Последната
актуализация
на този
раздел е от 2021
година.
6.3.2.3
Съображения
за оптимално
използване
на системи с
кеш памет
В този кратък раздел ще представим проблемна според нас информация, която има отношение към разгледаните по-рано тук структури, алгоритми, разбирания и норми на поведение. Разбираме ясно, че следващите въпроси, на които ще се спрем, не влизат в нашите компетенции и не са обект на нашето внимание, но плавният преход към тях изисква нашето внимание точно тук в последователността от теми.
Много програмисти, особено начинаещите, в повечето случаи са напълно удовлетворени от работещия софтуер, който създават и традиционните тестове, с които го проверяват за работоспособност. Те рядко прибягват до средствата за усъвършенстване на този полуготов резултат и в много редки случаи не пристъпват към неговото оптимизиране и усъвършенстване в смисъла дори на традиционните критерии. Може би подобен стил на работа е оправдан за приложения без претенции, особено в случаи, когато грубата сила стои зад тях (имаме предвид грубата сила на хардуера). И все пак много компилатори се стремят да предоставят възможност за оптимизация на програмния код. Като имаме предвид темповете на еволюция на хардуера, темповете, с които го следват някои програмни среди, е крайно бавен. В същото време, обща грешка, която програмистите правят, е да оптимизират дадена програма като имат предвид, че всички обръщения към данните попадат директно в кеш-паметта. При това те обикновено забравят факта, че несполука (кеш-пропуск) в кеш паметта може да коства толкова машинни цикли, колкото цяла дузина или повече машинни команди. Най-обикновеният пример, когато се появява този проблем, е при съхраняване на булеви стойности като цели числа или символи, вместо като битове. Тази организация им позволява да обработват данните с по-малко команди, но от друга страна увеличава броя на необходимите в кеш-паметта блокове (и следователно броя на потенциалните кеш-пропуски) с множител 8, 32 или дори 64, когато архитектура е 64-битова. Съхраняването на данни small integers (малки цели числа) като short words, т.е. като къси думи, може да доведе до повишаване на производителността на системата поне с 10 процента.
Кеш
съобразени
данни
Когато
данните не се
вместват в
кеш паметта,
местоположението
им придобива
голяма
важност.
Когато
обръщението
към кеш
паметта е
неуспешно,
блокът, съдържащ
исканата
дума се
зарежда от
оперативната
памет.
Затова,
атрибути на
данни, до които
се прави
достъп
едновременно,
трябва да се
съхраняват
близко едни
до други. Например,
ако
приложната
програма
използува два
атрибута на
данните за
всеки
работник, тогава
много
по-добре е да
се
съхраняват
тези атрибути
заедно
в някаква
структура,
отколкото в
два отделни
масива.
Кеш
съобразени
дължини
Една
последна
оптимизация
на местоположението
се прилага,
когато се
прави достъп
до големи
количества
данни, които
не могат да
се вместят в
кеш паметта.
Например, ако
атрибутите
на данните до
които се
прави достъп,
са 6-байтови
записи, а
дължината на
кеш-линията е
8 байта,
тогава
половината
записи (т.е.
два от
четири) ще се
разположат в две
кеш-линии.
Това
означава, че
обръщението
към кеш
паметта с цел
получаване
на достъп до
даден запис,
често ще бъде
неуспешно. Чрез
допълване
на записите с
празни
полета до 8
байта и
подреждането
им на 8-байтовата
граница,
броят на
неуспешните
обръщения
към кеш
паметта за
всеки запис
се намалява
до един.
Отчитане на
асоциативността
Два адреса, които се различават само по частта за етикет (т.е. по старшите разряди), ще се разпределят в един и същи блок. Когато многократно се иска достъп до два "спорещи" адреса и броят на конфликтите надвишава степента на асоциативност на кеш паметта, тогава един и същи адрес многократно ще генерира несполучливи опити за достъп до кеш паметта. Така “спорещите‘ обръщения правят този адрес трудно достъпен. Към тази ситуация е особено предразположена кеш паметта с еднократна асоциация, защото дори относително случайните обръщения могат да генерират това събитие. Това е причината, поради която кеш паметта с двукратна асоциация може да се окаже толкова по-ефективна, колкото кеш паметта с еднократна асоциация, но с двойно по-голям обем.
Конфликтите
се превръщат
в още
по-голям проблем,
когато се
иска достъп
до паметта по
еднотипен
начин. Това
често се
случва, когато
се прави
достъп до
елементи от
масив по една
и съща
колона. Езикът
за
програмиране
Си
например,
специфицира,
че
елементите
на масивите
трябва да се
разполагат
ред по ред. Така
елементите А[3,0] и A[3,1] са
съседни в
паметта,
докато A[3,0] и A[4,0]
са разделени
от цял ред елементи
на същия
масив А,
което
измерено в
байтове е
произведението
от броя на
колоните и
броя на
байтовете на
един елемент.
Ако размерът
на кеш
паметта е
точно кратно
на
разстоянието
между два елемента,
които са
последователни
по отношение
на достъпа
(според
алгоритъма
за обработка
в
потребителската
програма),
тогава
елементите
често ще се
изобразяват
в малък брой
кеш-рамки.
Още по-лошо е
положението,
когато
разстоянието
между
елементите с
последователен
достъп е
по-голямо от
размера на
кеш паметта и
е точно
кратно на
този размер.
В този
случай, всеки
елемент от
колонката на
масива ще се
изобразява в
една и съща
рамка.
Ефектът е
същият, както
ако кеш
паметта е с
4-кратна
асоциация и
съдържа само
4 блока,
вместо
например 1024.
Най-доброто
решение в
такива случаи
е, когато
програмите
извършват
достъп до
данните,
които са
разположени
в последователни
адреси. За
целта
програмистът
следва да
използува
подходящо
деклариране и
подходящо
въвеждане на
данните. Ако
това не
зависи от
него, то би
следвало да
промени алгоритъма
за обработка.
За да намали
опасността
от конфликти
при достъп и
да повиши ефективността
на
програмата
си за дадения
компютър,
програмистът
трябва
да избягва
оразмеряване
на масиви с
числа, които
са степени на
двойката
(особено
по-високите
степени на
двойката).
Това той може
да постигне
чрез фиктивно
допълване на
броя на
елементите на
редовете на
масивите с
няколко
"празни"
елемента.
Нуждата от кеш ориентирано програмиране е най-голяма там, където наказанието от кеш-пропуск е най-тежко. Например при обработка на големи масиви от данни (в бази от данни), сложни изчислителни процедури (3D графики) или критични процеси, работещи в реално време (разпознаване на образи). За да се оцени ползата от една кешова оптимизация, трябва да се прецени дали тя е въобще възможна, и дали една инвестицията в по-бърз микропроцесор няма да се окаже по-изгоден вариант. Така отново засягаме фактора “груба сила”. Затова и самата нужда от кеш ориентирано програмиране си остава повече или по-малко специфична.
Елементи на
кеш ориентирано
програмиране
Принципът
на локалното
действие по
един сравнително
добър начин
съответства
на мисловната
дейност на
човека и
следователно
и на една
голяма част
от
програмите,
писани от
него.
Различните
програмни
езици също така
до различна
степен
следват
принципа на
локалността.
Процедурни
езици като Assembler
и Cи
предлагат
по-големи
възможности
за кеш ориентирано
програмиране
отколкото
абстрактните
обектно-ориентирани
езици като C++
и Java.
Проблемът се
състои в
несъвършените
компилатори,
които не
могат да
вникнат в
контекста на
програмния
код, където
са вложени
голяма част
от идеите на
програмиста.
Затова ако
програмистът
не е запознат
със смисъла
на програмния
език и
слабостите
на неговия
компилатор, при
превръщането
на
програмата в
машинен код
безвъзвратно
се губи част
от нейната
локалност.
Това пък от
своя страна
води до една по-бавна
програма.
Ето кратки съвети и основни принципи за кеш ефективно програмиране, подкрепени с примери:
За
експлоатиране
принципа на
временната
локалност,
концентрирайте
операциите
върху даден
обект във
възможно
най-малък
блок от
програмния
код. Ако
трябва да
извършите
някакви
изчисления
върху даден
вектор,
особено ако
той е голям,
направете ги
всичките на
същото място.
В следващия
пример се
умножават
елементите от
вектора a[k] със
съответните
елементи от b[k],
след което
към а[k] се
прибавят
елементите
от вектора c[k].
Това може да
бъде
организирано
с два цикъла
по следния
начин:
for (k = 0;
k < size; k++)
a[k] = a[k] * b[k] ;
for (k = 0;
k < size; k++)
a[k] = a[k] + c[k] ;
По-изгодно е обаче да извършим всички операции за даден елемент наведнъж и след това да преминем към следващия. По този начин даден елемент от a[k] се зарежда в кеша само веднъж, което спестява допълнителното зареждане от горната версия на текста:
for (k = 0;
k < size; k++)
a[k]
= a[k] * b[k] + c[k] ;
Така този вариант на текста се приема за оптимизиран, тъй като с него се постига ускорение средно от 9% на различни работни станции.
За експлоатиране принципа на пространствената локалност, , достъпът до даннови структури от паметта трябва да бъде извършван с възможно най-малка стъпка. В идеалния случай в хода на изчислителния процес ще преминаваме от един адрес на съседен.
Като пример нека разгледаме достъпа до елементите от един двумерен масив (матрица). Компилаторът разполага елементите от матрицата в паметта ред по ред. В програмния текст по-долу за събиране на две матрици този факт е пренебрегнат и това води до скокове в паметта през цял ред:
for (col = 0;
col < size; col++)
for (row = 0;
row < size; row++)
x[row][col] = y[row][col] + z[row][col];
Затова
променяме
реда на
циклите от col, row
на row, col:
for (col = 0;
row < size; row++)
for (col = 0;
col < size; col++)
x[row][col] = y[row][col] + z[row][col] ;
В зависимост от големината на матрицата оптимизацията може да ускори изпълнението до няколко пъти.
Вторият пример се касае до пространствената локалност на програмните функции. Пространствената локалност може лесно да бъде нарушена при извикването на отделни малки функции, но все пак не бива да се забравя и факта, че функциите правят кода по-прегледен и лесен за поддръжка. За щастие много Cи компилатори поддържат така нареченото вграждане или "function inlining". То се активира с ключовата дума "inline", която указва на компилатора да вгради кода на функцията при всяко обръщение към нея. Ето една малка функция, която си струва да вградим:
inline double radius_of( Node& node )
{
return sqrt( node.x*node.x + node.y*node.y + node.z*node.z );
}
За повече информация относно вграждането е добре да се прочете документацията към компилатора, защото "inline" не е част от ANSI Cи. Понякога е нужно допълнително активиране на вграждането със специална командна опция при компилирането.
Разбира се има и случаи, когато принципите на временната и пространствена локалност трябва да се приложат комбинирано. При комбинираното им използване обаче могат да възникнат и противоречия. С по-внимателен анализ и малко експериментиране може да стигнем лесно до компромис. Ето една често срещана ситуация, където двата принципа се разглеждат едновременно. Става въпрос за умножението на две матрици. Тук трябва да следим както последователното преминаване през елементите на матрицата, така и тяхното повторно използване.
for (i = 0;
i < size; i++)
for (j = 0; j < size; j++)
for (k = 0; k < size; k++)
x[i][j] = x[i][j] + y[i][k] * z[k][j] ;
На пръв поглед подредбата изглежда логична, но ако променим реда на циклите по k, j, i, на една работна станция с обем от 1[MiB] L2 кеш памет и size=500, се отчита ускорение от близо два пъти.
Допълнително
усъвършенстване
Онези от вас, които са склонни да потърсят по-изтънчени рецепти по пътя на оптимизацията на програмите, работещи върху системи с развита кеш система, предлагаме следните по-усложнени решения:
Много от модерните микропроцесорни архитектури предлагат специфични машинни команди за манипулиране на кеша. Така например в PowerPC са включени пет такива инструкции:
·
data cache
block flush ;
·
data cache
block store ;
·
data cache
block touch for store ;
·
data cache
block set to zero.
Тези команди обаче са риск за преносимостта, дори между PowerPC платформи, ползващи различни по големина кеш-блокове.
Съществуват експериментални приложения, които комбинират компилатора и така наречения профилатор или "profiler". Процедира се по следния начин: При компилирането на програмата в нея се вкарва допълнителен код, след което програмата се стартира. Допълнителният код следи по какъв начин програмата използва кеш паметта. На базата на резултатите се прави план за оптимизация, след което програмата се компилира за втори и последен път без допълнителния програмен код.
Интересно решение е и кешовият симулатор CProf, създаден в Duke University, USA. Той симулира работата на кеш паметта на UltraSPARC процесор и може да се използва за разпознаване на критични участъци в дадена Cи програма. За съжаление симулаторът не се предлага като свободен софтуер.
Оптимизацията на софтуера цели повишаване на неговото бързодействие. Познаването на логическата структура на процесора, в това число на конвейерите, позволява да се изгради ясна стратегия за оптимизация на програмния код. Приемствеността в развитието архитектурата на даден процесор е предпоставка за общи оптимизационни механизми. В същото време разликите в архитектурата и специфичните детайли в конвейерите, кеш системата и използваните от нея алгоритми предполагат индивидуални правила за оптимизация. Като пример ще изброим някои от ефектите във фамилията Intel. На първо място ще обърнем внимание на последователността от употребени в командите методи за адресиране. Съществуват последователности, при които поради особености в адресиращото устройство се явяват допълнителни тактове задръжка. Това се отнася най-вече за индексните адресации. Такива тактове се въвеждат и при изпълнение на команди, които генерират неявно адрес, като команди за запис и четене в стека, както и команди за преход и връщане от подпрограма.
Заради мултиплексирането на части от регистри (при работа с различни формати на данни в разрядната мрежа) също се явяват тактове задръжка. Например, за процесорите Intel се твърди, че при четене на 32-битово съдържание на регистър след запис в същия на 16- или 8-битова стойност могат да се явят 7 и повече тактове на закъснение.
Изравняването на кода и данните е специфичен подход, свързан със структурата на кеша. Тук в началото вече беше споменато за това. Що се отнася до кода на програмата, командите се извличат от L1 кеша на порции от по 32 байта с изравняване по адресната граница на 16 байта, т.е. свързано е с двата структурни масива на кеша. Следователно изравняването на кода има пряко влияние върху производителността при извличане.
Твърди се, че неизравнен достъп до данновия L1 кеш или до основната памет може да коства 10 и повече такта. Ето защо тук се препоръчва спазването на следните правила:
· 2 байтов операнд следва изцяло да се съдържа в изравнена 4 байтова дума. Това означава, че при разслоено адресиране (вижте фигура 6.2.4), младшите цифри на началния адрес на операнда могат да бъдат 0, 1, 2, но не и 3, т.е. разположението на този 2 байтов операнд може да изглежда по следния начин:
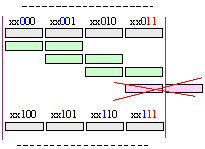
· 4 байтовите операнди трябва да бъдат изравнени на 4 байтова адресна граница, т.е. да се съдържат в един ред ;
· 8 байтовите операнди (числа във форма с ПЗ, ММХ операнди и др.) трябва да бъдат изравнени на 8 байтова адресна граница, т.е. да се съдържат изцяло в 2 реда.
Казаното току що ще се променя като правило, тъй като сме свидетели на променящи се структури, ширини на шини. Читателят следва да разглежда тези правила като специфични за всеки отделен процесор.
Сложната структура на машинната команда в процесорите също е причина за закъснения. Големият брой префикси удължават командата забавя нейната модификация и последващо декодиране. Особено не се препоръчва те да се употребяват към команди, които по принцип задържат конвейерите.
Предсказването на алгоритмичните преходи е нещо много съществено за оптимизиране на изчислителния процес. По този въпрос в структурата на процесорите са взети много сериозни архитектурни решения, които вече изяснихме. Все пак тук може да се каже още нещо:
· С цел оптимизация на програмите се препоръчва да се намалят и при възможност даже да се отстранят преходите ;
· Не се препоръчват прекалено кратки цикли – същите могат да се програмират буквално ;
· Не се препоръчва уплътняване на кодовия сегмент чрез разполагане на данни в него.
Друг полезен подход е планирането на командите и по-точно тяхната непосредствена последователност. Планирането като дейност се налага благодарение на суперскаларността, т.е. на няколкото паралелно работещи конвейера в съвременните процесори. Насищането на операционната част на процесора с функционални устройства и появяващите се в резултат на това нови възможности вече разглеждахме (вижте пункт 3.8.4). Основното явление е възможността за паралелно изпълнение на няколко машинни команди. За реализация на паралелното изпълнение на иначе последователно записани в програмата машинни команди е необходимо да се установи, че между тях няма взаимозависимости, които да препятстват това. За всеки конкретен процесор могат да се формулират достатъчно точно правила за комбиниране и подреждане на машинните команди така, че това да доведе до много висок процент използваемост на суперскаларността. В процесори, където има 2 изпълнителни конвейера например, се формулират правила за така нареченото сдвояване на команди. Ние няма да се спираме подробно тук на тези правила, тъй като те са твърде конкретни за всеки процесор, а тази конкретика не променя принципната възможност, за която вече говорихме.
Вероятно това не са единствените препоръки, които могат да бъдат предложени на стремящите се към перфектност читатели. Авторът с благодарност и удоволствие би добавил тук ваши мнения, съвети, примери и изводи, които сте направили по темата.
Следващият
раздел е
6.4. Концепция за виртуална памет