции
причиняват
“изчистване“
на кеш
паметта на процесора.
Това
изглежда
илюстрира
много често
срещана
заблуда за
това как
работят
кешовете на
процесора и
как
подсистемата
на кеша
взаимодейства
с
изпълнителните
ядра. Ето
защо се
налага да
бъде
обяснена функцията
“CPU caches fulfil" и как
ядрата, които
изпълняват
командите, съставящи
нашите
програми,
взаимодействат
с тях. Ще
направим
това като
пример с един
от
известните Intel
x86 сървърни
процесори.
Други
процесори
използват
подобни
техники за
постигане на
същите цели.
Повечето
съвременни
системи,
които изпълняват
нашите
програми, са
многопроцесорни
системи със
споделена
памет. Системата
със
споделена
памет има
един общ ресурс
памет, до
която се
осъществява
достъп от 2
или повече
независими
ядра на
процесора.
Латентността (закъснението)
на основната
памет при
обмен е силно
променлива
от 10[ns] до 100[ns].
В рамките на 100[ns]
е възможно 3.0[GHz]
CPU да обработи
до 1200 машинни
команди.
Всяко ядро от
типа на “Sandy Bridge”
може да
изтегля
паралелно до
4 команди на цикъл
(IPC).
Процесорите
използват
кеш подсистеми,
за да тушират
тази
латентност и
да им позволят
да
упражняват
огромния си
капацитет за
обработка на
команди.
Някои от тези
кешове са
малки, много
бързи и локални
за всяко
ядро; други
са по-бавни,
по-големи и
споделени
между ядрата.
Заедно с
регистрите и
основната
памет, тези
кешове
съставляват
непостоянната
йерархична
система на
паметта.
Следващия
път, когато
разработвате
важен алгоритъм,
опитайте да
помислите, че
пропускането
на кеша е
загубена
възможност
да изпълните
бързо около 500
машинни
команди! Това
е за система
с един гнездо
(single-socket system), при
система с
няколко
гнезда (multi-socket system)
можете
ефективно да
удвоите
пропуснатата
възможност,
тъй като
паметта
изисква кръстосани
връзки между
гнездата.
Йерархия
на паметта
За
сървърите от
клас Sandy Bridge-E, известни
след 2012 година,
които
споменахме по-горе,
йерархията
на паметта
може да бъде
илюстрирана
по следния
начин:
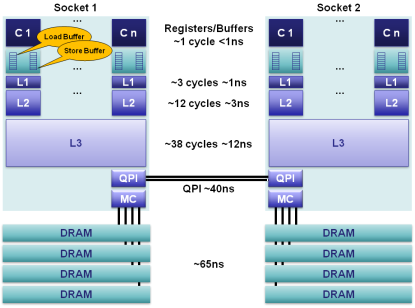
На
върха в
йерархията
са
изобразени
ядрата С1/Сn на
всеки от
процесорите.
Всяко
ядро има FIFO-буферна
памет за
изпреварващо
извлечените
и подготвени
за
изпълнение
машинни команди,
както и FIFO-буфер за
запис на
данни в
паметта. Тези
два буфера
захранват
ядрата с
команди и
данни. Под
тези два
структурни
елемента са
изобразени
трите нива на
кеш паметта
L1, L2 и L3.
Обърнете
внимание на
това, че L3 кешът е общ
за всички
ядра в един
процесор. Показан
е още броят
на тактовите
цикли за достъп
до
регистрите и
до клетките в
отделните
нива на кеш
паметта.
Връзката
на
процесорите
с
оперативната
памет се
осъществява
с помощта на
шина, наречена
Intel QuickPath Interconnect (QPI).
Това е
последователна
кеш-кохерентна
шина от тип
точка-точка.
Разработена
е от Intel
в отговор
на AMD
шината,
известна под
наименованието
Hyper Transport, описана
от нас в раздел
5.5.3.3 на тази
книга.
След
2008 г. шината QuickPath
заменя
по-рано
използваната
FSB (Front Side Bus), която
обслужва
трансфера на
данни между процесора
и северния
мост върху
дънните платки.
Всяка връзка
на шината QPI
включва
двойка
еднопосочни
канали, всеки
от които
физически е
реализиран
от 20 диференциални
двойки
проводници.
Данните се
предават във
вид на
пакети.
Пропускателната
способност
на един канал
е от 4,8 до 6,4[GT/s] (гигатранзакции).
Една
транзакция
съдържа 16
бита данни,
което прави 19,2[GiB/s] сумарна
пропускателна
скорост в
едно направление.
Диференциалната
връзка е
пояснена в раздел 5.5.3.1 на тази
книга (вижте фигура
5.5.3.1.10).
По-надолу
в йерархията
са показани
локалната
памет на
всеки
процесор (MC, Memory Core) и основната
DRAM памет с
възможните 4
канала.
Ще
разгледаме
отделните
нива в
йерархията
на паметта.
1. Регистри
Във
всяко ядро
има отделни
регистрови
набори за
съхранение
на цели числа
(160 на брой),
както и за
числа с
плаваща
запетая (144 на
брой). Тези
регистри са
достъпни в
рамките на
един цикъл и
представляват
най-бързата
памет,
налична в
процесорите.
Компилаторите
разпределят
локалните
променливи и
техните
функционални
аргументи в
тези
регистри.
Компилаторите
разпределят
подмножество
от регистри,
познати като
архитектурни
регистри,
след което
хардуерът ги
разширява,
докато
изпълнява
инструкциите
паралелно и
извън реда им
в програмния
текст.
Проблемите
на току що засегнатия
ред за
изпълнение
на машинните
команди са
подробно
обсъдени в глава 5 на тази
книга.
Компилаторите
са наясно със
способността
за
извънредно
(изпреварващо)
и паралелно изпълнение
за даден
процесор и
подреждат
потоци от
команди и
разпределянето
им върху
съответните
регистри.
Когато
хипернишката
е разрешена,
тези
регистри се
споделят
между
съвместно
разположените
хипернишки ;
2. Буфери за
подреждане (MOB – memory
ordering buffers)
MOB
съдържа 64
регистъра
за зареждане
(въвеждане) (load) и
36 регистъра
за запис (store).
Тези
буфери се
използват за
проследяване
на
операциите
по време на
прехвърляне,
докато чакат
в кеш
подсистемата,
тъй като инструкциите
се
изпълняват
извън реда.
Буферът за
запис
представлява
напълно
асоциативна
опашка, в
която може да
се търси за
съдържащи се
в опашката
команди за запис,
очакващи
обслужване
от кeш L1. Тези буфери
позволяват
на нашите
бързи процесори
да работят
без
блокиране,
докато данните
се
прехвърлят
към и от
подсистемата
на кеша.
Когато
процесорът
изпълнява
четене или запис,
те могат да
се върнат
извън реда. MOB
се използва
за
разграничаване
на
зареждането и
съхранението
при
постигане на
съответствие
с
публикувания
модел на
паметта. Машинните
команди за
четене и
запис могат
да се
изпълняват
извън реда на
зареждане в
буферите и
могат да се
върнат извън
реда в подсистемата
на кеша ;
3.
Кеш
памет от
първо ниво – L1
L1 е
локална кеш
памет на
ядрото, която
е разделена
на две
отделни
части - 32[KiB] кеш за данни
и 32[KiB] кеш за
команди. Времето
за достъп е 3
цикъла и може
да бъде скрито,
тъй като
командите се
предават в
ядрото като
данни, които
вече са в L1
кеша.
4.
Кеш
памет от
второ ниво – L2
Кешът L2
е локална
памет на
ядрото,
предназначена
да буферира
обмена между
L1 и общата (споделена)
L3 кеш. Кешът L2 е
с размер 256[KiB] и действа
като
ефективна
опашка за
достъп между
L1 и L3. L2 съдържа
както данни,
така и команди.
Латентността
за достъп до L2
е 12 цикъла.
5.
Кеш
памет от
трето ниво – L3
Кешът L3
се споделя
между всички
ядра в рамките
на един
сокет. L3 е
разделен на 2[MiB]-ви сегменти,
всеки
свързан към
мрежа с пръстеновидна
шина на
гнездото.
Всяко ядро
също е
свързано към
тази
пръстеновидна
шина. Адресите
се хешират
към сегменти
за по-голяма
пропускателна
способност.
Закъснението
може да бъде
до 38 цикъла в
зависимост
от размера на
кеша.
Размерът на
кеша може да
бъде до 20[MiB] в
зависимост
от броя на
сегментите,
като всеки
допълнителен
преход около
пръстена отнема
допълнителен
цикъл. Кешът L3
включва всички
данни на L1 и L2 за
всяко ядро на
един и същи
сокет. Това
включване, с
цената на
пространство,
позволява на
L3 кеша да прихваща
заявки, като
по този начин
премахва
тежестта от
частните
локални L1 и L2
кешове на
ядрото.
6.
Основна
(оперативна)
памет
DRAM
каналите са
свързани към
всеки сокет
със средна
латентност
от около 65[ns] за
локален
достъп на
сокета при
пълен пропуск
на кеша. Това
обаче е
изключително
променливо,
като е много
по-малко за
последващи достъпи
до колони в
същия буфер
на ред, до значително
повече,
когато
ефектите на
опашката и
циклите на
опресняване
на паметта са
в конфликт. 4
канала на
паметта са
агрегирани заедно
на всеки
сокет за
пропускателна
способност и
за скриване
на
латентността
чрез
конвейериране
на
независимите
канали на
паметта.
7.
NUMA (non-uniform
memory access) - неравномерен
достъп до
паметта
В
сървър с
няколко
гнезда имаме
нееднороден
достъп до
паметта. Той
е
нееднороден,
тъй като
необходимата
памет може да
е на отдалечен
сокет, който
изисква
допълнителни
40[ns] за скачване
през QPI шината. Sandy
Bridge е голяма стъпка
напред за
системи с 2
гнезда по
отношение на Westmere
и Nehalem. С Sandy Bridge
границата на
QPI е повишена
от 6.4[GT/s] на 8.0[GT/s] и две ленти
могат да
бъдат
обединени,
като по този
начин се
елиминира
тясното
място на
предишните
системи. В
допълнение, QPI
връзката
вече може да
препраща
заявки за
предварително
извличане,
които предишните
поколения не
са могли.
8.
Кратност
на
асоциативността
Кешовете
са ефективно
базирани на
хардуер хеш
таблици. Хеш
функцията
обикновено е
просто
маскиране на
някои битове
от нисък
порядък за
индексиране
на кеша. Хеш
таблиците се
нуждаят от
някои
средства за
справяне с
сблъсък за
същия слот.
Кратността
на
асоциативност
е броят на
слотовете,
които могат
да се
използват за
съхраняване
на
хешираната
версия на
адреса.
Наличието на
повече нива
на
асоциативност
е компромис
между
съхранението
на повече
данни спрямо
изискванията
за мощност и
време за търсене
по всеки от
начините. За Sandy
Bridge кешовете L1 и
L2 са с 8-кратна
асоциативност,
а L3 е с 12-кратна
асоциативност.
Архитектурното
изграждане
на
асоциативността
е подробно
изяснено в раздел 6.3.2 на
тази книга (вижте фигура
6.3.2.22).
Кохерентност
на кеша
Тъй
като някои
кешове са
локални за
ядрата, ние
се нуждаем от
средства за
поддържането
им
кохерентни,
така че
всички ядра
да имат
съвместим
(съответстващ)
вид спрямо
съдържанието
на основната
памет. Въпросът
с
кохерентността
на паметта е
подробно
изяснен в раздел
6.3.2.2 на тази
книга.
Подсистемата
на кеша се
счита за
"източник на
истината" за
масовите
системи. Ако
паметта се
извлича от
кеша, тя
никога не е
остаряла; кешът
е основното
копие, когато
данните съществуват
както в кеша,
така и в
основната памет.
Този стил на
управление
на паметта е
известен
като обратно
записване,
при което данните
в кеша се
записват
обратно в основната
памет само
когато
кеш-фреймът е
изхвърлен,
тъй като нов
фрейм заема
неговото място.
Кешът x86
работи върху
блокове
данни с размер
64 байта,
известни
като
кеш-линия.
Обръщаме
внимание на
факта, че
данновата
шина на
паметта е 64
битова. Други
процесори
могат да
използват
различен
размер за кеш-линията.
По-големият
размер на кеш
линията
намалява
ефективната
латентност
за сметка на
увеличените
изисквания
за честотна
лента.
За
да поддържа
кеша
кохерентни,
кеш контролерът
проследява
състоянието
на всеки кеш-ред
като намиращ
се в едно
състояние от краен
брой други
такива.
Протоколът,
който Intel
използва за
това, е MESIF, AMD
използва
вариант, известен
като MOESI.
Съгласно
протокола MESIF
всеки кеш-ред
може да бъде
в 1 от 5-те
следващи
състояния:
1. Modified (Променен):
Показва, че
кеш-редът е
замърсен и
трябва да
бъде записан
обратно в
паметта на
по-късен
етап. Когато
се запише
обратно в
основната
памет,
състоянието
преминава в
състояние Exclusive
(специално) ;
2. Exclusive (Специален):
Показва, че
кеш-линията
се държи
изключително
и че
съответства
на основната
памет. Когато
в нея се
запише ново
съдържание,
състоянието
ѝ отново преминава
в Modified. За
постигане на
това
състояние се
изпраща съобщението
Read-For-Ownership (RFO), което
включва
четене плюс
невалидно
излъчване
към всички
други копия;
3. Shared (Споделен):
Показва, че
съдържанието
на кеш-реда, е
чисто копие
на
съответния в
основната
памет фрейм ;
4. Invalid
(Невалиден):
Указва
неизползван
кеш-ред ;
5. Forward (Напред):
Показва
специализирана
версия на
споделеното
състояние,
т.е. това е определеният
кеш, който
трябва да
отговаря на други
кешове в NUMA
система.
За преминаване от едно състояние в друго се изпращат поредица от съобщения между кешовете. Преди Nehalem за Intel и Opteron за AMD, този трафик за кохерентност на кеша между сокетите трябваше да споделя шината на паметта, което значително ограничава мащабируемостта. Сега трафикът на контролера на паметта е на отделна шина. Шините QPI на Intel и HyperTransport на AMD се използват за поддържане на кохерентността на кеша между гнездата.
Кеш контролерът съществува като модул във всеки L3 кеш сегмент, който е свързан към мрежата с пръстеновидна шина на гнездото. Всяко ядро, както и L3 кеш сегментът, QPI контролерът, контролерът на паметта и интегрираната графична подсистема са свързани към тази пръстеновидна шина. Пръстенът се състои от 4 независими ленти за: заявки, подслушване, потвърждение и 32-байта даннова шина. Кешът L3 е включващ, тъй като всеки кеш-ред, съхраняван в L1 или L2 кеша, се съдържа, т.е. се съхранява в L3. Това осигурява бърза идентификация на ядрото, съдържащо модифицирана линия, когато се следи за промени. Кеш контролерът за L3 сегмент следи кое ядро може да има модифицирана версия на кеш-линия. Ако ядрото иска да прочете някаква памет, а нея я няма в Споделено, в Специално или в Променено състояние; след това трябва да направи отчитане на шината на пръстена. След това търсеното или ще бъде прочетено от основната памет, ако не е в подсистемите на кеша, или ще бъде прочетено от L3, ако е чист, или ще бъде подслушани от друго ядро, ако са модифицирани. Във всеки случай четенето никога няма да върне остаряло копие от подсистемата на кеша.
Паралелно
програмиране
Ако нашите кешове винаги са последователни, тогава защо се тревожим за видимостта, когато пишем паралелни програми? Това е така, защото в рамките на нашите ядра, в стремежа им към все по-висока производителност, модификациите на данните могат да се появят извън ред за други нишки. Има 2 основни причини за това.
Първо, нашите компилатори могат да генерират програми, които съхраняват променливи в регистри за относително дълги периоди от време, поради съображения за производителност, например, променливи, използвани многократно в рамките на цикъл. Ако имаме нужда тези променливи да бъдат видими в ядрата, тогава актуализациите не трябва да бъдат разпределени в регистъра. Това се постига в езика C чрез квалифициране на променлива от тип "volatile"., т.е. стойността на променливата е изменяща се и следва да остава в паметта. Внимавайте, че в езиците C/C++ типът volatile е недостатъчен, за да се укаже на компилатора да не пренарежда други команди. За това имате нужда от подобни "огради/бариери" за памет.
Вторият основен проблем с подреждането, за който трябва да сме наясно, е, че нишката може да запише променлива и после, ако я прочете малко след това, може да види стойността ѝ в своя буфер за запис, която стойност може да е по-стара от най-новата стойност в под-кешовата система. Това никога не е проблем за алгоритми, следващи принципа на “Single Writer - Единичен записвач (SW)". Нека поясним:
Когато се опитвате да изградите силно мащабируема система, най-голямото ограничение за това е, че множество Writers се борят за всеки елемент от данни или ресурс. Разбира се, алгоритмите могат да бъдат лоши, но нека приемем, че имат разумна нотация за BigO. Много хора просто приемат наличието на множество Writers като норма. Има много изследвания в компютърните науки за управление на това твърдение, което се свежда до 2 основни подхода.
· Единият е да се осигури взаимно изключване на претендирания ресурс, докато се извършва мутацията ;
· Другият е да се предприеме оптимистична стратегия за размяна на промените, ако основният ресурс не се е променил, докато сте създали новото копие.
Ако имате
система,
която може да
спазва
принципа на SW,
тогава всеки
контекст на
изпълнение
може да
прекара
цялото си
време и
ресурси в
обработка на
логиката за
нейната
същностна цел,
а не да губи
цикли и
ресурси за
преодоляване
на проблема
със спора.
Можете също
така да увеличавате
Writers без
ограничение,
докато
хардуерът не
се насити.
Предимство е
и това, че
когато се
работи върху
архитектури,
като ix86/ix64,
където на
хардуерно
ниво има
модел на паметта,
при който
операциите Load/Store на
паметта
запазват
реда. Тогава
не са
необходими
бариери в
паметта,
стига да се
придържате
строго към
принципа SW.
За
по-задълбочено
изучаване на
този проблем
препоръчваме
на Читателя
да се отнесе
към
специализираната
литература.
Конкурентно
програмиране
Вторият основен проблем с подреждането, за който споменахме по-горе, е, че нишката може да запише променлива и после, ако я прочете малко след това, може да види стойността ѝ в своя буфер за запис, която стойност може да е по-стара от най-новата стойност в под-кешовата система. Това никога не е проблем за алгоритми, следващи принципа на “Single Writer - Единичен записвач (SW)".
Буферът за запис (Store buffer) също така позволява на командата за зареждане (Load) да изпревари по-стар запис, създавайки по този начин проблем на подобни алгоритми за заключване, като тези на Dekker и Peterson. За да се преодолеят тези проблеми, нишката не трябва да позволява на последователно зареждане да изпревари последователното съхранение на стойността в локалния буфера за запис. Това може да се постигне чрез издаване на команда за ограждане (укриване). Записването на изменяща се променлива в Java, освен че никога не се разпределя в регистъра, е придружено от команда за ограждане. Командата за укриване в ix86 има значително въздействие върху производителността, като предотвратява напредъка на издаващата нишка, докато буферът на магазина не се източи. Оградите в други процесори могат да имат по-ефективни реализации, които просто поставят маркер в буфера за запис като границата за търсене.
Ако искате да осигурите подреждане на паметта в нишките на Java, когато следвате принципа на единичния запис (SW), и да избегнете оградата на буфера, можете да направите това с помощта на метода jucAtomic(Int|Long|Reference).lazySet(), вместо да задавате изменяща се променлива.
Заблудата
Връщайки се към заблудата за "прочистване на кеша", която споменахме в началото като част от паралелен алгоритъм. Можем спокойно да кажем, че никога не “промиваме“ кеша на процесора в рамките на нашите потребителски програми. Източникът на тази заблуда е необходимостта от промиване, маркиране или източване на буфера за запис до определена точка за някои класове паралелни алгоритми, така че най-новата стойност да може да се наблюдава при последваща операция за зареждане. За това ни е необходима ограда (укриване) за подреждане на паметта, а не изчистване на кеша.
Друг
възможен
източник на
тази заблуда
е, че
кешовете L1 или TLB може
да се наложи
да бъдат
прочистени въз
основа на
политика за
индексиране
на адреси при
превключване
на контекст. ARM,
преди ARMv6, не
използва
етикети на
адресното
пространство
за TLB записи,
което
изисква
целият кеш L1
да бъде
прочистен
при
превключване
на контекст.
Много
процесори
изискват
кешът на
командите L1
да бъде
прочистен по
подобни
причини. В
много случаи
това е просто
защото не се
изисква
кешовете на
командите да
се поддържат
последователни.
Изводът е, че
превключването
на контекста
е скъпо и
малко извън
темата, така
че в допълнение
към
замърсяването
на L2 кеша на,
превключването
на контекста
може също да
накара TLB и/или L1
кешовете да
изискват
прочистване.
Процесорите
Intel x86 изискват
само TLB flush при
превключвател
на контекста.
Следващият
раздел е:
6.3.2.1.2.
Етапи в
протокола за
обслужване
на
първичната кеш
памет